OpenVLA-OFT: Optimizing Speed and Success for VLA Fine-Tuning
Overview
OpenVLA-OFT presents a systematic empirical study of fine-tuning strategies for Vision-Language-Action models, identifying a recipe that boosts the original OpenVLA from 76.5% to 97.1% success rate on the LIBERO benchmark while achieving a 26x inference speedup. The paper addresses a critical deployment bottleneck: OpenVLA's autoregressive action generation runs at only 3-5 Hz, far below the 25-50+ Hz required for real-world high-frequency control. Through careful evaluation of three axes -- action generation strategy, action representation, and learning objectives -- the authors arrive at an optimized fine-tuning configuration that makes VLA deployment practical.
The core architectural change replaces autoregressive (sequential) action token generation with parallel decoding using bidirectional attention, enabling all action tokens to be predicted simultaneously. The base OFT recipe combines parallel decoding, action chunking, a continuous action representation, and an L1 regression objective. An extended variant, OpenVLA-OFT+, additionally incorporates FiLM (Feature-wise Linear Modulation) for enhanced language grounding in scenarios requiring disambiguation across language-conditioned tasks.
Key Contributions
- 97.1% success on LIBERO: Up from 76.5% for vanilla OpenVLA, establishing a new state-of-the-art for VLA fine-tuning on this benchmark
- 26x inference speedup: Parallel action decoding replaces sequential autoregressive generation, reaching deployment-viable control frequencies
- Systematic fine-tuning analysis: Evaluates action generation strategy (autoregressive vs. parallel), action representation (discrete bins vs. continuous), and learning objectives across multiple benchmarks
- Real-world validation on ALOHA: Demonstrates strong bimanual manipulation performance despite OpenVLA being pre-trained only on single-arm data, showing generalization through fine-tuning
Architecture / Method
OpenVLA-OFT vs Original OpenVLA
────────────────────────────────
Original OpenVLA (Slow): OpenVLA-OFT (Fast):
┌─────────────────────┐ ┌─────────────────────────┐
│ Image + Language │ │ Image + Language │
└──────────┬──────────┘ └──────────┬──────────────┘
▼ ▼
┌─────────────────────┐ ┌─────────────────────────┐
│ VLM Backbone │ │ VLM Backbone │
└──────────┬──────────┘ └──────────┬──────────────┘
│ │
▼ ▼
Sequential (causal attn): Parallel (bidirectional attn):
a₁ ──► a₂ ──► ... ──► a₇ ┌───┬───┬───┬───┬───┬───┬───┐
(7 forward passes) │a₁ │a₂ │a₃ │a₄ │a₅ │a₆ │a₇ │
└───┴───┴───┴───┴───┴───┴───┘
(1 forward pass ──► 26x faster)
+ continuous actions + L1 loss
OpenVLA-OFT+ also adds FiLM conditioning for language grounding:
Language ──► FiLM ──► modulate visual patch embeddings
+ LoRA fine-tuning + Proprioception + Multi-camera
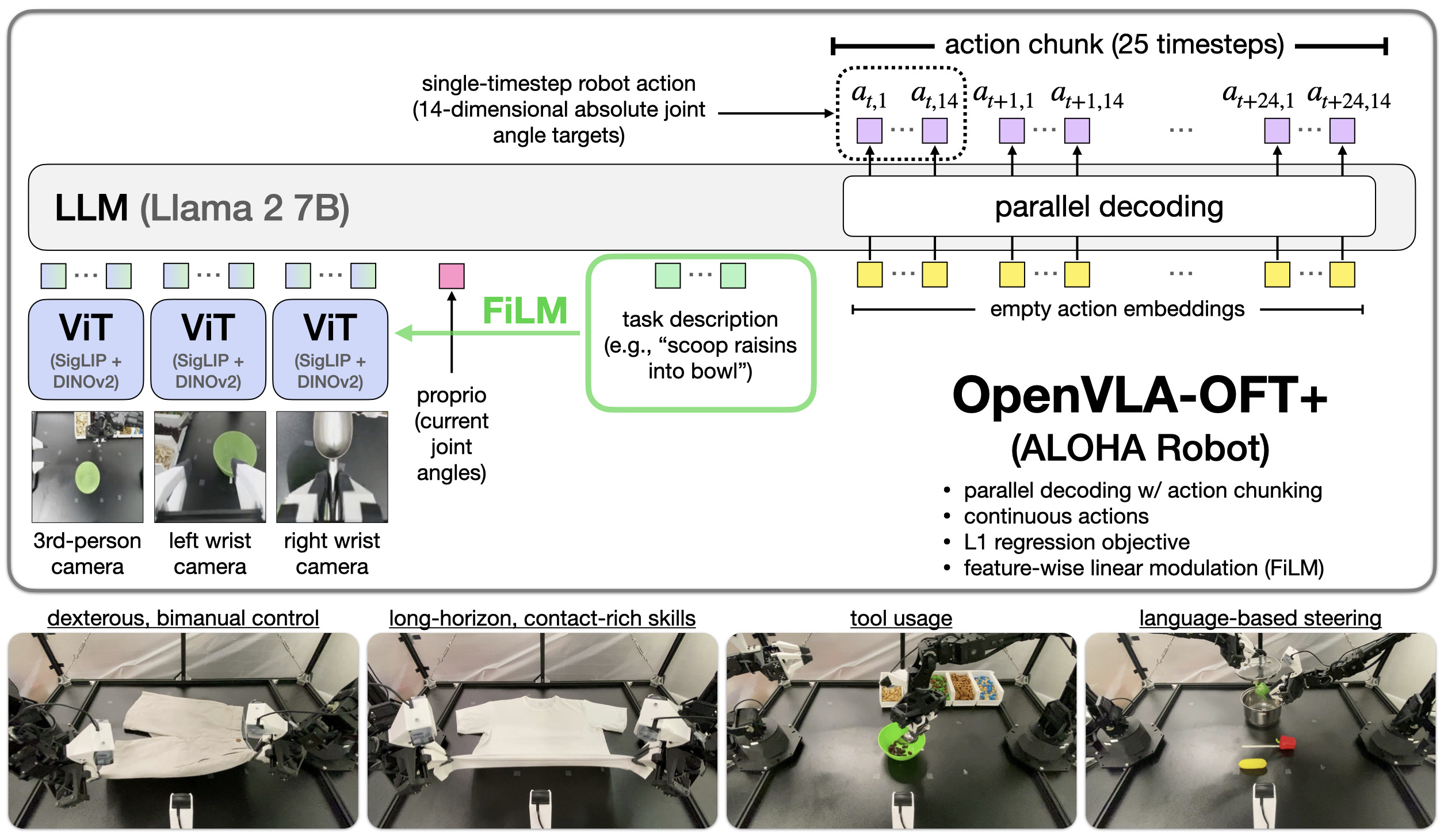
The key modifications to OpenVLA are:
Base OFT recipe (four components together yield 97.1% on LIBERO):
-
Parallel action decoding: Replaces causal (autoregressive) attention over action tokens with bidirectional attention, allowing all action dimensions to attend to each other and be predicted in a single forward pass rather than sequentially. This is the primary source of the 26x speedup.
-
Action chunking: Predicts K future actions per forward pass (K=8 for LIBERO simulation, K=25 for real ALOHA), further increasing throughput and smoothing execution.
-
Continuous action representation: A separate MLP action head maps final hidden states directly to continuous action values, replacing the original 256-bin discretization.
-
L1 regression objective: Minimizes mean L1 distance between predicted and ground-truth actions, simpler and faster than diffusion while achieving equivalent performance.
OpenVLA-OFT+ extensions (add-ons for real-world deployment):
-
FiLM conditioning: Feature-wise Linear Modulation layers modulate visual patch embeddings using averaged language instruction embeddings, providing robust language grounding. Without FiLM, language-conditioned task performance drops to chance level (33.3%) on ALOHA.
-
Multi-modal input processing: Enhanced handling of proprioceptive state and multi-camera views alongside standard image + language inputs.
-
LoRA fine-tuning: Parameter-efficient adaptation preserving pre-trained knowledge while adapting to new tasks and embodiments.
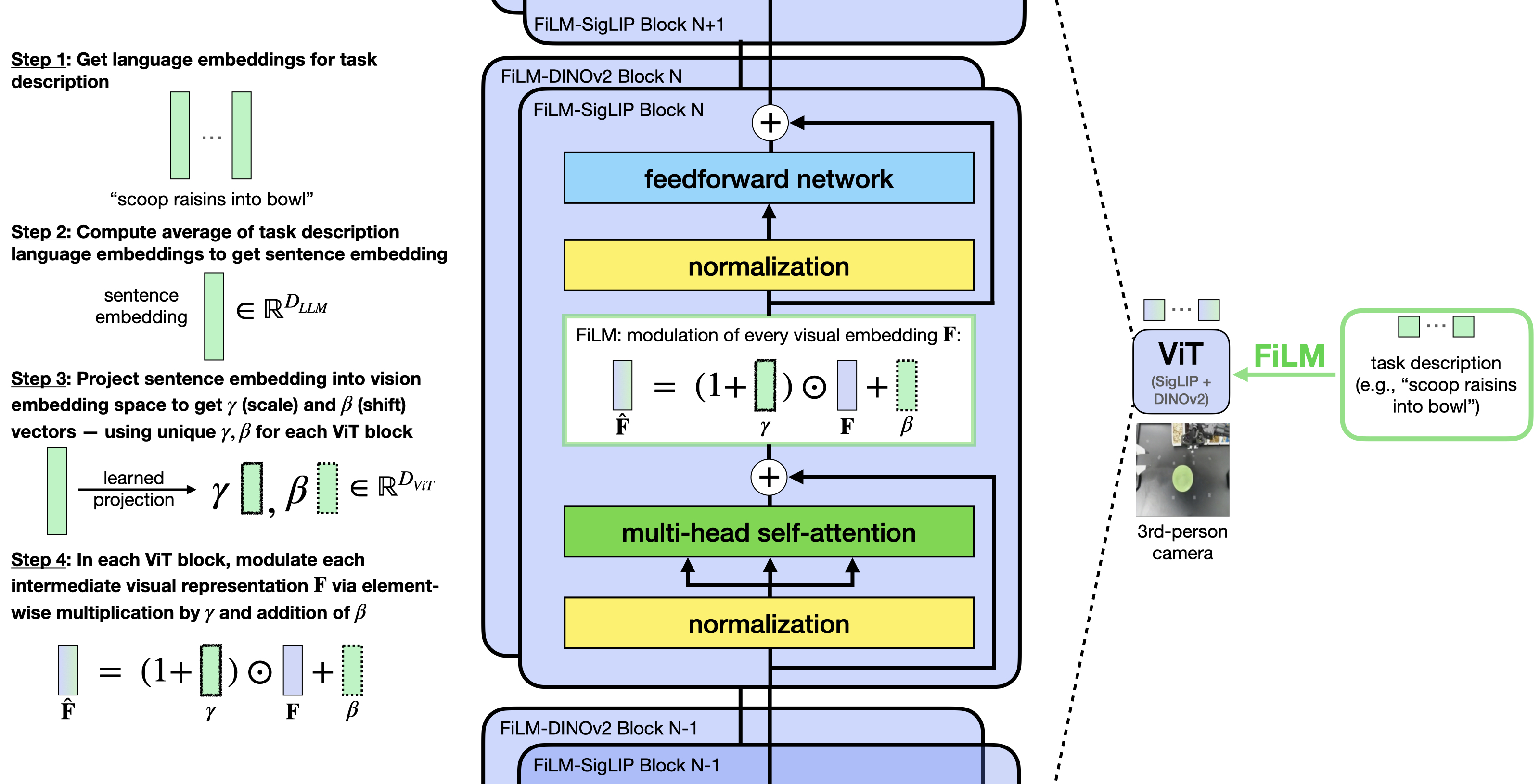
Results


| Configuration | LIBERO Success | Inference Speed | Notes |
|---|---|---|---|
| OpenVLA (original) | 76.5% | 3-5 Hz | Autoregressive, slow |
| OpenVLA-OFT | 97.1% | 109.7 Hz | Parallel decoding + chunking (K=8 sim / K=25 real), 26x faster |
| Baselines (ACT, DP) | Variable | 10-50 Hz | Task-specific methods |
- LIBERO benchmark: 97.1% success rate, a 20.6 percentage point improvement over vanilla OpenVLA
- ALOHA bimanual tasks: OpenVLA-OFT+ achieves 87.8% average success across four dexterous tasks, outperforming π0 (77.1%), RDT-1B (78.4%), ACT (72.3%), and Diffusion Policy (77.5%)
- Language grounding: FiLM conditioning achieves 79.2% on language-conditioned "put X into pot" tasks vs. 33.3% (chance level) without FiLM
- Parallel decoding + action chunking is the single largest contributor to both speed and accuracy improvements, yielding ~14% absolute gain on LIBERO; continuous action representations add another ~5%
- Fine-tuning generalizes well: single-arm pre-training transfers effectively to bimanual setups through OFT recipe
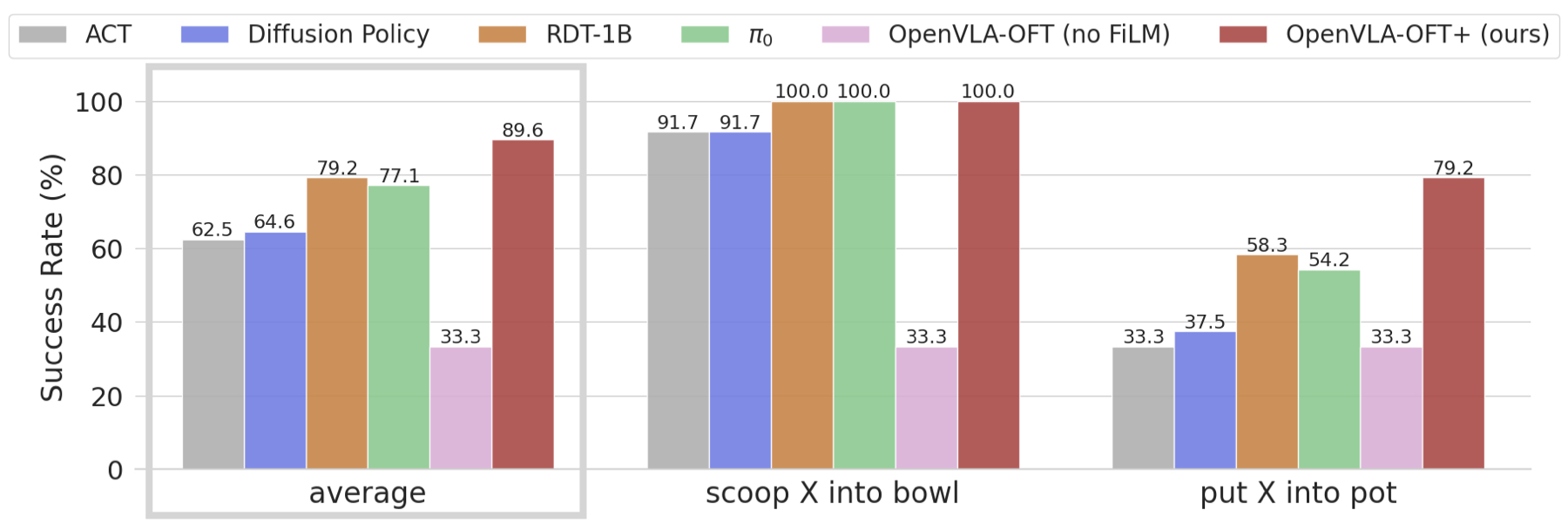
Limitations
- The systematic study is empirical rather than theoretical; the optimal recipe may not transfer to very different VLA architectures or action spaces
- Evaluation primarily on LIBERO (simulation) and ALOHA (specific hardware); broader real-world validation across diverse platforms is needed
- Parallel decoding sacrifices the ability to condition later action dimensions on earlier ones, which may matter for highly coordinated multi-joint actions
- The 26x speedup is measured at the action generation level; end-to-end system latency includes vision encoding which is not optimized here
Connections
- Openvla An Open Source Vision Language Action Model -- direct predecessor; OFT provides the optimized fine-tuning recipe for OpenVLA
- Fast Efficient Action Tokenization For Vision Language Action Models -- complementary approach: FAST compresses tokens, OFT parallelizes decoding
- Pi0 A Vision Language Action Flow Model For General Robot Control -- pi0 uses flow matching for continuous actions; OFT stays within the discrete token paradigm but parallelizes it
- Vision Language Action -- addresses the deployment speed bottleneck of VLA models
- Robotics -- practical fine-tuning for real-world robot deployment