pi*0.6: A VLA That Learns From Experience
Overview
pi0.6 extends the pi0/pi0.5/pi0.6 VLA family with the ability to learn from autonomous deployment experience using reinforcement learning. While prior models learn primarily from human demonstrations (imitation learning), pi0.6 introduces RECAP (RL with Experience and Corrections via Advantage-conditioned Policies) -- an iterated offline RL method that enables the VLA to improve from its own successes and failures during real-world operation, as well as from human intervention corrections. pi*0.6 is itself an adaptation of the pi0.6 model, incorporating a larger VLM backbone (Gemma 3 4B) and increased action expert size (860M parameters), with the added ability to condition on a binarized advantage indicator. This is a critical capability gap: imitation learning is bounded by demonstration quality and cannot discover better strategies through trial and error.
RECAP substantially improved task throughput on difficult real-world tasks: espresso preparation doubled (~15→30 successes/hr), box assembly approximately doubled, and diverse laundry folding improved ~60% (~5→8 successes/hr). Failure rates were reduced by approximately 2x across tasks. The method works as offline RL, making it compatible with large pre-trained VLA models where on-policy RL would be prohibitively expensive. pi0.6 represents a significant step toward continuously self-improving robots that get better through deployment rather than requiring ever-more human demonstrations.
Key Contributions
- RECAP: iterated offline RL for VLAs: An iterated offline reinforcement learning framework designed specifically for large pre-trained VLA models, using binary advantage-conditioned policies (text tokens "Advantage: positive/negative") to learn from mixed-quality experience data
- Learning from deployment: The model improves from autonomous experience (successes and failures), human corrections (interventions during deployment), and reward signals -- three heterogeneous data sources integrated into a single learning framework
- Large throughput gains: Espresso preparation and box assembly approximately doubled in successes/hr; diverse laundry folding improved ~60%; demonstrating practical value beyond benchmark improvements
- ~2x failure reduction: Halved failure rates on evaluated tasks, showing that RL from experience directly addresses common failure modes that imitation learning cannot fix
- Flow matching + RL integration: Demonstrates that flow matching action generation (as in pi0) is compatible with offline RL, maintaining the continuous action advantages while enabling policy improvement
Architecture / Method
RECAP: Iterative Self-Improvement Loop
───────────────────────────────────────
┌──────────────────────┐
│ VLA Policy (pi*0.6) │◄──────────────────────────┐
│ (flow matching) │ │
└──────────┬───────────┘ │
│ deploy │
▼ │
┌──────────────────────┐ │
│ Real-World Rollouts │ │
│ ┌────────────────┐ │ │
│ │ Successes │ │ │
│ │ Failures │ │ │
│ │ Human Corrects │ │ │
│ └────────┬───────┘ │ │
└───────────┼──────────┘ │
│ + reward labels │
▼ │
┌──────────────────────┐ │
│ Value Function │ │
│ Training │ │
│ V(s) ──► A(s,a) │ advantage estimates │
└──────────┬───────────┘ │
│ │
▼ │
┌──────────────────────┐ updated policy │
│ Advantage-Cond. ├───────────────────────────┘
│ Policy Fine-tuning │
│ (offline RL) │
└──────────────────────┘

pi0.6 uses a Gemma 3 4B language backbone with an 860M parameter action expert and flow-matching for continuous action generation. A separate 670M-parameter distributional value function shares the VLA architecture and predicts steps-to-completion to derive advantage signals.
RECAP operates through iterative cycles:
-
Deployment and data collection: The VLA policy is deployed on real robots, collecting trajectories that include autonomous successes, autonomous failures, and human-corrected interventions. Each trajectory is labeled with reward/outcome information.
-
Value function training: A distributional value function (670M parameters, sharing the VLA architecture) is trained on multi-task demonstration data to predict steps-to-completion. It is then used to derive binary advantage indicators for each state-action pair in the deployment data.
-
Advantage-conditioned policy training: The VLA policy is fine-tuned with binary advantage conditioning: the model receives a text token ("Advantage: positive" or "Advantage: negative") derived from the value function estimates, biasing generation toward actions that led to better outcomes. This is an offline RL approach -- no additional environment interaction is needed during training.
-
Iteration: The improved policy is deployed, collecting new (hopefully better) experience, and the cycle repeats.
The method is specifically designed for offline RL because on-policy methods (PPO, SAC) would require running the full VLA model in a simulator or real environment during training -- prohibitively expensive for billion-parameter models. RECAP instead extracts learning signal from previously collected deployment data.
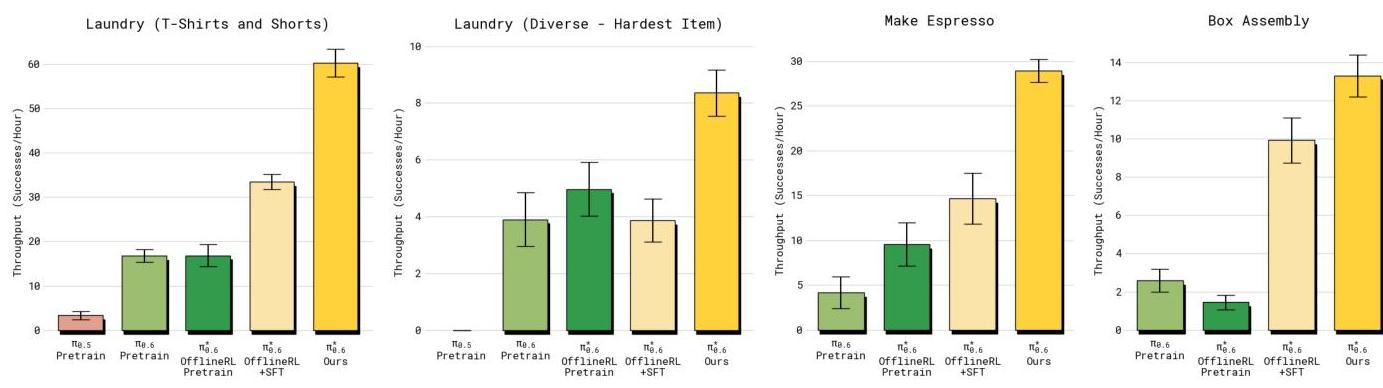
Results
| Task | Metric | pi0 baseline | pi0.6 (RECAP) | Improvement |
|---|---|---|---|---|
| Laundry folding (diverse) | Successes/hr | ~5 | ~8 | ~60% increase |
| Espresso preparation | Successes/hr | ~15 | ~30 | ~2x (100% increase) |
| Box assembly | Completions/hr | Baseline | ~2x baseline | ~2x increase |
| All tasks | Failure rate | Baseline | ~50% of baseline | ~2x reduction |
- Throughput gains: Doubled on espresso preparation (~15→30/hr); diverse laundry improved ~60% (~5→8/hr); box assembly also approximately doubled
- Halved failures: ~2x reduction in failure rates, showing RECAP specifically addresses failure modes that imitation learning misses
- Autonomous endurance: Espresso robot operated 13 hours without intervention; laundry folding ran autonomously for 2+ hours in novel environments
- Heterogeneous data integration: Successfully learns from three data types simultaneously (autonomous experience, human corrections, reward signals)
- Extended autonomous operation: The improved reliability enables longer uninterrupted autonomous deployment periods
- Iterative improvement: Performance improves across RECAP iterations, confirming the self-improvement loop works in practice
Limitations
- Requires a reward/outcome signal for each trajectory, which may be difficult to define for ambiguous or open-ended tasks
- The offline RL approach is sample-efficient but still requires substantial deployment data collection, which is slow and expensive in the real world
- Evaluation is limited to three tasks on Physical Intelligence's proprietary hardware; generalization of RECAP to other VLA architectures or embodiments is not demonstrated
- The value function estimation may be noisy with limited deployment data, potentially leading to suboptimal advantage conditioning
- No comparison with online RL methods or other offline RL algorithms (CQL, IQL); RECAP's relative advantage among RL approaches is unclear
Connections
- Pi0 A Vision Language Action Flow Model For General Robot Control -- pi*0.6 traces its lineage to pi0's flow matching VLA architecture
- Pi05 A Vision Language Action Model With Open World Generalization -- pi0.6 is a direct evolution of pi0.5 (via pi0.6); pi0.5 scales data diversity while pi0.6 adds RL-based self-improvement through RECAP
- Knowledge Insulating Vision Language Action Models -- knowledge insulation addresses VLM degradation during training; RECAP faces similar challenges when fine-tuning with RL
- Vision Language Action -- demonstrates that RL is viable for VLA improvement beyond imitation learning
- Robotics -- practical self-improvement for deployed robot systems