BEVDiffuser: Plug-and-Play Diffusion Model for BEV Denoising with Ground-Truth Guidance
Overview
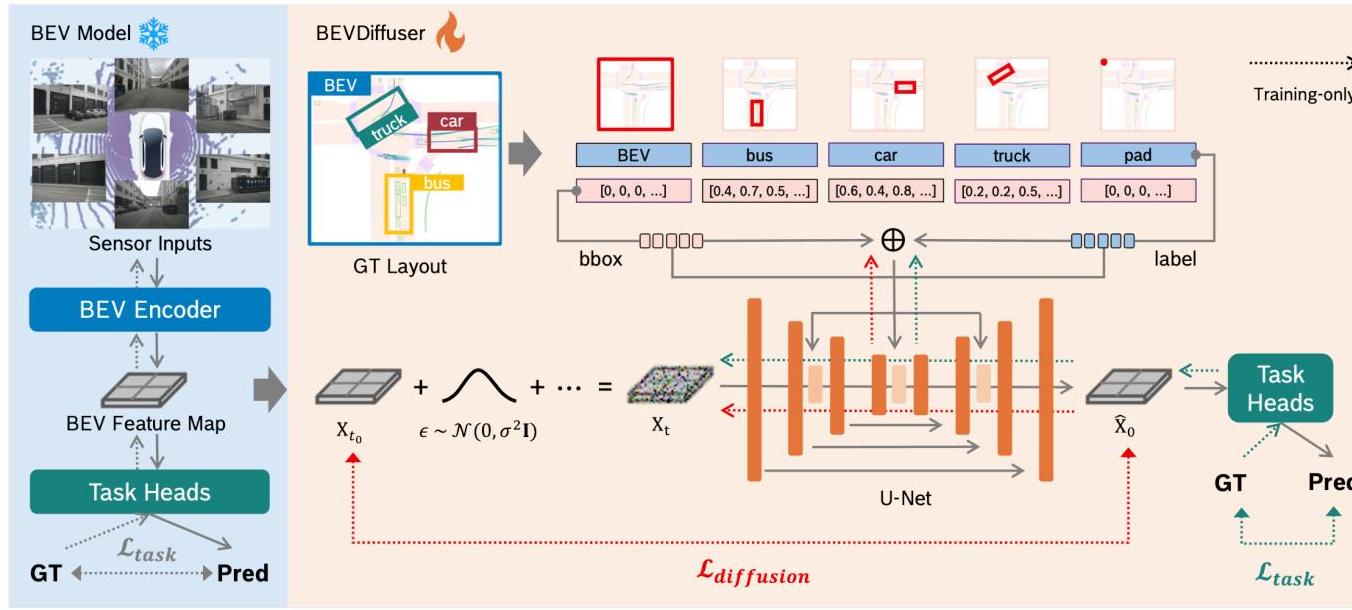
BEVDiffuser addresses a fundamental but under-explored problem in BEV-based perception: the inherent noise in BEV feature maps caused by sensor limitations and the learning process itself. Rather than designing better BEV encoders, BEVDiffuser takes the novel approach of denoising existing BEV features using a conditional diffusion model guided by ground-truth object layouts.
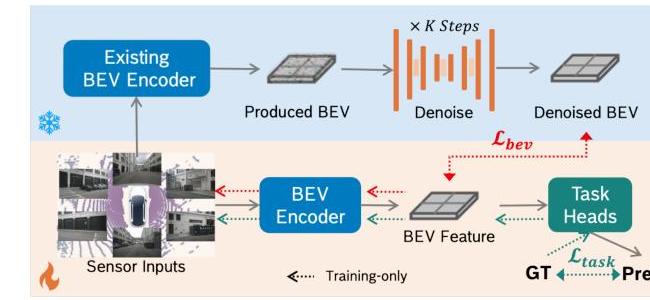
The critical design insight is that BEVDiffuser operates only during training: it provides denoised BEV features as supervision targets for the base model, then is completely removed at inference. This means zero additional computational overhead at deployment while the base model permanently benefits from training against cleaner targets. The approach is architecture-agnostic -- it works as a plug-and-play module for any BEV detector.
Applied to BEVFormer-tiny, BEVDiffuser yields 12.3% mAP improvement and 10.1% NDS gain on nuScenes 3D object detection, with particularly dramatic improvements on long-tail objects (24-30% mAP gains on construction vehicles and buses) and challenging conditions (20-29% mAP improvement in night scenarios).
Key Contributions
- Training-only diffusion denoising: A diffusion model that enhances BEV features during training but is removed at inference, achieving zero-overhead improvement
- Ground-truth layout guidance: Uses clean object layouts (category IDs + 3D bounding boxes) as conditioning instead of noisy learned features, providing an oracle-quality denoising target
- Universal plug-and-play: Works across different BEV architectures (BEVFormer, BEVFormerV2, BEVFusion) without requiring any architectural modifications
- Long-tail and adverse condition robustness: Dramatically improves detection of rare objects and performance in night/weather scenarios
Architecture / Method

┌──────────────────── TRAINING ONLY ────────────────────────────┐
│ │
│ Multi-Camera GT Layout (cat ID + 3D bbox) │
│ Images │ │
│ │ ▼ │
│ ▼ ┌────────────────┐ │
│ ┌──────────┐ │ Layout Encoder │ │
│ │ BEV │ │ (global scene │ │
│ │ Encoder │ │ + per-object) │ │
│ │ (any) │ └───────┬────────┘ │
│ └────┬─────┘ │ │
│ │ ▼ │
│ │ ┌───────────────────┐ │
│ Noisy BEV ───► │ BEVDiffuser │ │
│ features x_t0 │ (Conditional │ │
│ │ │ Diffusion U-Net │ │
│ │ │ + Cross-Attn) │ │
│ │ └────────┬──────────┘ │
│ │ │ │
│ │ Denoised BEV │
│ │ │ │
│ ▼ ▼ │
│ ┌──────────────────────────────┐ │
│ │ L_total = L_diffusion(MSE) │ │
│ │ + λ·L_task │ │
│ │ L_BEV = L_task │ │
│ │ + α·L(denoised,orig)│ │
│ └──────────────────────────────┘ │
│ │
├──────────────────── INFERENCE ────────────────────────────────┤
│ │
│ Multi-Camera ──► BEV Encoder ──► Detection Head │
│ (BEVDiffuser completely removed, zero overhead) │
└───────────────────────────────────────────────────────────────┘
Core Components: - Conditional diffusion model: U-Net with transformer-based layout fusion - Ground-truth layout representation: Objects encoded as sets of (category ID, normalized 3D bounding box coordinates) - Dual-level conditioning: (1) Global scene context via a "virtual unit cube" object representing the full scene, (2) Local object-aware information through cross-attention between U-Net features and individual object encodings
Training Strategy: 1. BEVDiffuser targets the initial encoder BEV features (x_t0) as the denoising objective 2. Joint loss: L_total = L_diffusion(MSE) + lambda * L_task 3. Base model supervised via denoised outputs: L_BEV = L_task + alpha * L_BEV(denoised vs original)
Inference: BEVDiffuser is completely removed. The enhanced base model operates with its original architecture and computational cost.
Generative capability: BEVDiffuser can also generate BEV features from pure noise conditioned on layouts, achieving 41.1% NDS and 36.7% mAP, suggesting potential for data augmentation and world model applications.
Results
| Model + BEVDiffuser | mAP Gain | NDS Gain |
|---|---|---|
| BEVFormer-tiny | +12.3% | +10.1% |
| BEVFormerV2 | +13.5% | +8.8% |
| BEVFusion | Consistent gains | Consistent gains |
Long-tail object detection (BEVFormer-tiny):
| Category | mAP Improvement |
|---|---|
| Construction vehicle | +24.1% |
| Bus | +29.5% |
Challenging conditions:
| Condition | mAP Gain (tiny) | mAP Gain (V2) |
|---|---|---|
| Night | +20.0% | +28.9% |
| Weather | Improvements across all conditions | - |
Generative performance: 41.1% NDS and 36.7% mAP generating BEV features from pure noise with layout conditioning.
Computational cost: Zero inference-time overhead; maintains baseline FPS.
Limitations
- Requires ground-truth 3D bounding boxes during training, which are expensive to annotate; cannot be used with unlabeled data
- The "denoised" BEV features may not represent true ground-truth BEV; the diffusion model learns a proxy that may introduce its own biases
- Evaluated only on nuScenes; generalization to other datasets and sensor configurations is unvalidated
- The generative capability (BEV from noise) is preliminary; whether generated BEV features are diverse and realistic enough for actual data augmentation is unexplored
- Training time increases due to the additional diffusion model, even though inference is unchanged
Connections
- Bevformer Learning Birds Eye View Representation From Multi Camera Images Via Spatiotemporal Transformers -- BEVFormer is the primary base model enhanced by BEVDiffuser
- Lift Splat Shoot Encoding Images From Arbitrary Camera Rigs By Implicitly Unprojecting To 3D -- LSS established the BEV generation paradigm that BEVDiffuser denoises
- Gaussianlss Toward Real World Bev Perception With Depth Uncertainty Via Gaussian Splatting -- Both address BEV quality; GaussianLSS improves generation, BEVDiffuser improves post-hoc via denoising
- Denoising Diffusion Probabilistic Models -- DDPM provides the diffusion foundation that BEVDiffuser adapts to BEV feature denoising
- Perception -- Addresses BEV feature quality, a fundamental perception bottleneck
- Autonomous Driving -- Improves detection robustness for safety-critical driving