SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
Overview
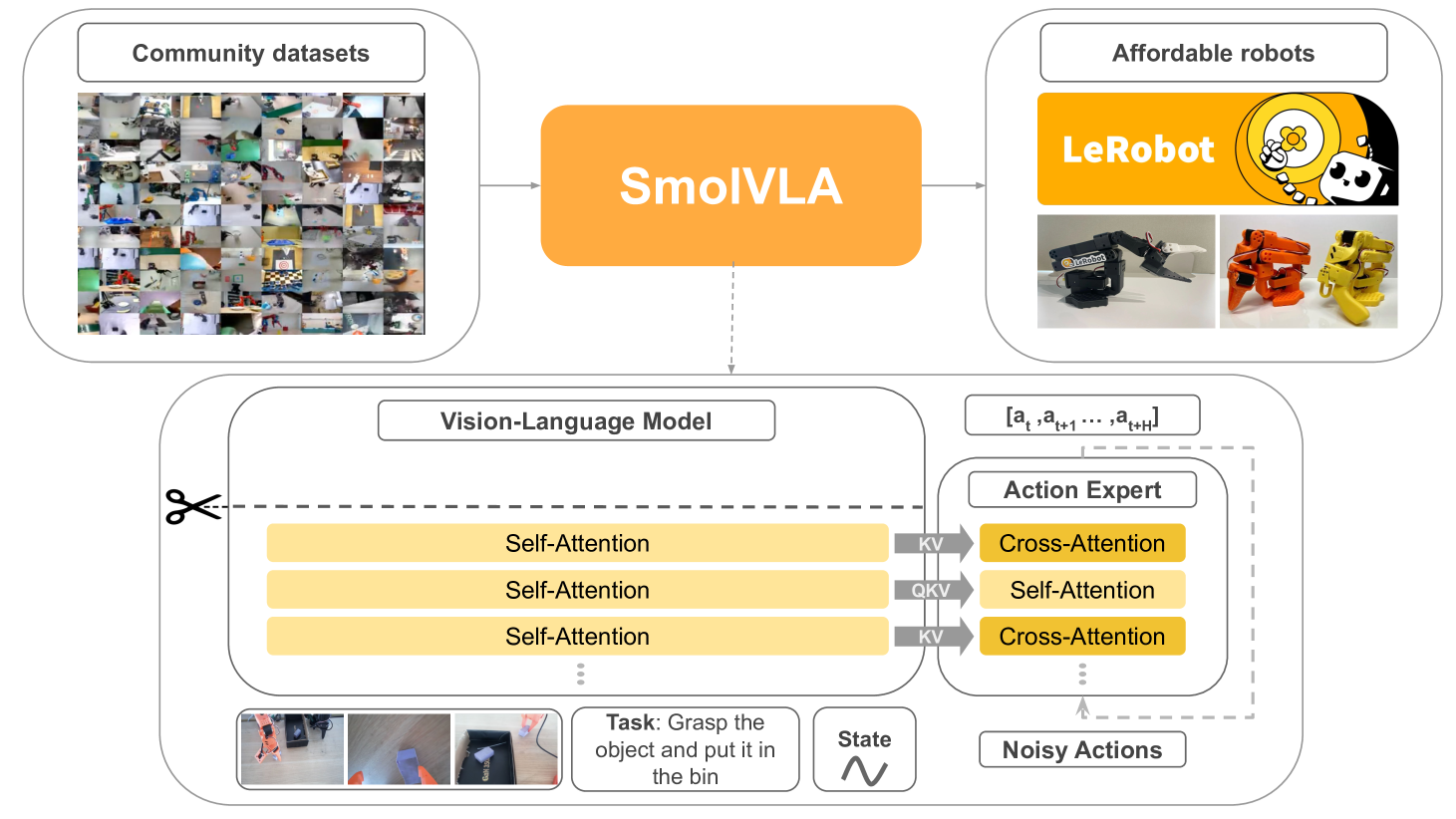
SmolVLA is a 450M-parameter open-source VLA model from Hugging Face that demonstrates competitive performance with models 10x larger while being trainable on a single GPU and deployable on consumer hardware. The architecture combines a SmolVLM-2 vision-language backbone with a dedicated Action Expert module using Flow Matching for continuous action generation.
Key architectural innovations include layer skipping (using only the first N=L/2 decoder layers from the VLM backbone), aggressive visual token reduction to 64 per frame, and interleaved cross-attention and causal self-attention in the Action Expert. The model trains on 481 community-contributed datasets (~10.6M frames, <30K episodes) with automated VLM-based task annotation, and an asynchronous inference stack decouples perception from execution for 30% faster task completion.
SmolVLA achieves 78.3% success on real-world SO-100 robot tasks versus 61.7% for pi0 (3.5B parameters), while consuming 6x less memory and training 40% faster. This establishes that carefully designed compact VLAs can match or exceed much larger models, making practical robot learning accessible to researchers without large compute budgets.
Key Contributions
- Compact efficiency: 450M parameters competitive with 3.3B+ models, trainable on a single GPU
- Community-driven training data: Successfully leverages <30K episodes from 481 public datasets with automated VLM-based task annotation
- Asynchronous inference stack: Decouples VLM perception from action execution, enabling 30% faster task completion (9.7s vs 13.75s) and 2x throughput
- Architectural innovations: Layer skipping (N=L/2), 64 visual tokens per frame, interleaved cross-attention + causal self-attention in the Action Expert
- Full open-source release: Code, pretrained models, training data, and reproducibility recipes
Architecture / Method
┌─────────────────────────────────────────────────────────────┐
│ SmolVLA (450M total) │
│ │
│ ┌───────────┐ ┌────────────────────────────────────┐ │
│ │ RGB Image │───►│ SigLIP Vision Encoder │ │
│ │ (per view)│ └──────────┬─────────────────────────┘ │
│ └───────────┘ │ pixel shuffle │
│ ▼ (64 tokens/frame) │
│ ┌───────────┐ ┌────────────────────────────────────┐ │
│ │ Task Text │───►│ SmolLM2 Decoder (first L/2 layers)│ │
│ └───────────┘ │ [Layer Skipping: N = L/2] │ │
│ └──────────┬─────────────────────────┘ │
│ │ VLM features (frozen) │
│ ▼ │
│ ┌────────────────────────────────────┐ │
│ │ Action Expert (~100M params) │ │
│ │ ┌──────────────────────────────┐ │ │
│ │ │ Cross-Attn (VLM features) │ │ │
│ │ │ Causal Self-Attn (temporal) │ │ │
│ │ │ ... interleaved layers ... │ │ │
│ │ └──────────────┬───────────────┘ │ │
│ │ │ Flow Matching │ │
│ └─────────────────┼──────────────────┘ │
│ ▼ │
│ Action Chunk (10-50 steps) │
└─────────────────────────────────────────────────────────────┘
Vision-Language Backbone (SmolVLM-2): - SigLIP vision encoder processing RGB from multiple camera views - SmolLM2 language decoder for task descriptions - Layer skipping: Only the first N=L/2 decoder layers are used, cutting computation without significant quality loss - Visual tokens: 64 per frame (no tiling, pixel shuffle operations for aggressive reduction)
Action Expert Module (~100M parameters): - Transformer-based, with hidden dimension 0.75x the VLM's - Interleaved layers: cross-attention (conditioning on VLM features) + causal self-attention (temporal dependencies within action chunks) - Training objective: Flow Matching (outperforms L1 regression) - Output: Action chunks of 10-50 timesteps
Training: 200K steps, batch size 256, learning rate 1e-4 to 2.5e-6 (cosine), bfloat16 with torch.compile(). The VLM backbone is frozen; only the Action Expert is updated. Total cost: ~30K GPU hours.
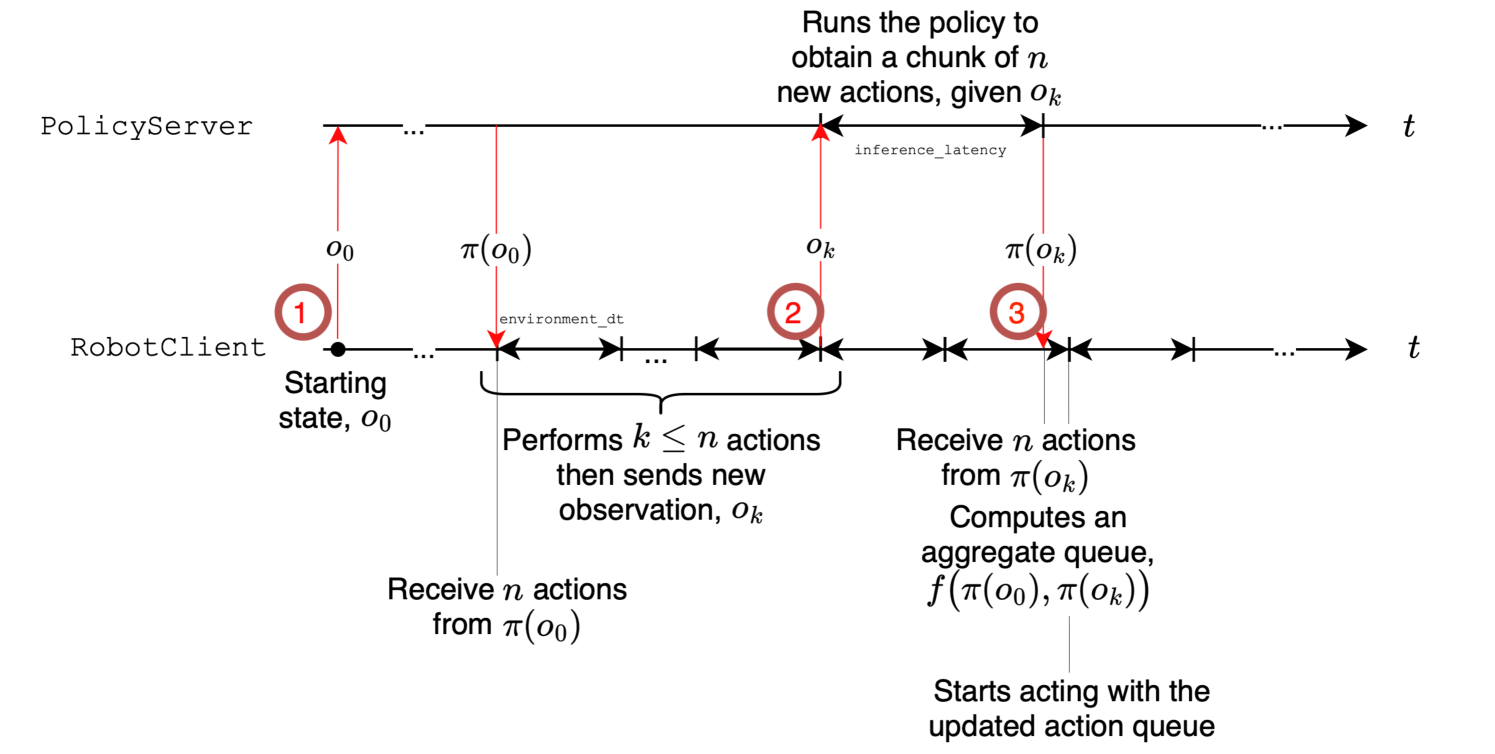
Asynchronous Inference: The VLM runs perception at its natural rate while the Action Expert generates and queues action chunks, with an action queue buffer allowing the robot to continue executing while the next perception cycle runs.
Results

| Setting | SmolVLA (450M) | pi0 | ACT (single-task) |
|---|---|---|---|
| LIBERO (sim) | 87.3% | 86.0% (3.3B) | - |
| SO-100 real (multi-task) | 78.3% | 61.7% (3.5B) | 48.3% |
| SO-101 in-dist | 90% | - | - |
| SO-101 out-of-dist | 50% | - | - |
| Memory | 1x | 6x | - |
| Training speed | 1.4x faster | 1x | - |
- Simulation (LIBERO): 87.3% success vs pi0's 86.0%, with 40% faster training and 6x less memory
- Real-world (SO-100): 78.3% multi-task success, outperforming pi0 (61.7%) by 16.6 points absolute
- Asynchronous inference: 30% faster task completion (9.7s vs 13.75s); 19 pick-place cycles per 60s vs 9 synchronous; no degradation in success rate
- Throughput: 2x improvement with async over sync execution mode
Limitations
- Out-of-distribution generalization drops significantly (90% to 50% on SO-101), suggesting the model memorizes more than it generalizes
- Training data is small (<30K episodes) compared to models like OpenVLA (970K); scaling behavior with more data is unexplored
- Frozen VLM backbone may limit visual grounding for precise manipulation; joint fine-tuning could help but increases compute
- Evaluated only on low-cost SO-100/SO-101 arms; performance on industrial robots with higher-DOF action spaces is unknown
- No RL or self-improvement; pure behavior cloning from community datasets
Connections
- Openvla An Open Source Vision Language Action Model -- OpenVLA is 7B; SmolVLA achieves comparable results at 450M, demonstrating efficiency gains from architectural design
- Uniact Universal Actions For Enhanced Embodied Foundation Models -- Both show that smaller, well-designed models can beat larger baselines; UniAct uses VQ codebooks, SmolVLA uses Flow Matching
- Dita Scaling Diffusion Transformer For Generalist Vla Policy -- Both use diffusion/flow-based action generation rather than token-based; Dita is 334M, SmolVLA is 450M
- Robotics -- Addresses the real-time inference and compute accessibility problems
- Vision Language Action -- Demonstrates that the VLA paradigm works at consumer-hardware scale
- Foundation Models -- Challenges the assumption that foundation model scale is necessary for VLA competence