Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Overview
Transformers have dominated sequence modeling since 2017, but their quadratic-complexity self-attention mechanism creates a fundamental bottleneck for long sequences. Structured state space models (SSMs) like S4 offered linear-time alternatives with strong performance on continuous-signal tasks (audio, time series), but consistently underperformed Transformers on discrete, information-dense modalities like language. Mamba identifies the root cause of this gap: prior SSMs use fixed, input-independent parameters that cannot perform content-based reasoning -- they process every token identically regardless of context.
The core insight is making SSM parameters functions of the input, creating a selective state space model (S6) that can dynamically decide what information to propagate or forget along the sequence. This selectivity is analogous to how gating mechanisms in LSTMs and GRUs enable content-aware filtering, but applied within the continuous-time SSM framework. The key trade-off is that input-dependent parameters break the convolution-mode computation that made prior SSMs efficient, so the authors develop a hardware-aware selective scan algorithm that fuses the recurrence into optimized CUDA kernels using work-efficient parallel scan, achieving 20-40x speedup over naive implementations.
The resulting Mamba architecture is remarkably simple: it replaces the Transformer's interleaved attention and MLP blocks with a single repeated block built around the selective SSM. A 3B-parameter Mamba model matches or exceeds Transformers of equal size on language modeling and matches Transformers twice its size, while achieving 5x higher inference throughput. On long-context tasks, Mamba's performance scales to million-token sequences with true linear complexity, fundamentally changing the cost structure of sequence modeling.
Key Contributions
- Selective state space models (S6): Makes SSM parameters (discretization step delta, B, C matrices) input-dependent, enabling content-based reasoning and resolving the performance gap between SSMs and Transformers on discrete modalities
- Hardware-aware selective scan algorithm: A fused CUDA kernel that computes the selective SSM recurrence without materializing the full expanded state in HBM, using parallel scan and kernel fusion to achieve GPU-efficient execution
- Simplified architecture: The Mamba block replaces both attention and MLP sub-layers with a single gated module containing a selective SSM, 1D convolution, and SiLU gating -- yielding a homogeneous architecture with 3-5x fewer parameters per layer than a Transformer block at equivalent performance
- State-of-the-art across modalities: Achieves best results on language modeling (matching 2x-size Transformers), audio generation and modeling (SC09 speech generation, YouTubeMix autoregressive pretraining), and genomics benchmarks, demonstrating that selection is the key missing ingredient for SSMs on discrete data
- Linear-time inference with constant memory: Unlike Transformers whose KV cache grows linearly with context, Mamba maintains a fixed-size hidden state, enabling true O(1) per-step inference with O(n) total sequence cost
Architecture / Method
┌──────────────────────────────────────────────────────────┐
│ Mamba Block │
│ │
│ Input x ──► Linear (expand 2x) ──┬──────────────────┐ │
│ │ │ │
│ ┌─────┴─────┐ ┌─────┴──┐│
│ │ Branch 1 │ │Branch 2││
│ │ │ │ ││
│ │ Conv1D(k=4)│ │ SiLU ││
│ │ ▼ │ │ (gate) ││
│ │ SiLU │ │ ││
│ │ ▼ │ │ ││
│ │ Selective │ │ ││
│ │ SSM (S6) │ │ ││
│ │ ┌────────┐ │ │ ││
│ │ │Δ=f(x) │ │ │ ││
│ │ │B=f(x) │ │ │ ││
│ │ │C=f(x) │ │ │ ││
│ │ │A=fixed │ │ │ ││
│ │ └────────┘ │ │ ││
│ └─────┬─────┘ └────┬───┘│
│ │ multiply │ │
│ └───────⊗─────────┘ │
│ │ │
│ Linear (project down) │
│ │ │
│ Output │
└──────────────────────────────────────────────────────────┘
h(t) = Ā(t)·h(t-1) + B̄(t)·x(t) ← O(n) recurrence
y(t) = C(t)·h(t) (vs O(n²) attention)
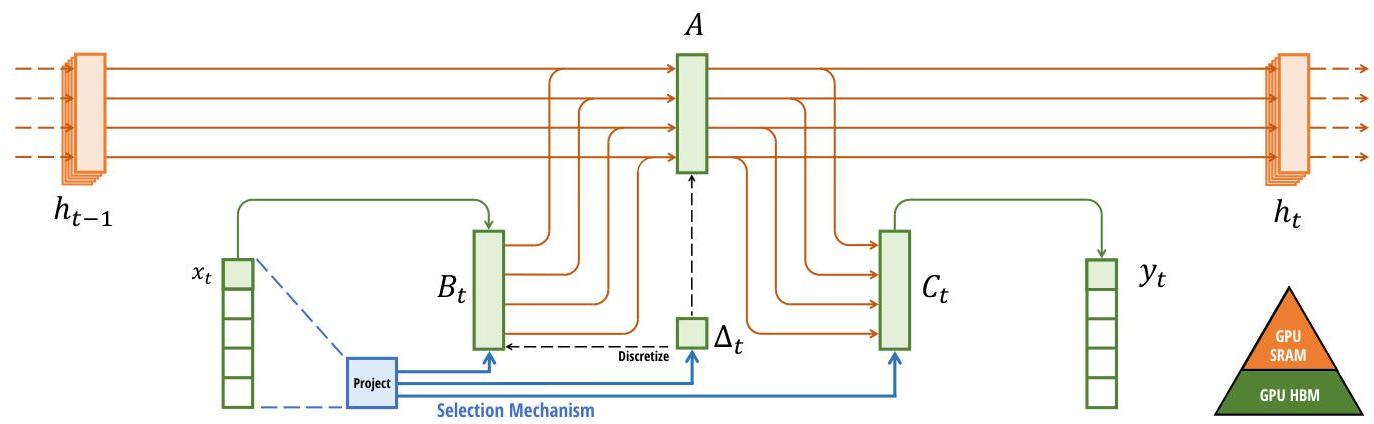
Selective State Space Model (S6)
The foundation is the continuous-time state space model: dx/dt = Ax + Bu, y = Cx + Du. Prior work (S4, S4D) discretized this with fixed parameters A, B, C, making the model a linear time-invariant (LTI) system computable as a convolution. Mamba makes B, C, and the discretization step delta functions of the input:
- delta(t) = softplus(Linear(x(t))) -- controls how much of the current input to incorporate vs. how much of the prior state to retain. Large delta means "remember this token"; small delta means "skip it."
- B(t) = Linear(x(t)) -- input-dependent input projection
- C(t) = Linear(x(t)) -- input-dependent output projection
- A remains fixed (initialized as a learned diagonal matrix) and is discretized via A_bar = exp(delta * A)
This input-dependence is the selection mechanism. It allows the model to selectively propagate relevant information and ignore irrelevant tokens, analogous to the forget gate in LSTMs but operating in the structured state space.
Hardware-Aware Parallel Scan
Because the parameters are now input-dependent, the model cannot be computed as a convolution (which requires LTI). Instead, the authors use a parallel scan (prefix sum) over the recurrence h(t) = A_bar(t) * h(t-1) + B_bar(t) * x(t). The key optimization is:
- Kernel fusion: The discretization of A, B and the entire scan are fused into a single CUDA kernel, avoiding reads/writes of the O(BLDN) intermediate state to slow GPU HBM
- SRAM utilization: The expanded state is kept in fast on-chip SRAM during the scan, with only the final output written to HBM
- Recomputation on backward pass: Rather than storing the large intermediate states for backpropagation, they are recomputed from inputs during the backward pass, trading FLOPs for memory
This yields a 20-40x wall-clock speedup over a naive PyTorch implementation and makes training speeds competitive with optimized Transformer attention.
The Mamba Block
The full Mamba block is a gated architecture:
- Input x is projected up by factor E (default 2) via two parallel linear projections
- One branch passes through a 1D causal convolution (kernel size 4) followed by SiLU activation, then the selective SSM
- The other branch applies SiLU activation and serves as a multiplicative gate
- The gated output is projected back down to model dimension
This replaces both the self-attention and MLP blocks of a Transformer with a single module; two Mamba blocks are roughly equivalent in parameter count to one Transformer MHA+MLP block.
Results
Mamba establishes new state-of-the-art results across multiple modalities:
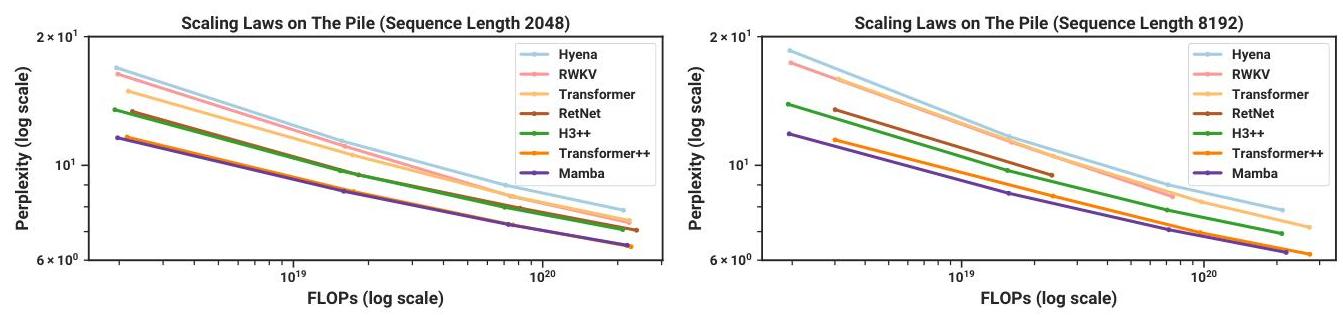
Language Modeling (The Pile)
| Model | Params | Perplexity (↓) | Throughput |
|---|---|---|---|
| Mamba-3B | 2.8B | best in class | 5x Transformer |
| Transformer (matched) | 2.8B | baseline | 1x |
| Transformer++ | 6.9B | ~= Mamba-3B | 0.2x (at 2x size) |
| RWKV-4 | 2.8B | worse | ~3x |
| H3 | 2.7B | worse | ~3x |
| Hyena | 2.7B | worse | ~3x |
Mamba-3B matches or exceeds Transformers twice its size while being 5x faster at inference. On zero-shot downstream evaluations, Mamba outperforms all open-source models of comparable training compute.
Scaling Properties
Mamba follows clean scaling laws: perplexity improves predictably with model size from 130M to 2.8B parameters. The scaling curve runs parallel to but below the Transformer curve, indicating consistent gains across scales rather than a regime-specific advantage.
Long-Context Performance
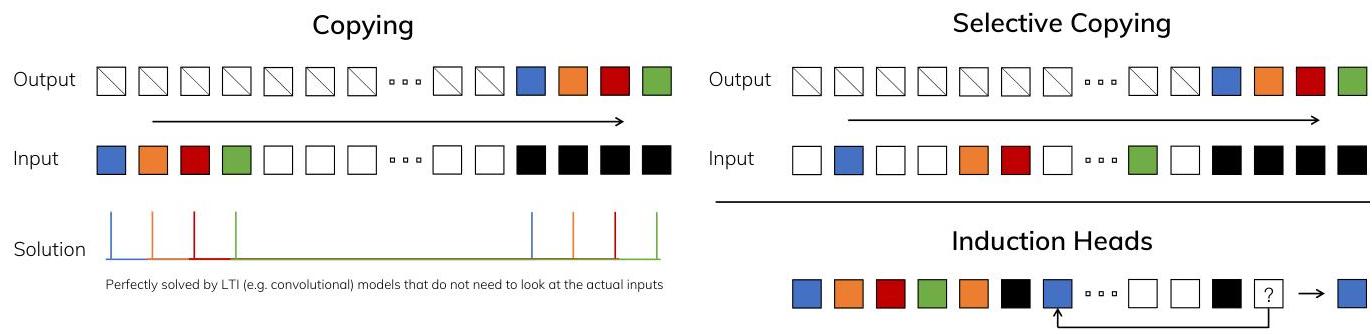
On synthetic tasks requiring long-range reasoning (selective copying, induction heads), Mamba solves problems that Transformers and prior SSMs fail on. On real sequences up to 1M tokens, Mamba's performance continues to improve without the quality degradation that Transformers exhibit beyond their training context length.
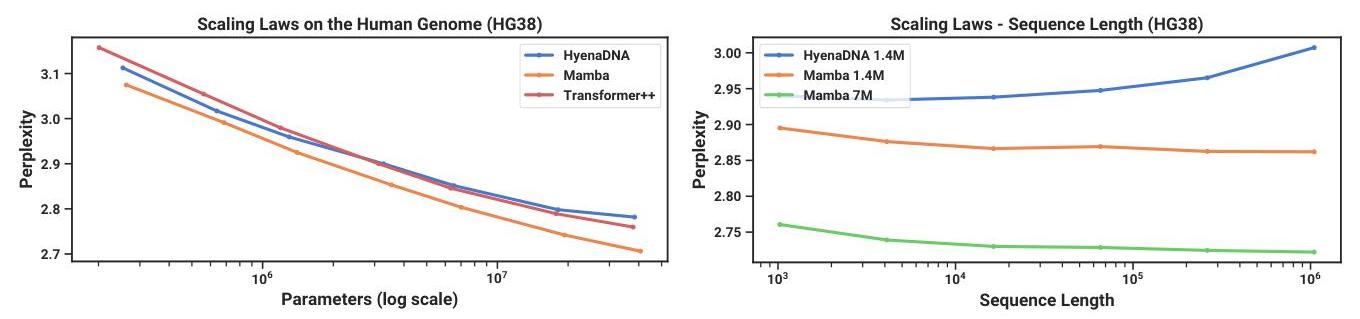
Audio and Genomics
On audio generation (SC09) and DNA sequence modeling (HG38 genome), Mamba achieves state-of-the-art with the same architecture used for language, demonstrating genuine cross-modal generality.
Limitations & Open Questions
- Retrieval and in-context learning: While Mamba excels at compression and long-range reasoning, pure SSMs may underperform attention for tasks requiring exact retrieval from context (e.g., looking up a specific key-value pair from thousands of tokens ago). This motivates hybrid architectures (Jamba, Zamba) that combine Mamba layers with sparse attention.
- Hardware specialization: The selective scan kernel is highly optimized for NVIDIA GPUs. Portability to other hardware (TPUs, custom ASICs) requires reimplementation, and the relative advantage over attention may shift on different hardware.
- Training stability at scale: The paper demonstrates clean scaling to 2.8B parameters, but behavior at 7B+ scale and beyond was not explored. Subsequent work (Mamba-2, state space duality) addresses this.
- Bidirectional modeling: Mamba is inherently causal (left-to-right). Bidirectional applications (BERT-style, encoder-decoder) require architectural modifications.
- Theoretical understanding: The connection between selectivity and the ability to model discrete data is empirically demonstrated but not fully theorized. Why does input-dependent discretization specifically unlock discrete-modality performance?
Connections
Related papers in the wiki: - Attention Is All You Need -- The Transformer architecture that Mamba aims to replace; Mamba achieves comparable quality with linear complexity vs. quadratic - Recurrent Neural Network Regularization -- RNN regularization; Mamba revives the recurrent paradigm with structured state spaces - Understanding Lstm Networks -- LSTM gating; Mamba's selection mechanism is a continuous-time analog of the forget/input gates - Scaling Laws For Neural Language Models -- Scaling laws; Mamba exhibits clean scaling behavior parallel to Transformers - Language Models Are Few Shot Learners -- GPT-3; Mamba targets the same language modeling regime at lower compute cost - Occmamba Semantic Occupancy Prediction With State Space Models -- Downstream application of Mamba to 3D occupancy prediction for autonomous driving - S4 Driver Scalable Self Supervised Driving Mllm With Spatio Temporal Visual Representation -- S4-Driver uses state space model concepts for driving - Machine Learning -- Broader ML foundations context - Foundation Models -- Mamba as an alternative foundation model backbone to the Transformer