RoboFlamingo: Vision-Language Foundation Models as Effective Robot Imitators
Overview
RoboFlamingo addresses the question of whether publicly available vision-language models (VLMs) can serve as effective backbones for robot imitation learning, without requiring the massive compute budgets of proprietary systems like RT-2 or PaLM-E. The paper demonstrates that by fine-tuning the open-source OpenFlamingo model on robot manipulation demonstrations, a relatively lightweight framework can achieve state-of-the-art performance on the CALVIN language-conditioned manipulation benchmark.
The core insight is a decoupled architecture that separates vision-language comprehension from sequential decision-making. Rather than forcing the VLM to directly output actions (as RT-2 does), RoboFlamingo uses the frozen or lightly fine-tuned Flamingo backbone for single-step multimodal understanding, then feeds these representations into a dedicated policy head (an LSTM) that handles the temporal aspects of robot control. This decoupling allows the system to leverage the VLM's rich visual-linguistic representations while using an architecture better suited for sequential action prediction.
RoboFlamingo achieves an average task sequence length of 4.09 on CALVIN (completing ~4 out of 5 chained tasks), substantially outperforming prior methods including HULC (3.06) and RT-1 (2.45). Critically, this is achieved with a single consumer-grade GPU for fine-tuning, making VLA research accessible to the broader community -- a theme later amplified by OpenVLA and SmolVLA.
Key Contributions
- First demonstration that open-source VLMs (OpenFlamingo) can be effectively adapted for robot manipulation through efficient fine-tuning, achieving SOTA on CALVIN without proprietary models or massive compute.
- Decoupled architecture design separating VLM-based perception/language understanding from temporal policy learning, showing this is more effective than end-to-end VLA approaches for sequential manipulation tasks.
- Systematic ablation of VLM components for robotics: the paper isolates the contributions of visual pre-training, language grounding, and the policy head architecture, finding that explicit temporal modeling via LSTM is crucial and cannot be replaced by simple MLP heads.
- Accessibility milestone -- demonstrating that competitive robot learning can be done on a single GPU, democratizing VLA research months before OpenVLA made this a community priority.
Architecture
Language Instruction Multi-View RGB Images (per timestep)
│ │
▼ ▼
┌───────────────┐ ┌─────────────────┐
│ LLM Backbone │ │ Frozen ViT-L │
│ (Flamingo) │ │ (CLIP) │
└───────┬───────┘ └────────┬────────┘
│ │
│ ┌────────┴────────┐
│ │ Perceiver │
│ │ Resampler │
│ │ (→ fixed tokens)│
│ └────────┬────────┘
│ │
└──────────┐ ┌────────────────┘
▼ ▼
┌──────────────────────┐
│ Gated Cross-Attn │
│ (fuse vision+lang) │
│ interleaved in LLM │
└──────────┬───────────┘
│
│ (per-timestep features)
▼
┌──────────────────────┐
│ LSTM Policy Head │
│ (temporal modeling │
│ over obs history) │
└──────────┬───────────┘
│
▼
┌──────────────────────┐
│ Linear → 7-DoF │
│ Action (pos,rot,grip)│
└──────────────────────┘
Method
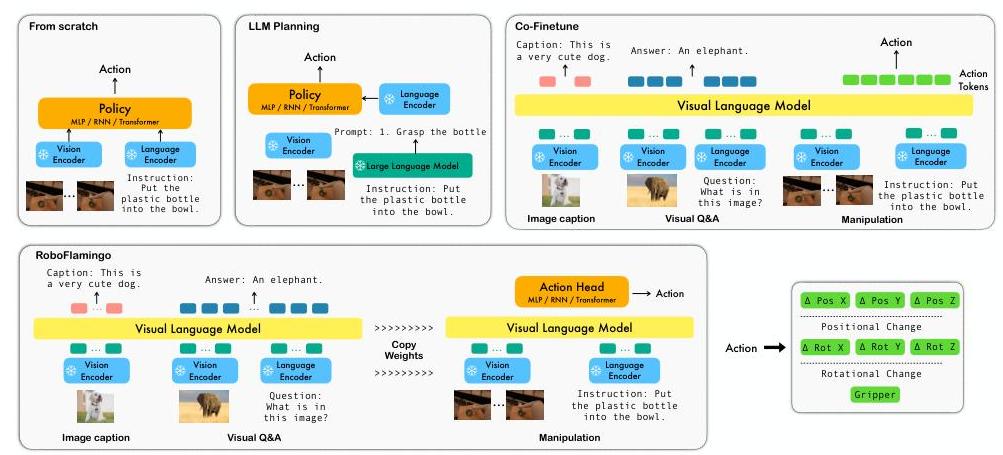
RoboFlamingo builds on the OpenFlamingo architecture, which itself extends Flamingo with open weights. The system processes multi-view observations and language instructions through three main stages:
1. Vision Encoder (ViT). Each image observation is encoded by a frozen Vision Transformer (ViT-L/14 from CLIP). The ViT produces patch-level visual features that capture rich semantic information from pre-training on web-scale image-text data.
2. Perceiver Resampler. The variable-length ViT features are compressed into a fixed number of visual tokens via Flamingo's Perceiver Resampler -- a cross-attention module that attends over the visual features using a small set of learned latent queries. This produces a compact visual representation regardless of image resolution.
3. Feature Fusion Decoder (Gated Cross-Attention). The language instruction is processed by the LLM backbone, and visual tokens from the Perceiver Resampler are fused in via gated cross-attention layers interleaved with the LLM's self-attention layers. This produces a joint vision-language representation for the current observation.
4. Policy Head (LSTM). The fused vision-language features from each timestep are fed sequentially into an LSTM-based policy head that models temporal dependencies across the observation history. The LSTM outputs are mapped through a linear layer to predict 7-DoF robot actions (3D position, 3D rotation, 1D gripper).
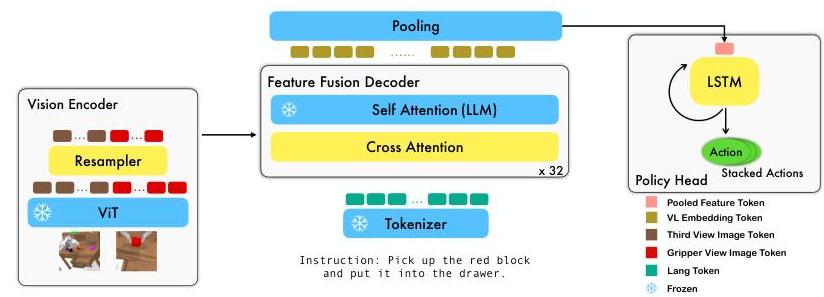
During fine-tuning, the ViT backbone is typically frozen while the Perceiver Resampler, gated cross-attention layers, and the policy head are trained. The LLM backbone can be either frozen or fine-tuned depending on the variant. The paper explores multiple fine-tuning strategies: full fine-tuning of the fusion layers, freezing various components, and co-training with language modeling objectives to preserve VLM capabilities.
Training
- Loss: MSE loss on continuous end-effector pose prediction, combined with BCE loss on discrete gripper open/close status (weighted by λ_gripper)
- Data: CALVIN benchmark demonstrations -- 24 hours of play data across 34 tasks in 4 environments, with language annotations
- Fine-tuning: The VLM backbone (OpenFlamingo 3B or 9B) is adapted with relatively few gradient steps; the policy head is trained from scratch
- Observation history: The LSTM policy head processes a window of recent observations (typically 10-20 steps) to capture temporal context
Results
RoboFlamingo sets a new state-of-the-art on the CALVIN benchmark for language-conditioned manipulation:
| Method | Avg. Len. | 1 Task | 2 Tasks | 3 Tasks | 4 Tasks | 5 Tasks |
|---|---|---|---|---|---|---|
| RoboFlamingo | 4.09 | 96.4% | 89.6% | 82.4% | 74.0% | 66.8% |
| HULC | 3.06 | 88.9% | 73.3% | 58.7% | 47.5% | 38.3% |
| RT-1 (adapted) | 2.45 | 84.4% | 61.7% | 43.8% | 32.3% | 22.7% |
| MCIL | 0.40 | 37.3% | 2.7% | 0.2% | 0.0% | 0.0% |
Key ablation findings
- Policy head matters most: Replacing the LSTM head with an MLP drops average length from 4.09 to ~2.5, confirming that explicit temporal modeling is essential for sequential manipulation.
- VLM pre-training is critical: Training the same architecture from scratch (no VLM pre-training) yields significantly worse results, demonstrating that web-scale vision-language knowledge transfers to robotic control.
- Fine-tuning strategy: Fine-tuning the cross-attention layers while keeping the ViT frozen gives the best trade-off between performance and compute. Full fine-tuning provides marginal gains at much higher cost.
- Language grounding helps: The language-conditioned variant outperforms vision-only baselines, showing that Flamingo's language understanding transfers to task specification in robotics.
Limitations & Open Questions
- Single benchmark: Results are demonstrated only on CALVIN, which features a single robot arm in a tabletop setting. Generalization to diverse embodiments and environments is not tested.
- No real-world validation: All experiments are in simulation. The sim-to-real transfer properties of the fine-tuned VLM representations are unknown.
- Closed-source training data for VLM: While OpenFlamingo is open-source, the VLM's pre-training data (LAION) has quality and licensing concerns that may affect downstream use.
- Action space limitations: The 7-DoF action space is relatively simple. Whether the approach scales to higher-DoF manipulation (bimanual, dexterous hands) is untested.
- Temporal modeling ceiling: The LSTM policy head, while effective, may limit scalability compared to transformer-based temporal architectures used in later work (e.g., diffusion policy heads in pi0, DexVLA).
Connections
Related papers in the wiki:
- Rt 2 Vision Language Action Models Transfer Web Knowledge To Robotic Control -- RT-2 is the primary comparison point; RoboFlamingo achieves competitive results with open-source models and far less compute
- Openvla An Open Source Vision Language Action Model -- OpenVLA continues the democratization theme RoboFlamingo started, scaling to 7B parameters with Open X-Embodiment data
- Rt 1 Robotics Transformer For Real World Control At Scale -- RT-1 serves as a baseline on CALVIN; RoboFlamingo significantly outperforms it
- Palm E An Embodied Multimodal Language Model -- PaLM-E represents the "scale up" approach to embodied VLMs; RoboFlamingo shows smaller open models can be competitive
- Robocat A Self Improving Generalist Agent For Robotic Manipulation -- RoboCat takes a multi-embodiment approach; RoboFlamingo focuses on efficient single-embodiment adaptation
- Ecot Embodied Chain Of Thought Reasoning For Vision Language Action Models -- ECoT later adds chain-of-thought reasoning to VLA fine-tuning, building on the VLM-for-robotics paradigm RoboFlamingo helped establish
- Smolvla A Vision Language Action Model For Affordable Robotics -- SmolVLA (2025) pushes the accessibility theme further with a 450M model on single GPU
- Vision Language Action -- RoboFlamingo sits at the transition between Wave 1 VLAs (RT-1/RT-2) and the open-source VLA movement
- Robotics -- broader context on the VLA revolution in robotics
- Foundation Models -- RoboFlamingo demonstrates foundation model transfer to embodied control