OccMamba: Semantic Occupancy Prediction with State Space Models
Overview
OccMamba is the first Mamba-based network for semantic occupancy prediction, replacing transformer architectures' quadratic complexity with Mamba's linear complexity while maintaining global context modeling. The core challenge is that Mamba operates on 1D sequences, but occupancy prediction requires 3D spatial reasoning.
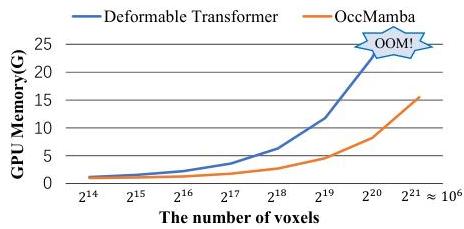
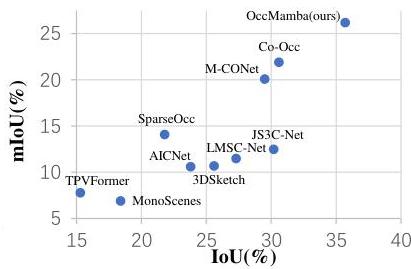
The paper introduces a height-prioritized 2D Hilbert expansion -- a novel 3D-to-1D reordering scheme that maximally preserves spatial locality when flattening 3D voxels into a sequence for Mamba processing. This is combined with a hierarchical Mamba module for multi-scale global context and a Local Context Processor for fine-grained details. OccMamba achieves +5.1% IoU and +4.3% mIoU over the previous state-of-the-art (Co-Occ) on OpenOccupancy, while reducing training memory by 38% and inference time by 65%.
Key Contributions
- First Mamba-based occupancy network: Demonstrates that state space models can replace transformers for 3D semantic occupancy prediction with linear instead of quadratic complexity
- Height-prioritized 2D Hilbert expansion: Novel 3D-to-1D serialization preserving spatial structure by first collapsing the height dimension then applying a 2D Hilbert space-filling curve, achieving 25.2% mIoU vs 24.5% for naive XYZ ordering
- Hierarchical Mamba module: Multi-resolution encoder-decoder with downsampling/upsampling and skip connections for multi-scale global context aggregation
- Local Context Processor: Overlapping patch division with local Mamba processing and 3D convolution reassembly for fine-grained semantic details
- Significant efficiency gains: 38% training memory reduction, 65% inference time reduction over transformer-based alternatives
Architecture / Method
┌──────────────┐ ┌──────────────────┐
│ LiDAR │ │ Multi-Camera │
│ Voxelize + │ │ ResNet + FPN + │
│ Sparse Conv │ │ View Transform │
└──────┬───────┘ └────────┬─────────┘
│ │
└────────┬───────────┘
│ concat (3D features)
▼
┌───────────────────────────────────────────────┐
│ Height-Prioritized 2D Hilbert Expansion │
│ 3D voxels ──► collapse Z ──► 2D Hilbert │
│ curve ──► 1D sequence (preserves locality) │
└───────────────────┬───────────────────────────┘
│
┌────────────▼────────────┐
│ Hierarchical Mamba │
│ ┌────────────────────┐ │
│ │ Mamba block (fine) │ │
│ │ ↓ downsample │ │
│ │ Mamba block (mid) │ │
│ │ ↓ downsample │ │
│ │ Mamba block(coarse)│ │
│ │ ↓ upsample │ │
│ │ + skip connections │ │
│ └────────────────────┘ │
└────────────┬────────────┘
│
┌────────────▼────────────┐
│ Local Context Processor │
│ Overlapping patches + │
│ local Mamba + 3D conv │
└────────────┬────────────┘
│
▼
┌─────────────────────────┐
│ Semantic Occupancy │
│ Predictions │
└─────────────────────────┘
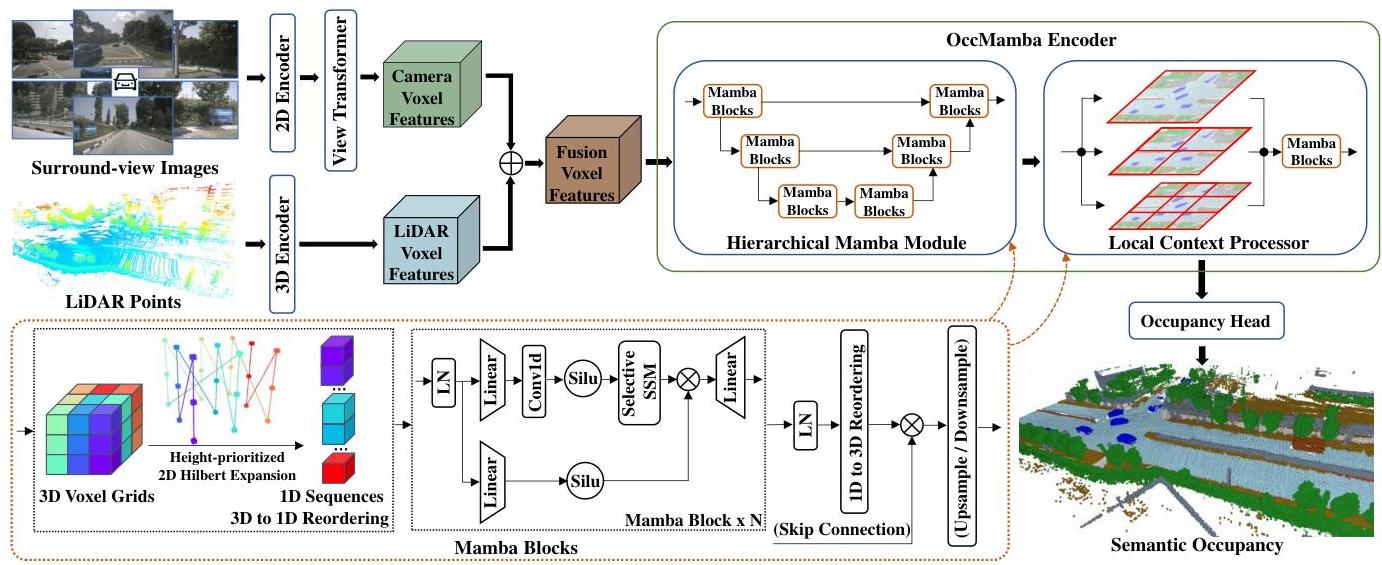
Multi-Modal Encoders: - LiDAR branch: Voxelization + sparse convolution encoder - Image branch: ResNet with FPN + view transformation to 3D features - Feature fusion via channel concatenation
Height-Prioritized 2D Hilbert Expansion: The key innovation for adapting Mamba to 3D: first collapse the height dimension (least spatially varying in driving scenes), then apply a 2D Hilbert space-filling curve to the resulting BEV-like representation. This preserves more 3D spatial locality than direct 3D Hilbert curves or axis-aligned flattening.
Hierarchical Mamba Module: Encoder-decoder with multiple resolution levels, each containing Mamba blocks. Downsampling reduces spatial resolution; upsampling with skip connections recovers detail. Global context is captured at coarse levels with linear complexity.
Local Context Processor: Overlapping patch division processes local regions independently with Mamba, then reassembles via 3D convolution. This captures fine-grained semantic details that global processing may miss.
Training loss: Cross-entropy + Lovasz-Softmax + geometric affinity + semantic affinity + depth supervision (5 components).
Results
| Benchmark | OccMamba | Previous SOTA | Improvement |
|---|---|---|---|
| OpenOccupancy IoU | +5.1% | Co-Occ | Absolute |
| OpenOccupancy mIoU | +4.3% | Co-Occ | Absolute |
| SemanticKITTI | SOTA | Co-Occ | Outperforms |
| SemanticPOSS | SOTA | - | Highest LiDAR-only |
| Efficiency (OccMamba-128 vs baseline) | Reduction |
|---|---|
| Training memory | -38% |
| Inference memory | -44% |
| Inference time | -65% |
Ablation on reordering schemes: - Height-prioritized 2D Hilbert: 25.2% mIoU (best) - 3D Hilbert curve: 24.8% - ZXY sequence: 24.7% - XYZ sequence: 24.5%
Limitations
- Uses both LiDAR and camera inputs; camera-only performance is not evaluated, limiting applicability to camera-only systems (Tesla-style)
- Hilbert curve ordering is fixed and handcrafted; a learned serialization might better adapt to scene statistics
- Mamba's sequential nature limits parallelism during inference compared to transformers, potentially affecting latency on modern GPUs
- Evaluated on static occupancy; temporal extension (streaming/forecasting) is not explored
Connections
- Gaussianformer 2 Probabilistic Gaussian Superposition For Efficient 3D Occupancy Prediction -- Both address efficient 3D occupancy; GaussianFormer-2 uses sparse Gaussians, OccMamba uses efficient sequence modeling
- Gaussianworld Gaussian World Model For Streaming 3D Occupancy Prediction -- GaussianWorld adds temporal prediction; OccMamba is single-frame but more efficient
- Drive Occworld Driving In The Occupancy World -- Both target occupancy prediction; Drive-OccWorld extends to 4D forecasting
- Bevformer Learning Birds Eye View Representation From Multi Camera Images Via Spatiotemporal Transformers -- BEVFormer uses transformer attention for BEV; OccMamba replaces this with Mamba for full 3D
- Perception -- Advances efficient 3D scene understanding
- Autonomous Driving -- Practical occupancy prediction for driving systems