RaCFormer: Towards High-Quality 3D Object Detection via Query-based Radar-Camera Fusion
:page_facing_up: Read on arXiv
Overview
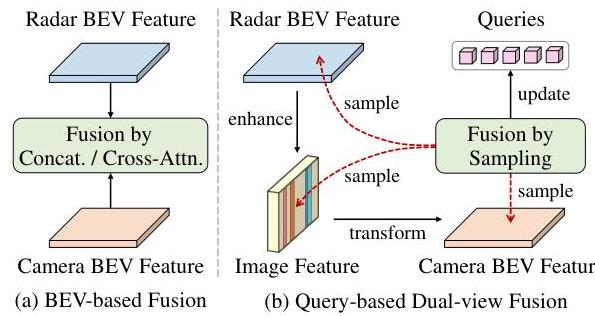
RaCFormer by Chu et al. (USTC, CVPR 2025) addresses a fundamental problem in radar-camera fusion for 3D object detection: the image-to-BEV transformation introduces depth estimation errors that misalign visual content, making naive BEV-level fusion of radar and camera features unreliable. The core insight is that query-based architectures can bypass this problem by adaptively sampling instance-relevant features from both the BEV and the original image view, allowing the model to fall back to perspective-view features when BEV projection is inaccurate.
Radar is attractive as a replacement for expensive LiDAR because it provides direct distance and velocity measurements at low cost and works in all weather conditions. However, radar point clouds are sparse and noisy, making fusion with camera challenging. RaCFormer achieves 64.9% mAP and 70.2% NDS on the nuScenes test set (with VoVNet-99 backbone), establishing state-of-the-art radar-camera fusion performance that approaches LiDAR-based systems at a fraction of the sensor cost.
Key Contributions
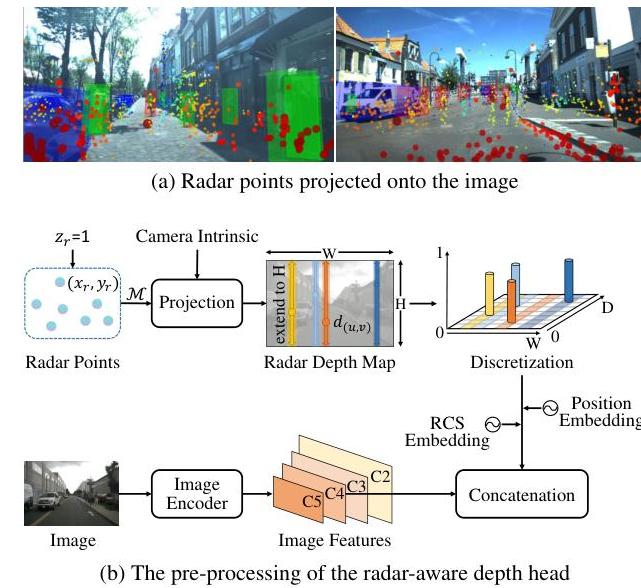
- Radar-Aware Depth Head: Leverages radar's precise distance measurements and RCS (Radar Cross Section) attributes to improve camera depth estimation for the image-to-BEV transformation
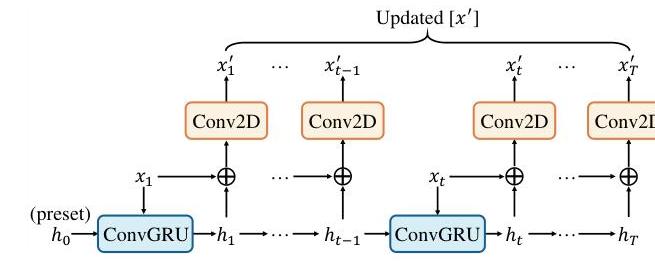
- Implicit Dynamic Catcher: Uses ConvGRU architecture to capture temporal motion information from multi-frame radar data using the Doppler effect, improving detection of dynamic objects
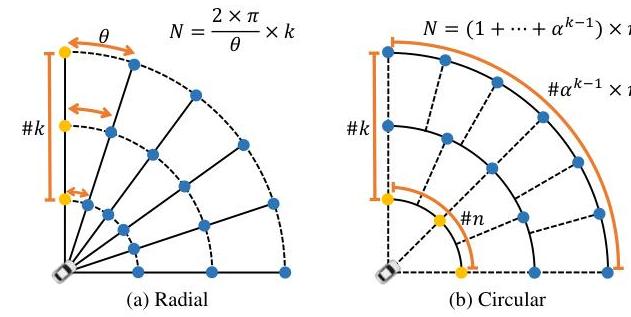
- Linearly Increasing Circular (LIC) Query Initialization: Organizes object queries into concentric circles in polar coordinates with density increasing proportionally with distance, providing balanced coverage across different ranges
- Query-based Dual-View Fusion: Adaptively samples features from both BEV and original image perspectives, mitigating the impact of inaccurate depth estimation in the BEV transformation
Architecture
┌──────────────┐ ┌──────────────────┐
│ Multi-Camera │ │ Radar Points │
│ Images │ │ (sparse + noisy)│
└──────┬───────┘ └────────┬─────────┘
│ │
▼ ▼
┌──────────────┐ ┌──────────────────┐
│ Image Encoder│ │ Pillar Encoder │
│ (ResNet/VoV) │ │ (voxelize+feat) │
└──────┬───────┘ └────────┬─────────┘
│ │
│ ┌───────────────┤
│ │ │
▼ ▼ ▼
┌──────────────────┐ ┌─────────────────────┐
│ Radar-Aware │ │ Implicit Dynamic │
│ Depth Head │ │ Catcher (ConvGRU) │
│ (depth + RCS) │ │ (multi-frame Doppler)│
└──────┬───────────┘ └──────────┬──────────┘
│ │
▼ ▼
┌─────────────────────────────────────────┐
│ BEV Feature Map │
│ (fused camera depth + radar temporal)│
└──────────────────┬──────────────────────┘
│
┌───────────┴───────────┐
│ LIC Query Init │
│ (polar concentric) │
└───────────┬───────────┘
│
┌───────────┴───────────┐
│ Transformer Decoder │
│ ┌─────────────────┐ │
│ │ Dual-View Attn │ │
│ │ BEV ◄──► Image │ │
│ └─────────────────┘ │
└───────────┬───────────┘
│
▼
┌────────────────┐
│ 3D Bounding Box│
│ Predictions │
└────────────────┘
Architecture / Method
The framework consists of several key modules:
Image Encoder + Pillar Encoder: Multi-camera images are encoded by a backbone (e.g., ResNet-101 or VoVNet). Radar point clouds are encoded using a pillar-based encoder that voxelizes the radar returns and extracts features.
Radar-Aware Depth Head: Instead of predicting depth purely from images, RaCFormer incorporates radar distance measurements as guidance. The radar provides sparse but accurate depth cues; the depth head uses these to improve the categorical depth distribution prediction for the LSS view transformation. RCS (Radar Cross Section) attributes are embedded as additional features.
Implicit Dynamic Catcher: Multi-frame radar data is processed through a ConvGRU to capture temporal dynamics. Because radar provides Doppler velocity measurements, this module can identify and track moving objects without explicit object association. The temporal radar features are injected into the BEV representation.
LIC Query Initialization: Object queries are initialized at positions arranged in concentric circles. The key design choice is that query density increases linearly with distance, counteracting the decreasing point density at range. This provides more uniform detection coverage compared to grid-based query initialization.
Transformer Decoder with Dual-View Attention: Queries attend to both the BEV feature map and the original multi-view image features through cross-attention. This dual-view design allows the model to use accurate image features when BEV projection is unreliable, particularly at long range where depth errors compound.
Results
nuScenes Validation Set (ResNet-50, 256×704)
| Method | Sensors | mAP | NDS |
|---|---|---|---|
| HyDRa (radar-camera) | R+C | 49.4% | 58.5% |
| RaCFormer (radar-camera) | R+C | 54.1% | 61.3% |
RaCFormer outperforms HyDRa by 4.7% mAP and 2.8% NDS on the validation set.
nuScenes Test Set (VoVNet-99, extended temporal context)
| Method | Sensors | mAP | NDS |
|---|---|---|---|
| CenterPoint (LiDAR) | L | 60.3% | 67.3% |
| VoxelNeXt (LiDAR) | L | 64.5% | 70.0% |
| HVDetFusion (radar-camera) | R+C | 60.9% | 67.4% |
| RaCFormer (radar-camera) | R+C | 64.9% | 70.2% |
RaCFormer's radar-camera fusion surpasses all LiDAR-only baselines on the test set. It also achieves SOTA on the View-of-Delft (VoD) dataset (54.44% mAP full area; 78.57% mAP in the region of interest, an 8.77% improvement over RCBEVDet).

Limitations
- Radar sparsity still limits performance on small or distant objects compared to dense LiDAR
- The Doppler-based dynamic catcher assumes radial velocity, which may be inaccurate for laterally-moving objects
- Query initialization strategy is designed for the nuScenes sensor configuration; adaptation to other radar placements may be needed
- Inference speed not extensively compared; the dual-view attention adds computational overhead
Connections
- Builds on the BEV paradigm from Lift Splat Shoot Encoding Images From Arbitrary Camera Rigs By Implicitly Unprojecting To 3D (LSS view transformation)
- Query-based detection design follows Bevformer Learning Birds Eye View Representation From Multi Camera Images Via Spatiotemporal Transformers (deformable attention BEV queries)
- Advances the radar-camera fusion direction as an alternative to camera-LiDAR fusion in Transfuser Imitation With Transformer Based Sensor Fusion For Autonomous Driving
- Evaluated on Nuscenes A Multimodal Dataset For Autonomous Driving which provides synchronized radar data
- Perception outputs feed downstream planning systems like Planning Oriented Autonomous Driving (UniAD)