FAST: Efficient Action Tokenization for Vision-Language-Action Models
Overview
FAST (Frequency-space Action Sequence Tokenization) introduces a novel action tokenizer for VLA models that leverages signal processing to dramatically compress robot action sequences. Current VLA approaches use naive per-dimension binning to convert continuous actions into discrete tokens, which fails to capture temporal correlations in high-frequency robot control data and produces long token sequences that slow training and inference. FAST applies Discrete Cosine Transform (DCT) followed by Byte-Pair Encoding (BPE) to compress action chunks into far fewer tokens, achieving 2x-13x compression ratios depending on robot complexity.
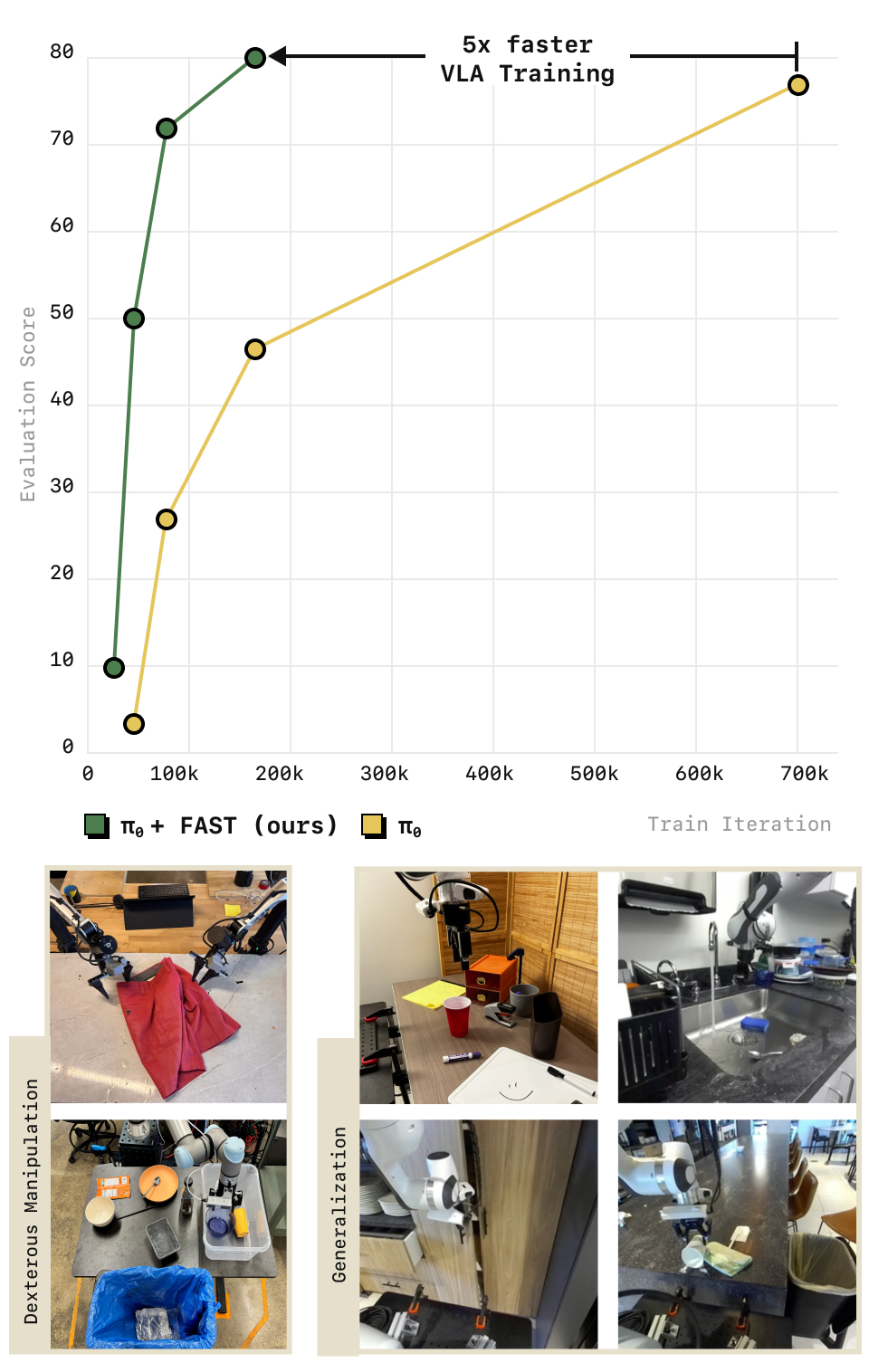
Developed by Physical Intelligence and UC Berkeley, FAST consistently outperforms naive tokenization across diverse manipulation tasks while enabling 5x faster training. The paper also introduces FAST+, a pre-trained universal tokenizer trained on 1M real robot action trajectories spanning multiple embodiments that can be applied zero-shot to new robots without re-training the tokenizer.
Key Contributions
- DCT + BPE action tokenization: Transforms continuous action sequences into frequency space via DCT, quantizes coefficients, then applies BPE compression -- achieving 2x-13x compression over naive binning
- 5x training speedup: Shorter token sequences mean fewer autoregressive steps, dramatically accelerating VLA training convergence
- FAST+ universal tokenizer: A pre-trained tokenizer trained on 1M real robot action trajectories, applicable across robot embodiments without re-fitting, enabling plug-and-play deployment
- Enables complex dexterous tasks: The compressed representation allows VLAs to learn high-DoF dexterous manipulation (e.g., shirt folding) that naive tokenization cannot handle due to sequence length constraints
Architecture / Method
┌─────────────────────────────────────────────────────────────────┐
│ FAST Tokenization Pipeline │
│ │
│ Raw Action Sequence (T timesteps x D dimensions) │
│ ┌─────────────────────────────────────────────┐ │
│ │ [a1_t1, a1_t2, ..., a1_tT] (dim 1) │ │
│ │ [a2_t1, a2_t2, ..., a2_tT] (dim 2) │ │
│ │ ... │ │
│ │ [aD_t1, aD_t2, ..., aD_tT] (dim D) │ │
│ └──────────────────────┬──────────────────────┘ │
│ ▼ │
│ Step 1: ┌──────────────────────────┐ │
│ │ Normalize (zero mean, │ │
│ │ unit variance per dim) │ │
│ └────────────┬─────────────┘ │
│ ▼ │
│ Step 2: ┌──────────────────────────┐ │
│ │ DCT (Discrete Cosine │ energy concentrated │
│ │ Transform) per dimension │ in low-freq coefficients │
│ └────────────┬─────────────┘ │
│ ▼ │
│ Step 3: ┌──────────────────────────┐ │
│ │ Quantize coefficients │ │
│ │ to discrete integers │ │
│ └────────────┬─────────────┘ │
│ ▼ │
│ Step 4: ┌──────────────────────────┐ │
│ │ Flatten 2D ──► 1D │ │
│ │ (D x freq ──► sequence) │ │
│ └────────────┬─────────────┘ │
│ ▼ │
│ Step 5: ┌──────────────────────────┐ │
│ │ BPE Compression │ merge frequent patterns │
│ │ (Byte-Pair Encoding) │ into single tokens │
│ └────────────┬─────────────┘ │
│ ▼ │
│ Compressed Token Sequence (2x-13x shorter) │
│ Fed to VLA autoregressive decoder │
└─────────────────────────────────────────────────────────────────┘
The FAST pipeline consists of five steps:
- Normalization: Raw action sequences are normalized per-dimension to zero mean and unit variance
- Discrete Cosine Transform (DCT): Each action dimension's time series is transformed into frequency components, concentrating energy in fewer coefficients (low-frequency components capture the dominant motion patterns)
- Quantization: DCT coefficients are quantized to discrete integer values, with the quantization level controlling the precision-compression tradeoff
- Flattening: The 2D matrix (dimensions x frequency coefficients) is flattened into a 1D sequence
- Byte-Pair Encoding (BPE): Standard BPE compression merges frequent coefficient patterns into single tokens, further reducing sequence length
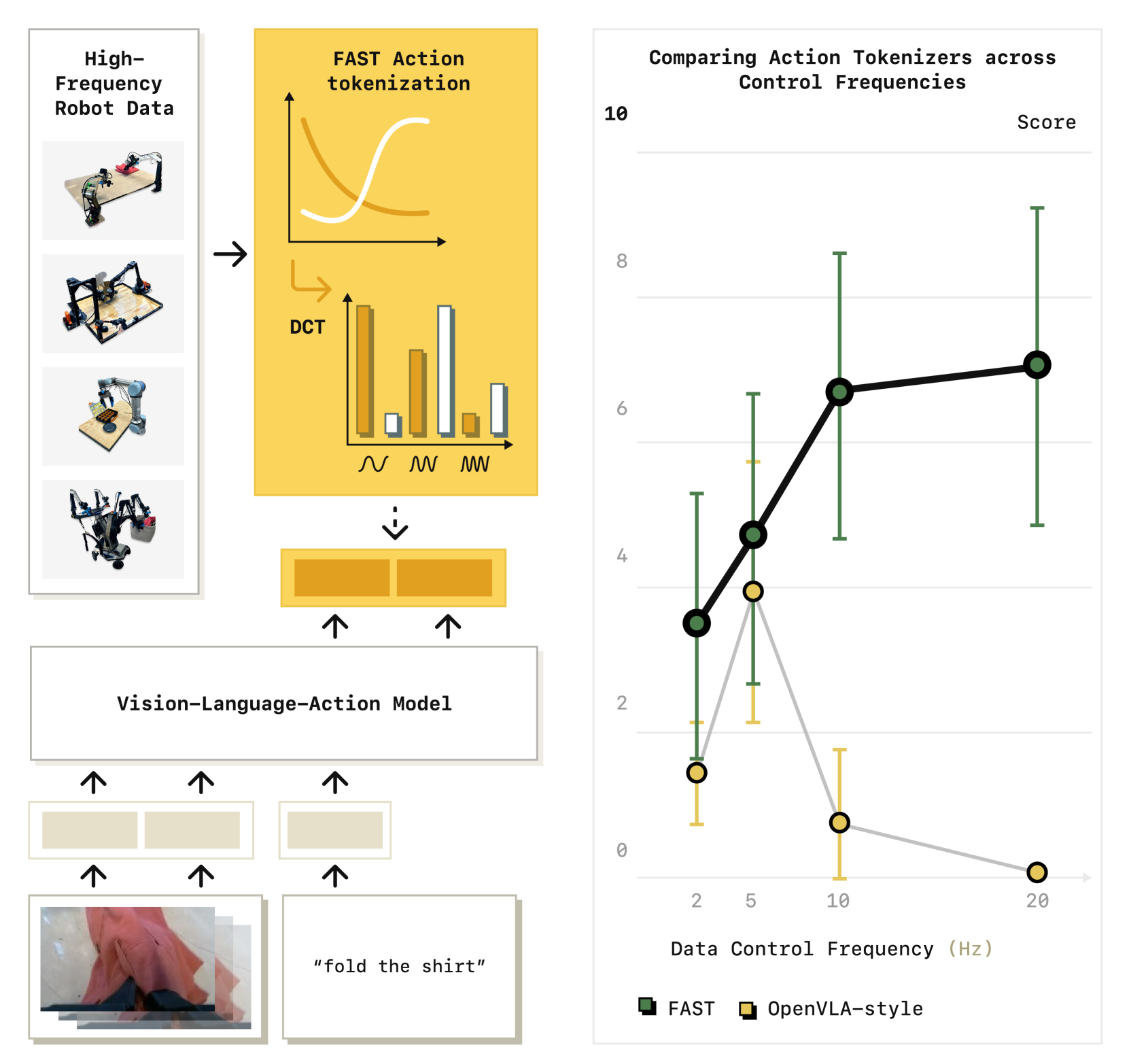
The compression ratio depends on the action space complexity: simple 7-DoF arms achieve ~2x compression, while high-DoF dexterous hands with many action dimensions achieve up to 13x compression due to greater cross-dimension BPE pattern sharing. FAST+ trains the BPE vocabulary on a diverse cross-embodiment dataset, enabling a single tokenizer to work across robot morphologies.
Results

| Method | Training Speed | Compression | Dexterous Tasks | Cross-Embodiment |
|---|---|---|---|---|
| Naive binning (per-dim) | 1x (baseline) | 1x | Cannot learn | Per-robot |
| FAST (task-specific) | ~5x | 2x-13x | Successful | Per-robot |
| FAST+ (universal) | ~5x | 2x-13x | Successful | Zero-shot transfer |
- FAST consistently outperforms naive tokenization across all tested tasks and robot platforms
- 5x faster training convergence due to shorter token sequences requiring fewer autoregressive steps
- Enables learning of complex dexterous tasks (shirt folding, grocery bagging, toast retrieval) that are infeasible with naive tokenization due to prohibitive sequence lengths
- FAST+ universal tokenizer matches task-specific FAST performance, demonstrating that a single tokenizer generalizes across embodiments
- The DCT transform is critical: ablating it (using only BPE on raw values) significantly degrades performance, confirming that frequency-space representation captures meaningful temporal structure
Limitations
- Compression ratio is lower for simple low-DoF systems (e.g., 7-DoF arms, ~2x) compared to high-DoF dexterous systems (up to 13x); the BPE vocabulary must cover a wider variety of action patterns for simpler embodiments with less cross-dimension redundancy
- The quantization step introduces irreversible information loss; very precise tasks may need careful tuning of quantization levels
- BPE vocabulary is fixed after training; novel action patterns not covered by the vocabulary fall back to uncompressed representation
- Evaluation focuses on Physical Intelligence's platforms; independent validation on other VLA architectures (e.g., OpenVLA, RT-2) is limited
Connections
- Pi0 A Vision Language Action Flow Model For General Robot Control -- FAST was developed alongside pi0 at Physical Intelligence; pi0 uses flow matching instead of tokenization
- Openvla An Open Source Vision Language Action Model -- OpenVLA uses naive 256-bin discretization; FAST provides a superior alternative
- Vision Language Action -- addresses a core VLA design axis: action representation
- Robotics -- enables more efficient robot policy training across embodiments