Knowledge Insulating Vision-Language-Action Models
Overview
This paper from Physical Intelligence identifies and addresses a critical problem in VLA training: gradient interference causes the pre-trained VLM backbone to degrade when action prediction modules are added and trained end-to-end. The authors introduce "knowledge insulation" -- a training methodology that uses strategic gradient flow control (stop-gradient on backbone attention keys/values), co-training with VLM objectives, and a three-part combined loss (L_VLM + L_FAST + L_FLOW) to preserve the VLM's semantic understanding while still learning effective action prediction. The result is a VLA that trains 7.5x faster, achieves 49% task success (vs. 34% for baselines), improves language following from 69% to 85%, and generalizes better to novel objects.
Built on PaliGemma (2B parameters) with a 300M parameter action expert, knowledge insulation is directly relevant to the pi0 family of models and addresses a fundamental tension in VLA design: the VLM's pre-trained representations are valuable for understanding, but naive end-to-end training corrupts them. The training objective combines three losses: a VLM co-training loss (L_VLM), a discrete action loss using the FAST tokenizer (L_FAST, DCT-based action compression), and a continuous flow-matching action loss (L_FLOW).
Key Contributions
- Identifies gradient interference in VLA training: Demonstrates that backpropagation from the action head degrades VLM representations, reducing both task performance and language understanding
- Knowledge insulation via stop-gradient on attention keys/values: Stop-gradient operators applied to the backbone's attention keys and values prevent continuous action expert gradients from corrupting pre-trained VLM representations, while still allowing information to flow forward
- Three-part combined loss (L_CO-VLA = L_VLM + L_FAST + L_FLOW): Co-training combines VLM objectives (captioning, VQA), a discrete FAST-tokenizer action loss for backbone adaptation, and a continuous flow-matching loss for real-time control
- Co-training with VLM objectives: Maintains VLM capabilities by continuing vision-language pre-training objectives alongside action prediction, preventing catastrophic forgetting
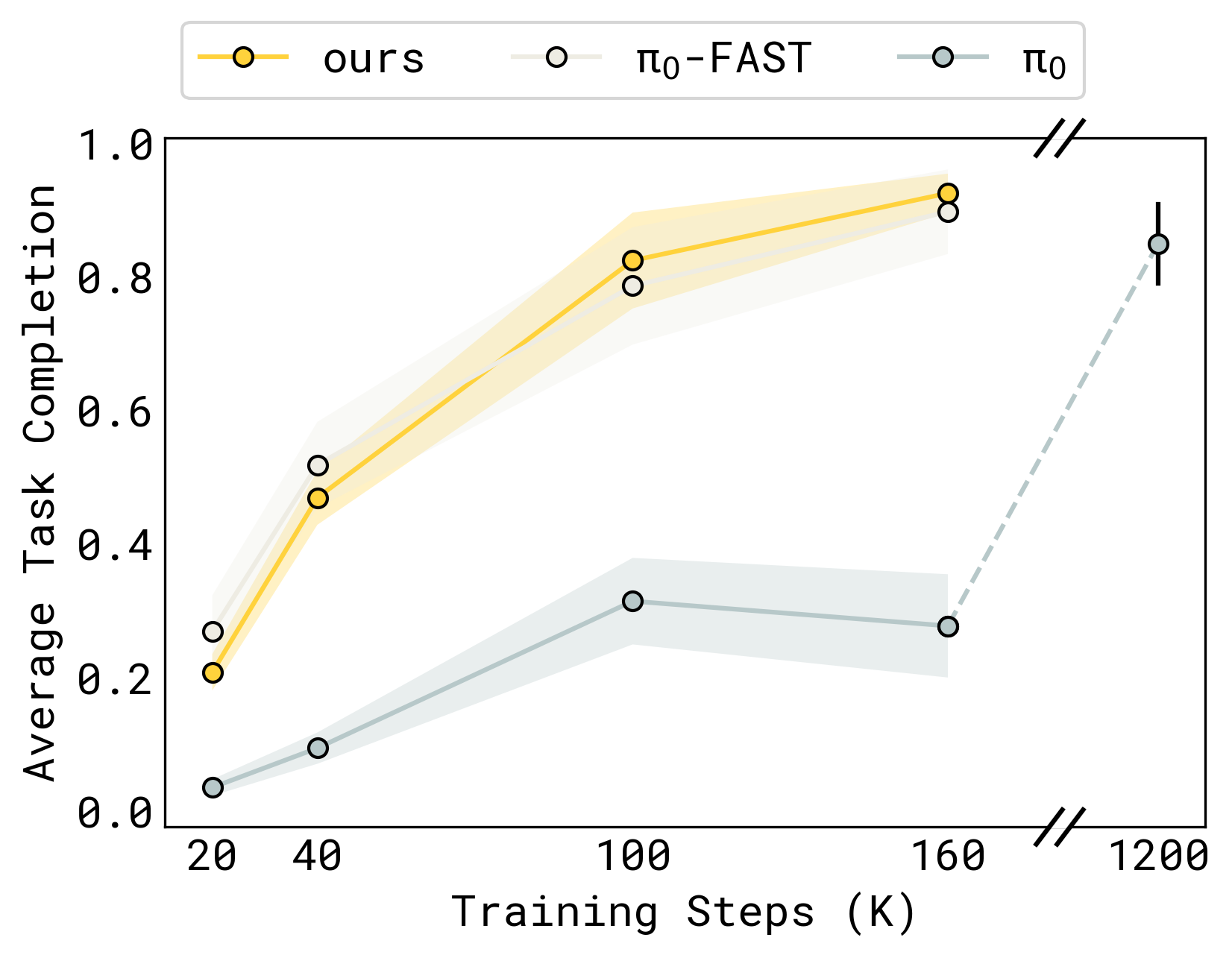
- 7.5x faster convergence: The insulated training recipe converges dramatically faster than standard end-to-end training
- Comprehensive ablation study: Extensive analysis of design choices including gradient insulation placement, co-training data mix, discrete tokenization strategy, and state representation formats
Architecture / Method
┌──────────────────────────────────────────────────────────┐
│ Knowledge Insulation Training │
│ │
│ ┌──────────────┐ │
│ │ Camera RGB │ │
│ └──────┬───────┘ │
│ ▼ │
│ ┌──────────────────────────────┐ │
│ │ PaliGemma VLM Backbone │ │
│ │ (2B params) │ │
│ │ ┌────────────────────────┐ │ │
│ │ │ Insulated Layers │ │ ◄── Stop-gradient │
│ │ │ (frozen to action grad)│ │ from action loss │
│ │ └────────────────────────┘ │ │
│ │ ┌────────────────────────┐ │ │
│ │ │ Adapted Layers │ │ ◄── Gradients from │
│ │ │ (VLM + FAST losses) │ │ VLM & FAST flow │
│ │ └────────────────────────┘ │ │
│ └──────────┬───────────────────┘ │
│ │ │
│ ┌───────┴──────────────┐ │
│ ▼ ▼ ▼ │
│ ┌──────────┐ ┌─────────┐ ┌─────────────────┐ │
│ │ VLM Head │ │ FAST │ │ Action Expert │ │
│ │(caption, │ │ Discrete│ │(flow matching, │ │
│ │ VQA) │ │ Actions │ │ 300M params) │ │
│ └────┬─────┘ └────┬────┘ └───────┬─────────┘ │
│ ▼ ▼ ▼ │
│ ┌──────────┐ ┌─────────┐ ┌─────────────────┐ │
│ │ L_VLM │ │ L_FAST │ │ L_FLOW │──stop-grad │
│ │(co-train)│ │(discrete│ │ (flow matching) │──X──► keys/│
│ └──────────┘ │ actions)│ └─────────────────┘ values │
│ └─────────┘ │
└──────────────────────────────────────────────────────────┘
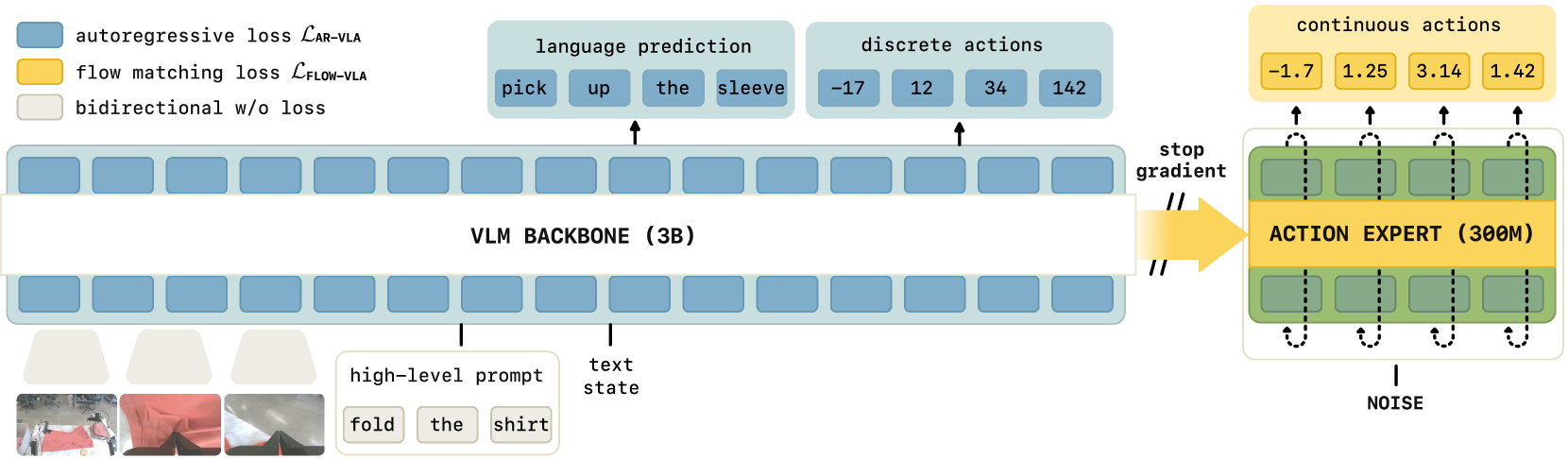
The architecture uses PaliGemma (2B parameters) as the VLM backbone and a 300M parameter transformer for continuous action prediction via flow matching. The key innovation is in the training methodology:
Stop-gradient operations: Gradients from the continuous action expert are blocked from flowing back into the VLM backbone by applying stop-gradient operators specifically to the backbone's attention keys and values. This means the action expert can attend to backbone features (information flows forward) but cannot corrupt them via backpropagation (gradients are blocked). The paper identifies this attention-level gradient control as the critical mechanism.
Co-training: The model is trained simultaneously on robot action prediction and VLM tasks (image captioning, visual QA). This multi-task objective keeps the VLM representations active and prevents them from drifting toward action-only features.
Discrete action co-training (FAST): In addition to the continuous flow-matching loss, the model trains on a discrete action prediction objective using FAST tokens (DCT-based compressed action representations). This discrete action loss adapts the VLM backbone to robotic control patterns while the gradient insulation prevents this from corrupting semantic knowledge. Discrete and continuous action tokens are prevented from cross-attending to each other via attention masking.
Results
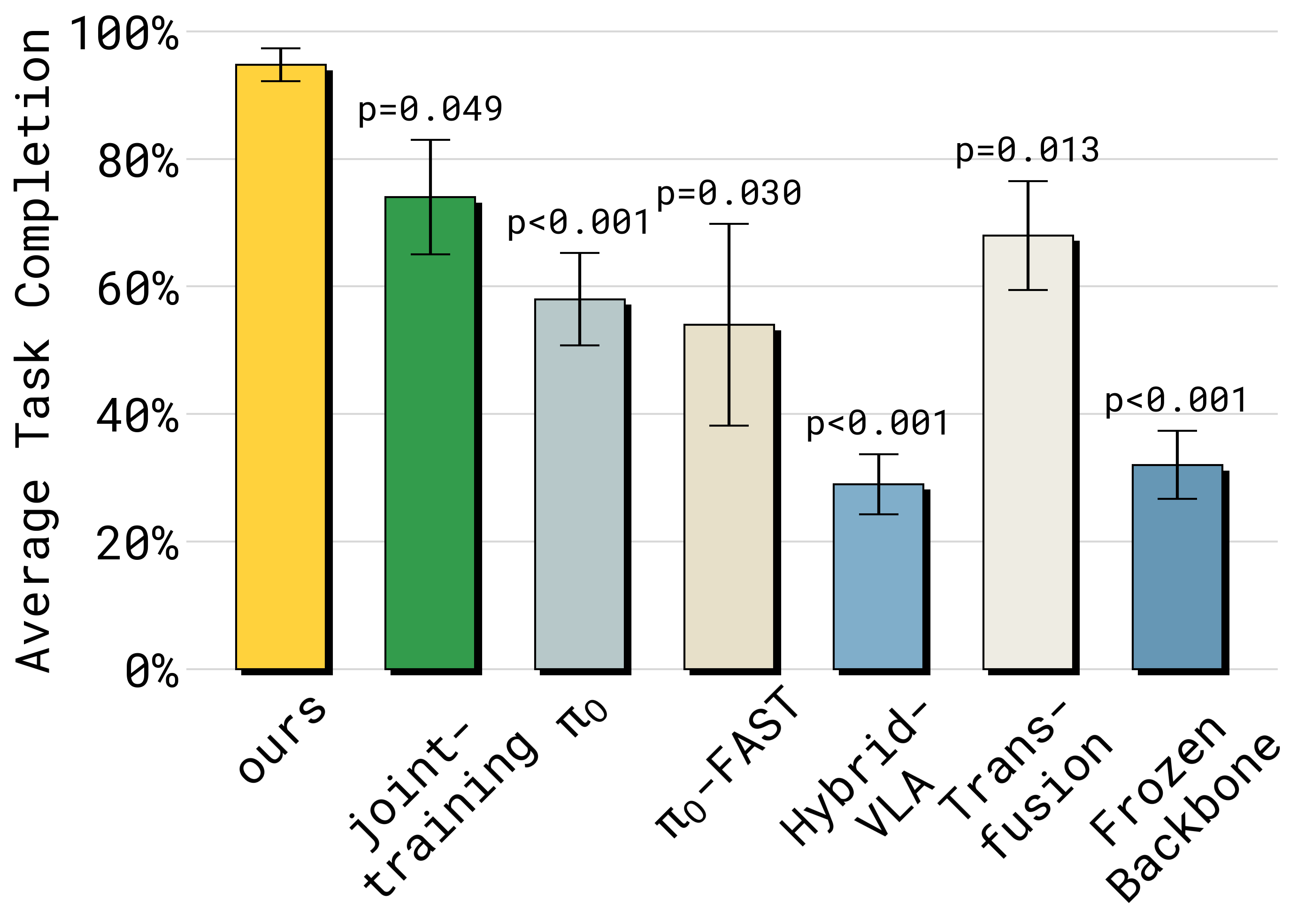
| Metric | Knowledge Insulation | Baseline (end-to-end) | Frozen VLM |
|---|---|---|---|
| Task success rate | 49% | 34% | Lower |
| Language following | 85% | 69% | High but action weak |
| Training steps to converge | 1x | 7.5x | 1x |
| Novel object generalization | Strong | Degraded | Moderate |
- 49% success vs. 34% for standard end-to-end training -- a 44% relative improvement
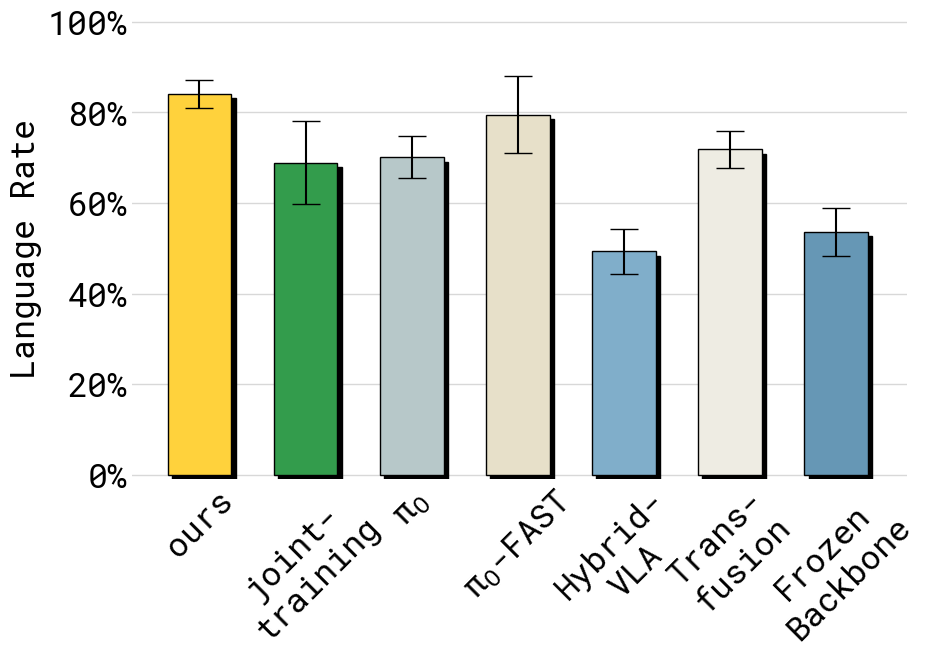
- 85% language following vs. 69% -- the insulated model correctly distinguishes language-specified targets far more often
- 7.5x fewer training steps to reach convergence, dramatically reducing compute requirements
- Novel object generalization improves because the VLM's pre-trained visual representations (trained on web-scale data) are preserved rather than overfit to training objects
- Co-training with VLM data is critical: without it, even stop-gradient alone shows partial degradation
- The frozen VLM baseline (no VLM fine-tuning at all) preserves language but produces worse actions, confirming that some VLM adaptation is needed -- insulation finds the right balance
Limitations
- The optimal stop-gradient placement is determined empirically and may vary across VLM architectures; no principled theory guides which layers to insulate
- Tested primarily on PaliGemma 2B; scaling behavior to larger VLMs (7B+) is not established
- The three-part training objective (L_VLM + L_FAST + L_FLOW) increases training-time complexity and data requirements (requires both VLM co-training data and robot data)
- The 49% absolute success rate, while significantly better than baselines, still leaves substantial room for improvement on the evaluation tasks
Connections
- Pi0 A Vision Language Action Flow Model For General Robot Control -- knowledge insulation directly addresses training challenges in the pi0 architecture family
- Pi05 A Vision Language Action Model With Open World Generalization -- pi0.5 uses co-training with web data; knowledge insulation provides the training methodology to do this without degradation
- Openvla An Open Source Vision Language Action Model -- OpenVLA fine-tunes the full VLM backbone; knowledge insulation suggests this may degrade pre-trained knowledge
- Vision Language Action -- addresses a fundamental training challenge for all VLA models
- Foundation Models -- knowledge preservation during fine-tuning is a general challenge for foundation models (related to catastrophic forgetting)