RT-H: Action Hierarchies Using Language
Overview
RT-H (Robot Transformer with Action Hierarchies) introduces a hierarchical approach to multi-task robot control that uses natural language as an intermediate representation between high-level task instructions and low-level robot actions. The core problem it addresses is that flat policy architectures like RT-1 and RT-2 struggle with data sharing across semantically diverse manipulation tasks -- a model trained on "pick up the apple" and "open the drawer" cannot easily share low-level motion primitives because the tasks look completely different at the instruction level. RT-H is implemented on top of PaLI-X 55B (not RT-2); the two policies (high-level and low-level) are both expressed as prompted queries to this single VLM.
The key insight is that many diverse tasks share common fine-grained motions (e.g., "move arm forward", "close gripper") even when their high-level descriptions differ entirely. RT-H introduces "language motions" -- short natural language descriptions of immediate robot movements -- as a learned intermediate layer. A high-level policy maps observations and task instructions to language motions, and a low-level policy maps observations, tasks, and the predicted language motion to robot actions. Critically, these language motions are not rigid primitives; they are contextual and flexible, adapting execution based on the visual scene and task context.
RT-H achieves a 15% higher average success rate compared to RT-2 on real robot evaluations, with 20% lower action prediction error in offline metrics. The framework also enables an intuitive human intervention mechanism: correcting robot behavior at the language motion level (e.g., changing "move left" to "move right") is far more sample-efficient than correcting low-level actions, with just 30 correction episodes improving success from 40% to 63%. The model also generalizes better to novel objects, achieving 65% success vs. 55% for the baseline.
Key Contributions
- Language motions as intermediate representation: Introduces fine-grained natural language descriptions of robot movements as a learned bridge between task instructions and low-level actions, enabling better data sharing across diverse tasks
- Hierarchical two-phase policy: Decomposes robot control into a high-level policy (observation + task -> language motion) and a low-level policy (observation + task + language motion -> action), both implemented as VLM queries
- Contextual flexibility: Language motions are not rigid skill primitives -- the same motion description adapts its execution based on visual context and task, avoiding the brittleness of traditional skill libraries
- Sample-efficient human intervention: Enables humans to correct robot behavior at the semantic language motion level rather than at low-level action dimensions, requiring far fewer correction demonstrations (30 episodes for significant improvement)
- Improved generalization: Demonstrates better transfer to novel objects and task variations through the shared language motion vocabulary
Architecture / Method
┌───────────────────────────────────────────────────────┐
│ RT-H Pipeline │
├───────────────────────────────────────────────────────┤
│ │
│ ┌──────────┐ ┌──────────────────┐ │
│ │ Camera │ │ Task Instruction │ │
│ │ Image │ │ "pick up apple" │ │
│ └────┬─────┘ └────────┬─────────┘ │
│ │ │ │
│ ▼ ▼ │
│ ┌────────────────────────────────┐ │
│ │ Phase 1: High-Level Policy │ │
│ │ (VLM forward pass) │ │
│ └──────────────┬─────────────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────────┐ │
│ │ Language Motion │ │
│ │ "move arm down │ │
│ │ toward apple" │ │
│ └─────────┬───────────┘ │
│ │ │
│ ┌─────────┴──────────────────────┐ │
│ │ Image + Task + Language Motion │ │
│ └─────────┬──────────────────────┘ │
│ ▼ │
│ ┌────────────────────────────────┐ │
│ │ Phase 2: Low-Level Policy │ │
│ │ (VLM forward pass) │ │
│ │ ──► Discretized Actions │ │
│ └──────────────┬─────────────────┘ │
│ │ │
│ ▼ │
│ ┌────────────┐ │
│ │ Robot Arm │ │
│ │ 7-DoF + grip│ │
│ └────────────┘ │
│ │
│ ┌─ Human Intervention ─────────────────────────┐ │
│ │ Correct at language motion level (30 episodes)│ │
│ └───────────────────────────────────────────────┘ │
└───────────────────────────────────────────────────────┘

RT-H is built on PaLI-X 55B (a ViT encoder + encoder-decoder transformer) and adds a hierarchical decomposition on top of this VLM. Both the high-level and low-level queries are trained within a single VLM, with the ViT encoder frozen during robot data co-training and action dimensions discretized into 256 bins. The system operates in two phases:
Phase 1 -- High-level policy (Language Motion Prediction): Given the current camera observation and the task instruction (e.g., "pick up the apple"), the VLM predicts a language motion -- a short natural language description of the immediate robot movement (e.g., "move arm down toward the apple"). This is generated as free-form text by the VLM.
Phase 2 -- Low-level policy (Action Generation): The same single VLM receives the camera observation, the task instruction, AND the previously predicted language motion (z_{t-1}), then outputs discretized robot actions (256-bin discretization). The language motion serves as an additional conditioning signal that disambiguates what the robot should do next.

The language motions are learned from demonstrations that have been automatically annotated by analyzing end-effector pose changes across position, orientation, gripper status, and base movement dimensions -- over 2,500 unique language motions are extracted this way without manual labeling. The training data is the Diverse+Kitchen (D+K) dataset of ~100K demonstrations across 24+ semantic task categories. The training mixture uses 50% original VLM pre-training data and 25% each for the language motion query and action query from robot data, with the ViT encoder frozen throughout. At inference, the predicted language motion provides an interpretable intermediate reasoning step that improves action quality.
At inference, the two queries run asynchronously: the high-level policy predicts z_t (the next language motion) one step ahead, while the low-level policy uses z_{t-1} (the previously predicted motion) to generate the current action a_t. This pipelining maintains near-identical inference latency to flat models like RT-2, avoiding the cost of sequential double-pass inference. The hierarchical structure enables the low-level policy to share knowledge across tasks that have different high-level instructions but similar motion patterns.
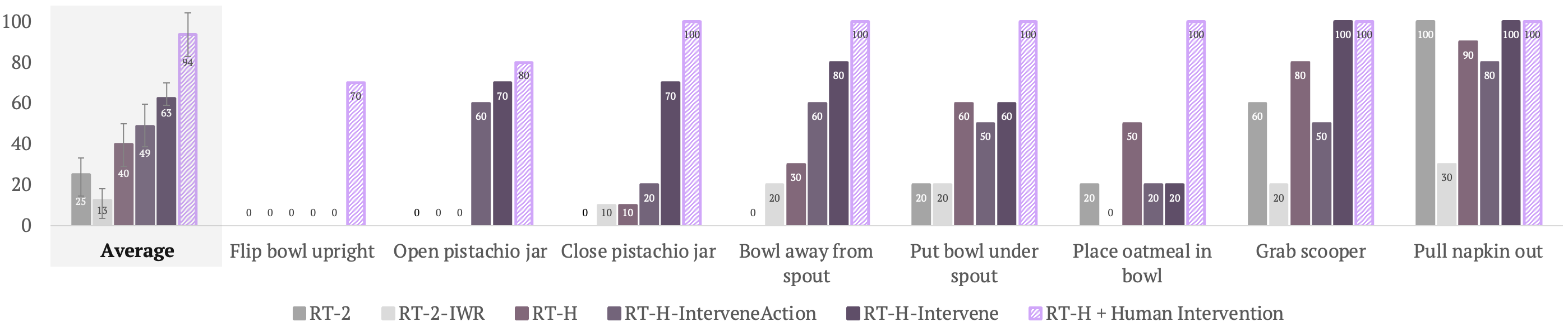
Human intervention mechanism: When the robot fails or behaves suboptimally, a human can observe the predicted language motion and provide a correction at that level (e.g., "you should move right, not left"), bypassing πₕ and feeding the corrected language motion directly into πₗ. Only the language motion query (πₕ) is updated during correction learning -- the action query (πₗ) remains unchanged -- enabling sample-efficient learning. Correction data is co-trained with the original dataset at 50x upweighting. As few as 30 correction episodes per task significantly improve performance.
Results
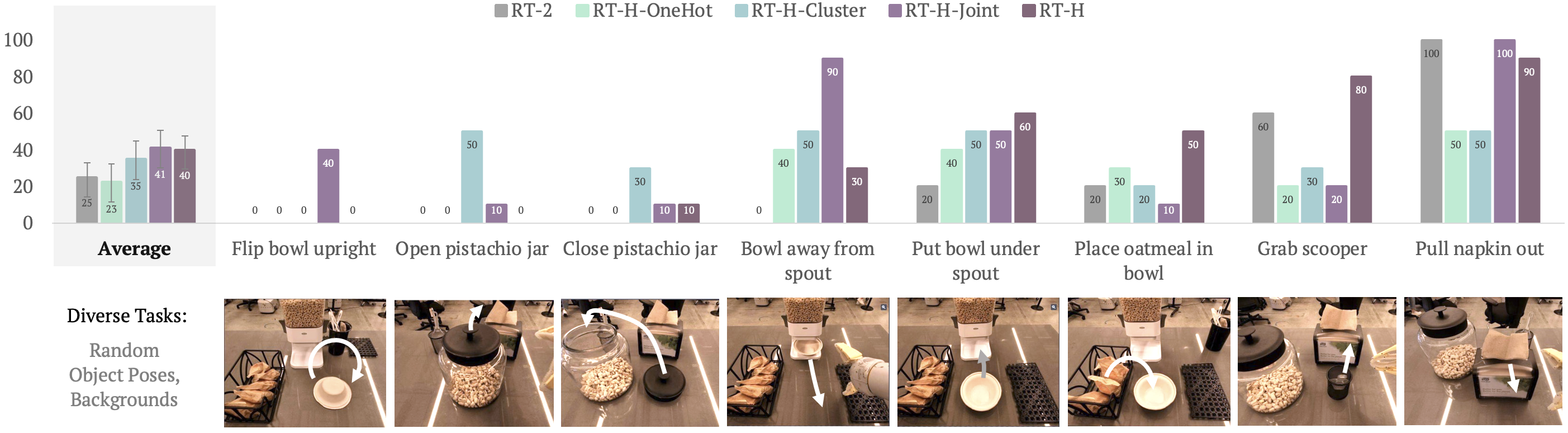
| Method | Average Success Rate | Action Prediction Error | Novel Object Success |
|---|---|---|---|
| RT-H | +15% vs RT-2 | -20% vs RT-2 | 65% |
| RT-2 (baseline) | baseline | baseline | 55% |
Key experimental findings:
- 15% higher success rate on average across real robot manipulation tasks compared to RT-2, demonstrating the benefit of the hierarchical language motion decomposition
- 20% lower offline action prediction error, indicating that the intermediate language motion representation provides a useful inductive bias for action prediction
- Generalization to novel objects: 65% success rate on tasks involving objects not seen during training, compared to 55% for the flat RT-2 baseline
- Sample-efficient correction: Training on just 30 human correction episodes at the language motion level improves success rate from 40% to 63%, demonstrating the practical value of the interpretable intermediate layer

Limitations & Open Questions
- Language motion annotation: The approach requires language motion annotations for training data. RT-H addresses this via automated extraction from proprioception data (analyzing end-effector pose changes), but the coverage and quality of the resulting vocabulary (2,500+ motions) depends on the diversity of the demonstration dataset
- Asynchronous inference complexity: The asynchronous querying scheme (predicting z_t one step ahead and using z_{t-1} for actions) maintains low latency but introduces a one-step lag in language motion conditioning; the language motion used for action generation is always one observation behind
- Language motion vocabulary: The expressiveness and granularity of language motions is not formally characterized -- it is unclear what the optimal level of description is (e.g., "move arm" vs. "move arm 5cm forward and 2cm down")
- Scale of evaluation: The evaluation is on Google's robot manipulation setup; transferability of the hierarchical language motion idea to other embodiments and domains (e.g., humanoids, driving) is not demonstrated
- Comparison to non-language hierarchies: The paper does not extensively compare against hierarchical policies that use learned latent skills rather than language as the intermediate representation
Connections
Related papers in the wiki: - Rt 1 Robotics Transformer For Real World Control At Scale — foundational robot transformer in the RT lineage; RT-H uses the same robot and task setup - Rt 2 Vision Language Action Models Transfer Web Knowledge To Robotic Control — RT-2 is the primary baseline; RT-H uses PaLI-X 55B (same family) but adds hierarchical language motions - Palm E An Embodied Multimodal Language Model — provides the VLM backbone paradigm that RT-H leverages - Openvla An Open Source Vision Language Action Model — open-source VLA that could benefit from RT-H's hierarchical approach - Ecot Embodied Chain Of Thought Reasoning For Vision Language Action Models — similar idea of using language as intermediate reasoning for VLAs, but via chain-of-thought rather than motion descriptions - Pi05 A Vision Language Action Model With Open World Generalization — pi0.5 uses a hierarchical VLA design conceptually similar to RT-H's two-level decomposition - Vision Language Action — RT-H advances the VLA paradigm with hierarchical action decomposition - Robotics — broader context of the robotics VLA lineage