DexVLA: Vision-Language Model with Plug-In Diffusion Expert for General Robot Control
Overview
DexVLA introduces a paradigm shift in VLA architecture by scaling the action generation component to 1 billion parameters using a diffusion-based expert, rather than focusing solely on vision-language scaling as in prior work. The framework integrates a 2B parameter Qwen2-VL vision-language model with a 1B parameter Scale Diffusion Policy (ScaleDP) action expert, trained through a three-stage embodied curriculum learning strategy. DexVLA demonstrates superior performance on complex dexterous manipulation tasks -- achieving 0.92 success on shirt folding where all baselines (OpenVLA, Octo, Diffusion Policy) score near zero after Stage 2 training alone -- across four distinct robot configurations including bimanual setups and a 12-DoF dexterous hand.
The key insight is that previous VLAs underinvest in action generation quality: they pair massive VLMs (billions of parameters for understanding) with tiny action heads (millions of parameters for control). DexVLA argues that scaling the action expert is equally important, especially for dexterous tasks requiring precise, high-dimensional continuous control.
Key Contributions
- Billion-parameter diffusion action expert: ScaleDP scales the diffusion policy to 1B parameters using a transformer architecture, significantly outperforming smaller action heads on dexterous tasks
- Three-stage embodied curriculum: (1) Cross-embodiment diffusion pre-training, (2) Joint VLM + expert training on embodiment-specific data, (3) Fine-tuning with sub-step reasoning annotations for long-horizon tasks
- Sub-step reasoning as implicit planning: The VLM generates intermediate language sub-steps (e.g., "grasp left sleeve" -> "fold right side") that condition the diffusion expert, transforming the VLM into an implicit high-level planner without external planning modules
- Cross-embodiment transfer: 60% zero-shot success when deploying a gripper-trained model to a dexterous hand, demonstrating morphology transfer
Architecture / Method
┌─────────────────────────────────────────────────────────────┐
│ DexVLA │
│ │
│ ┌───────────────────────────────────┐ │
│ │ Qwen2-VL (2B params) │ │
│ │ ┌───────────┐ ┌─────────────┐ │ │
│ │ │ Multi-view │ │ Language │ │ │
│ │ │ Cameras │ │Instruction │ │ │
│ │ └─────┬─────┘ └──────┬─────┘ │ │
│ │ └───────┬───────┘ │ │
│ │ ▼ │ │
│ │ ┌──────────────┐ │ │
│ │ │ VLM Encoder │ │ │
│ │ └──────┬───────┘ │ │
│ │ │ │ │
│ │ ┌──────┴───────┐ │ │
│ │ ▼ ▼ │ │
│ │ ┌──────────┐ ┌───────────┐ │ │
│ │ │ Reasoning│ │ Action │ │ │
│ │ │ Tokens │ │ Tokens │ │ │
│ │ │(sub-step │ │(condition │ │ │
│ │ │ planning)│ │ signal) │ │ │
│ │ └──────────┘ └─────┬─────┘ │ │
│ └───────────────────────┼─────────┘ │
│ │ FiLM conditioning │
│ ▼ │
│ ┌───────────────────────────────────┐ │
│ │ Scale Diffusion Policy (1B) │ │
│ │ ┌─────────────────────────────┐ │ │
│ │ │ Transformer-based Denoiser │ │ │
│ │ │ (iterative denoising) │ │ │
│ │ └──────────┬──────────────────┘ │ │
│ │ ▼ │ │
│ │ ┌─────────────────────────────┐ │ │
│ │ │ Continuous Action Trajectory│ │ │
│ │ │ (high-DoF, dexterous) │ │ │
│ │ └─────────────────────────────┘ │ │
│ └───────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────┘
Three-Stage Curriculum:
Stage 1: Cross-embodiment ──► Stage 2: Joint VLM + ──► Stage 3: Sub-step
diffusion pre-train expert training reasoning FT
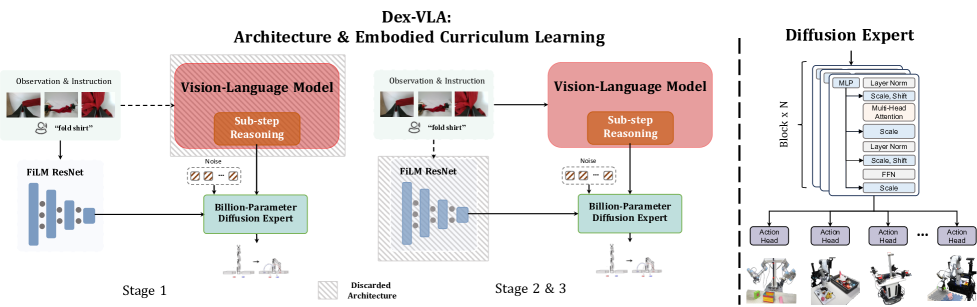
DexVLA's architecture has two main components connected via FiLM (Feature-wise Linear Modulation):
Vision-Language Backbone (2B params): Qwen2-VL processes multi-view camera observations and language instructions. The model generates two types of outputs: (1) reasoning tokens that represent high-level task understanding and sub-step decomposition, and (2) action tokens that serve as conditioning for the diffusion expert.
Scale Diffusion Policy (ScaleDP, 1B params): A transformer-based diffusion model that generates continuous action trajectories conditioned on the VLM's output through FiLM layers. The 1B scale is a deliberate design choice -- ablations show the billion-parameter expert significantly outperforms smaller variants (93M, 410M).

Three-stage curriculum: - Stage 1: Pre-train the diffusion expert on cross-embodiment manipulation data (without VLM), learning general motor primitives - Stage 2: Joint training -- the VLM and diffusion expert are trained together on embodiment-specific datasets, with the VLM learning to produce conditioning signals for the expert - Stage 3: Fine-tune the complete model on high-quality demonstrations annotated with sub-step reasoning, teaching the VLM to decompose long-horizon tasks into intermediate language goals
Results
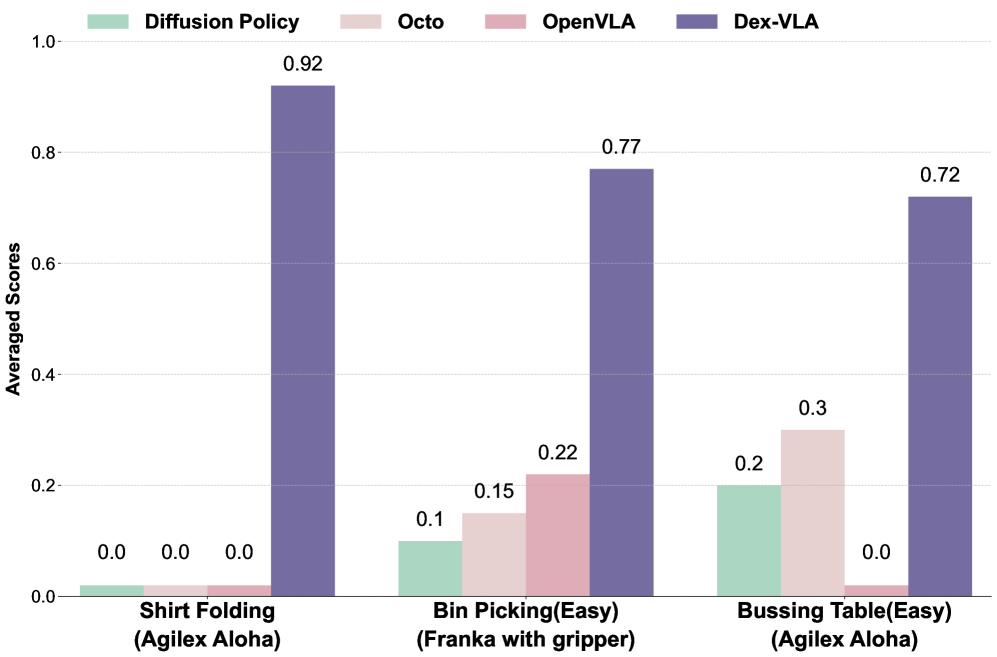
| Task | Robot | DexVLA | pi0 | Other Baselines (OpenVLA, Octo, DP) |
|---|---|---|---|---|
| Shirt folding | Bimanual UR5e | 0.92 | N/A | ~0 |
| Laundry folding | Bimanual UR5e | 0.40 | 0.20 | <0.20 |
| Table bussing (hard) | Bimanual UR5e | 0.70 | 0.63 | - |
| Bin picking | Franka + gripper | High | - | Lower |
| Bin picking (dex hand) | Franka + 12-DoF hand | Strong | - | - |
| Drink pouring | Franka + dex hand | 0.85 | - | - |
| Packing | Bimanual UR5e | 0.95 | - | - |
| Cross-embodiment transfer | Gripper -> Dex hand | 60% zero-shot | - | - |
- Shirt folding: 0.92 success rate where all baselines (OpenVLA, Octo, Diffusion Policy) score near zero -- pi0 is not a baseline for this task; the shirt folding result comes from Stage 2 training without task-specific adaptation
- Data efficiency: Achieves 0.90 average on novel embodiment tasks (drink pouring, packing) with fewer than 100 demonstrations
- Ablation -- Stage 1 critical: Removing cross-embodiment pre-training causes complete learning failure, confirming the curriculum is essential
- Ablation -- expert scale matters: 1B expert achieved 0.92 on shirt folding vs. 0.17 (93M) and 0.63 (410M)
- Ablation -- sub-step reasoning: Removing sub-step annotations causes dramatic performance drops on long-horizon tasks
- Inference speed: 60 Hz on a single A6000 GPU, viable for real-time deployment
Limitations
- The 2B VLM + 1B diffusion expert totals 3B parameters, requiring substantial compute (A6000 GPU) even at 60 Hz
- Sub-step reasoning annotations are expensive to collect and require manual decomposition of long-horizon tasks
- The three-stage curriculum is complex to implement and tune; sensitivity to stage transitions is not fully characterized
- Evaluation is on proprietary platforms; no standardized benchmark comparison (e.g., LIBERO) is provided
- The FiLM interface between VLM and diffusion expert is a potential information bottleneck for very complex conditioning
Connections
- Pi0 A Vision Language Action Flow Model For General Robot Control -- pi0 uses flow matching; DexVLA uses diffusion with a much larger action expert (1B vs. smaller heads)
- Openvla An Open Source Vision Language Action Model -- OpenVLA uses discrete tokens; DexVLA uses continuous diffusion, scaling the action side
- Vision Language Action -- demonstrates that action generation scaling is as important as VLM scaling
- Robotics -- dexterous and bimanual manipulation across 4 robot configurations
- Denoising Diffusion Probabilistic Models -- foundational diffusion model work that ScaleDP builds upon