pi0.5: A Vision-Language-Action Model with Open-World Generalization
Overview
pi0.5 is the successor to pi0, developed by Physical Intelligence, and represents the first VLA model capable of performing 10-15 minute long-horizon tasks in previously unseen real homes. The key advance is a comprehensive co-training framework that integrates six heterogeneous data sources: mobile manipulator data (MM), multi-environment non-mobile robot data (ME), cross-embodiment lab data (CE), high-level semantic subtask prediction examples (HL), web-scale vision-language data (WD), and verbal instructions (VI). This diverse training mixture enables the model to generalize to open-world environments -- homes it has never seen, with novel objects, layouts, and task requirements.
The model introduces a hierarchical architecture with two levels: a high-level semantic module that predicts subtask decompositions from language instructions and visual context, and a low-level action module that generates motor commands via flow matching. This hierarchy allows the model to reason about multi-step task structure (e.g., "clean the kitchen" decomposes into subtasks like "pick up the plate", "place in dishwasher") while maintaining the precise continuous control needed for physical manipulation.
Key Contributions
- Open-world generalization: First VLA deployed in unseen real homes performing complex household tasks (organizing, bed-making, cleaning) lasting 10-15 minutes -- a major step beyond lab demonstrations
- Hierarchical VLA architecture: Combines high-level semantic subtask prediction with low-level flow matching action generation, enabling long-horizon task execution through natural language decomposition
- Six-source co-training: Integrates six heterogeneous data types -- mobile manipulator (MM), multi-environment non-mobile robot (ME), cross-embodiment lab (CE), high-level semantic subtask examples (HL), web vision-language data (WD), and verbal instructions (VI) -- each contributing distinct capabilities
- Scaling analysis: Demonstrates performance scaling with training environment diversity, providing empirical evidence for the data-scaling hypothesis in robot learning
Architecture / Method
┌──────────┐ ┌──────────────────────┐
│ Camera │ │ "clean the kitchen" │
│ Images │ └──────────┬───────────┘
└────┬─────┘ │
└──────────┬────────┘
▼
┌───────────────────────────────────┐
│ VLM Backbone │
│ (shared vision-language encoder)│
└───────────┬───────────────────────┘
│
▼
┌───────────────────────────────────┐
│ High-Level Semantic Module │
│ (subtask decomposition) │
│ │
│ "pick up plate" ──► "place in │
│ dishwasher" ──► "wipe counter" │
└───────────┬───────────────────────┘
│ subtask language commands
▼
┌───────────────────────────────────┐
│ Low-Level Action Module │
│ (flow matching, per subtask) │
│ │
│ Attention mask controls │
│ info flow between levels │
└───────────┬───────────────────────┘
│
▼
┌───────────────────────────────────┐
│ Mobile Manipulator Actions │
│ (dual 6-DOF arms + holo. base) │
└───────────────────────────────────┘
Co-training data sources (6 types):
[MM: Mobile Manip.] [ME: Multi-Env.] [CE: Cross-Embod.]
[HL: Semantic HL] [WD: Web Data] [VI: Verbal Instr.]
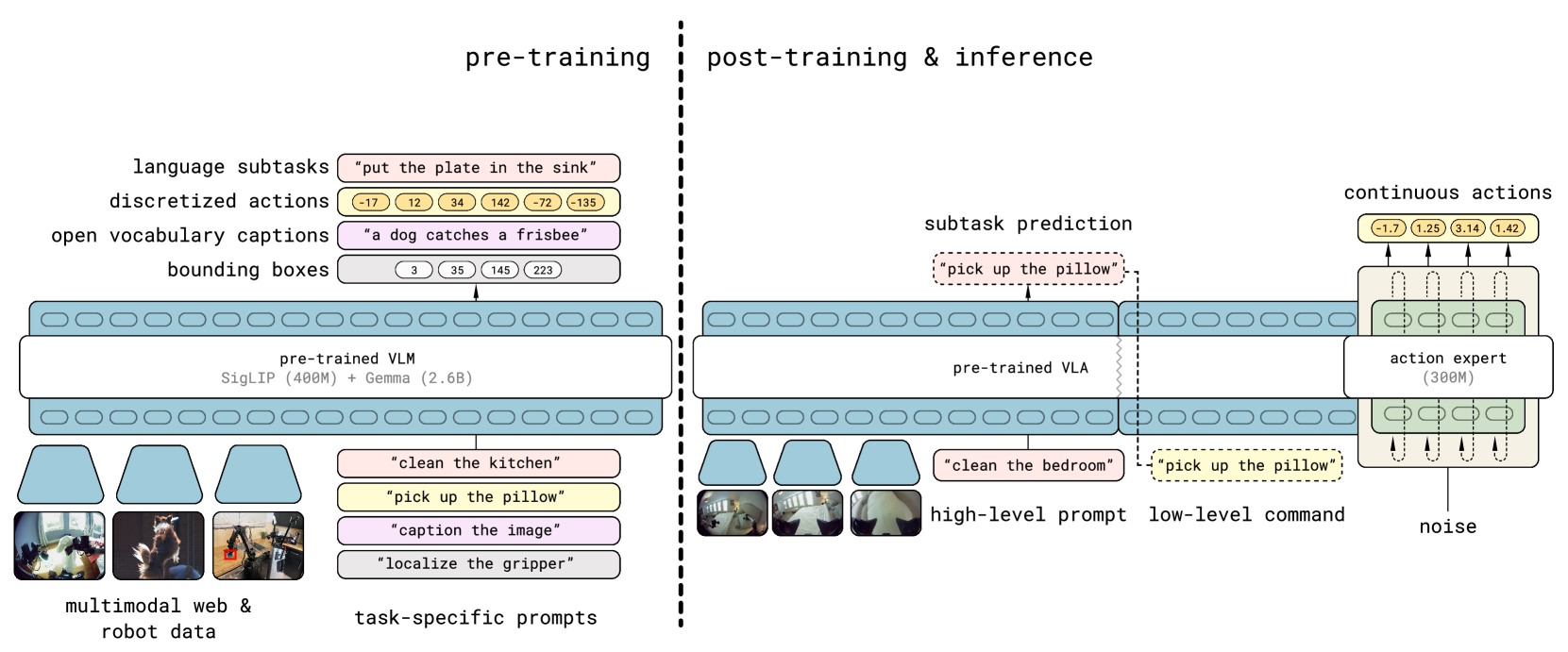
pi0.5 extends the pi0 architecture with a hierarchical design. The high-level module processes the current visual observation and language instruction to predict a sequence of semantic subtasks (expressed in natural language). The low-level module then executes each subtask using flow matching for continuous action generation. An attention masking scheme controls information flow between the two levels.
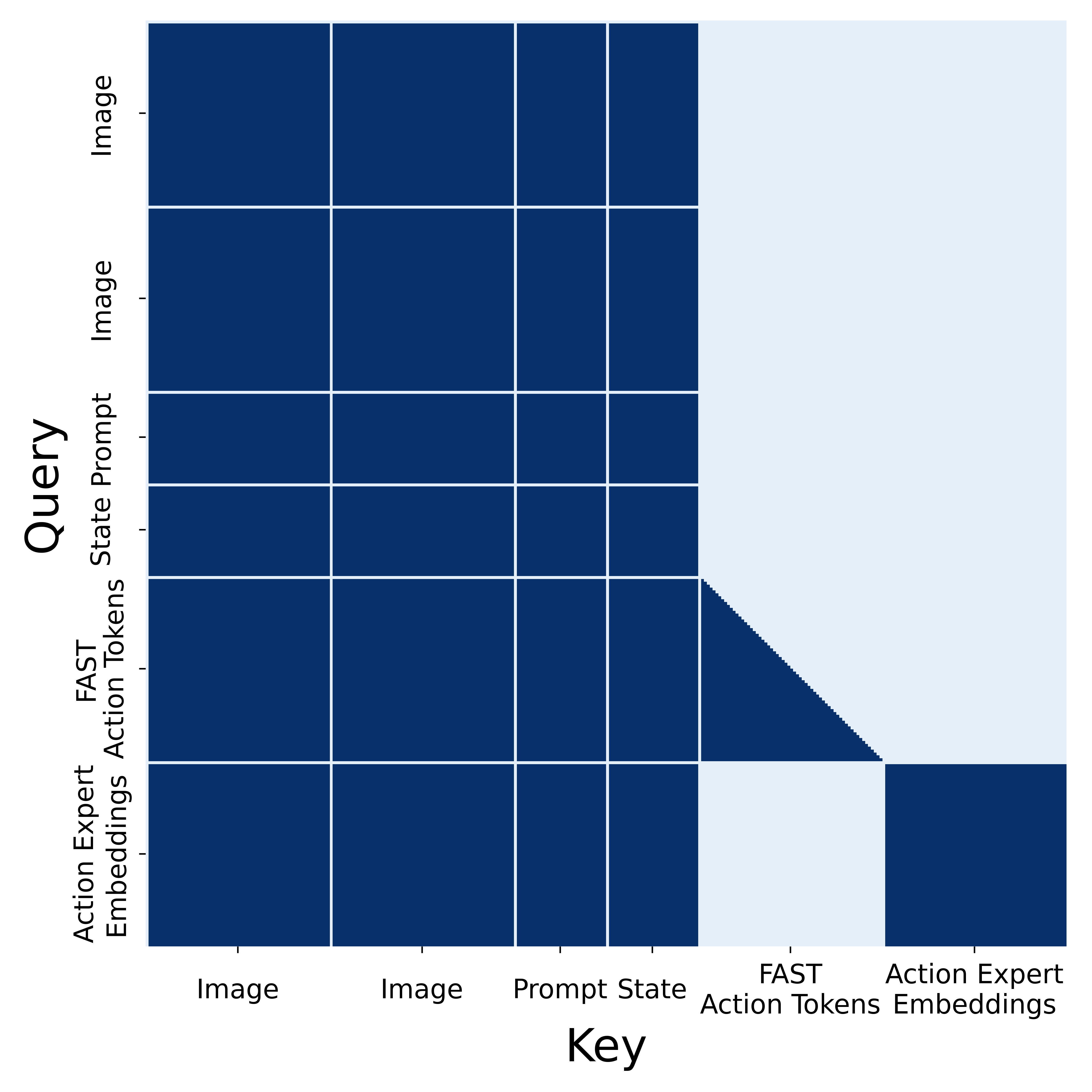
The co-training framework is central to the model's generalization. Each of the six data sources contributes differently: mobile manipulator (MM) data provides direct on-platform experience; multi-environment non-mobile robot (ME) data broadens environmental diversity; cross-embodiment lab (CE) data enables motor skill transfer; high-level semantic subtask (HL) examples teach task decomposition; web data (WD) provides semantic world knowledge (object categories, spatial relationships, common sense); and verbal instructions (VI) from human supervisors teach language-grounded task understanding. The architecture also incorporates the FAST tokenizer for action compression and tokenization in the low-level action module.
The hardware platform is a mobile manipulator with dual 6-DOF arms and a holonomic base, enabling the model to navigate homes while performing bimanual manipulation tasks.
Results
| Evaluation Setting | Key Finding |
|---|---|
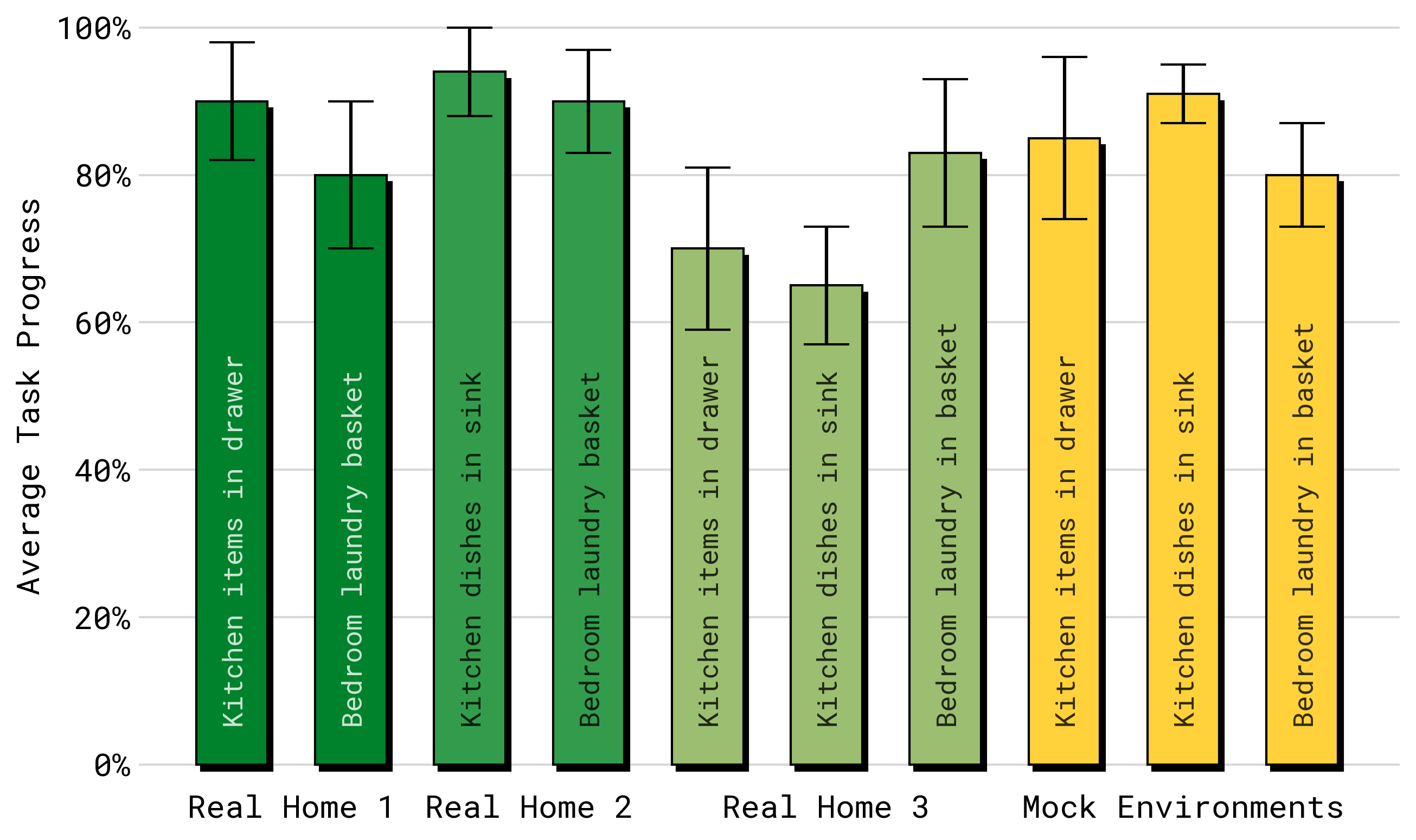
| Mock environments | Strong performance on trained task categories |
| Novel real homes | Successful generalization to unseen layouts, objects, and kitchens |
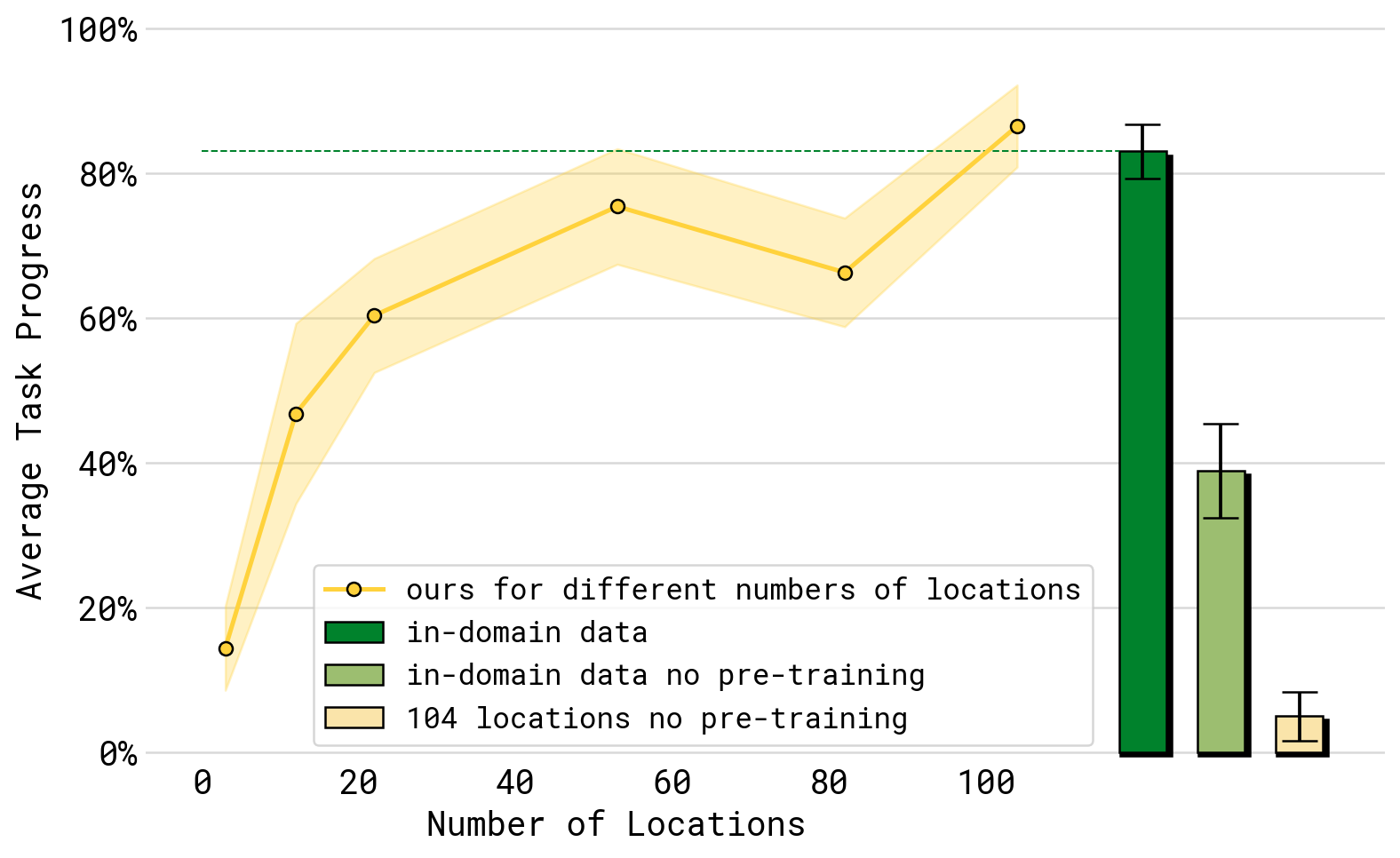
| Environment scaling | Performance improves monotonically with training environment diversity |
| Ablation: web data | Removing web data degrades semantic understanding and novel object handling |
| Ablation: cross-embodiment | Removing cross-embodiment data reduces motor skill quality |
| Long-horizon tasks | 10-15 minute multi-step tasks executed successfully in open-world settings |
- Performance scales with the number and diversity of training environments, supporting the hypothesis that environmental diversity is a key bottleneck for robot generalization
- Web data co-training contributes substantially to handling rare and novel objects in unseen homes
- The hierarchical architecture enables coherent execution of tasks requiring 20+ subtask transitions
- Cross-embodiment data provides meaningful motor skill transfer even between very different robot morphologies

Limitations
- Requires a specific mobile manipulator platform; generalization to other robot morphologies during deployment is not demonstrated
- The co-training data pipeline requires substantial curation effort, especially for verbal instruction alignment
- Performance still degrades in highly cluttered or visually ambiguous environments
- Evaluation methodology relies heavily on in-house testing; independent replication is limited by proprietary data and hardware
Connections
- Pi0 A Vision Language Action Flow Model For General Robot Control -- direct predecessor; pi0.5 adds hierarchical reasoning and open-world generalization
- Vision Language Action -- demonstrates the frontier of VLA capabilities in real-world deployment
- Robotics -- mobile manipulation in unstructured home environments
- Foundation Models -- co-training framework integrating multiple data modalities mirrors foundation model scaling strategies
- Rt 2 Vision Language Action Models Transfer Web Knowledge To Robotic Control -- RT-2 showed web knowledge transfer to robots; pi0.5 scales this with six heterogeneous data sources