Overview
UniSim addresses a fundamental bottleneck in embodied AI: the lack of high-fidelity, interactive simulators that generalize across domains. Rather than building separate simulators for robotics, driving, and human activity, UniSim learns a single universal simulator by framing real-world simulation as a conditional video generation problem. Given historical frames and diverse action inputs (text commands, camera controls, robotic actions), the model predicts plausible future video frames, effectively serving as a learned world model that can be queried interactively.
The core insight is that diverse datasets -- robotic manipulation data, internet video, indoor panorama scans, driving logs, and simulated environments -- can be unified under a single observation-prediction framework. By conditioning a video diffusion model on a flexible, unified action space (T5 text embeddings combined with normalized continuous control values), UniSim learns to simulate interactions across all these domains without domain-specific engineering. Domain identifiers prefix actions to disambiguate context (e.g., "Habitat: navigate to TV").
UniSim achieves strong results across several applications: training vision-language robot policies in simulation that transfer zero-shot to real hardware (3-4x better goal reduction than baselines), generating long-horizon manipulation sequences that maintain object permanence, improving video captioning (CIDEr from 15.2 to 46.23 on ActivityNet), and enabling RL training entirely within the learned simulator. The work was presented as an Oral at ICLR 2024 and has accumulated ~200 citations, establishing learned universal simulation as a viable paradigm for physical AI.
Key Contributions
- Introduces the first universal real-world simulator that handles multiple interaction types (robotic actions, camera movement, human activities, object manipulation) across diverse domains within a single model
- Frames real-world simulation as conditional video generation via a video diffusion architecture, enabling interactive rollouts through autoregressive frame prediction
- Demonstrates a unified action space design using T5 embeddings + continuous controls that absorbs heterogeneous action types from robotics, navigation, and human activity
- Shows that policies trained entirely in the learned simulator transfer zero-shot to real robots, achieving 3-4x better performance than baselines
- Establishes that data diversity (internet video, robotics, simulation, panoramas) improves generation quality across all domains through positive transfer
Architecture
┌──────────────────────────────────────────────────────────┐
│ UniSim Pipeline │
│ │
│ History Frames Actions (unified) │
│ [f_{t-2}, f_{t-1}, f_t] │ │
│ │ │ │
│ ▼ ▼ │
│ ┌─────────┐ ┌──────────────────────┐ │
│ │ Encoder │ │ T5 Text Embedding │ │
│ │(latent) │ │ + Normalized Controls│ │
│ └────┬────┘ │ + Domain ID prefix │ │
│ │ └──────────┬───────────┘ │
│ │ │ │
│ ▼ ▼ │
│ ┌────────────────────────────────────┐ │
│ │ 3D U-Net (5.6B params) │ │
│ │ ┌──────────────────────────────┐ │ │
│ │ │ Spatial Attn ◄─► Temporal Attn│ │ │
│ │ │ (interleaved layers) │ │ │
│ │ └──────────────────────────────┘ │ │
│ │ + Classifier-free guidance │ │
│ └──────────────┬─────────────────────┘ │
│ │ │
│ ▼ │
│ ┌──────────────────────────┐ │
│ │ Base: 16 frames @ 24x40 │ │
│ └────────────┬─────────────┘ │
│ ▼ │
│ ┌──────────────────────────┐ │
│ │ Spatial SR: 192x320 │ │
│ └────────────┬─────────────┘ │
│ │ │
│ └──► Autoregressive rollout ──► next step │
└──────────────────────────────────────────────────────────┘
Architecture / Method

UniSim is built on a video diffusion architecture using a 3D U-Net with interleaved temporal and spatial attention layers. The model generates video frames conditioned on:
- History frames: Previous observations provide temporal context
- Action conditioning: A unified action representation combining T5 text embeddings (for language commands and domain identifiers) with normalized continuous control values (for precise robotic actions, camera poses, etc.)
The generation operates hierarchically: - Base model: Generates 16 frames at low resolution (24x40 pixels) - Spatial super-resolution: Upsamples to 192x320 pixels - Autoregressive rollout: Predicted frames become history for subsequent predictions, enabling long-horizon simulation
Unified action space. The key design choice is encoding all actions through a shared representation. Text-based actions (e.g., "pick up the red cup") are encoded via T5 embeddings. Continuous actions (e.g., joint torques, camera deltas) are normalized and concatenated. Domain identifiers (e.g., "Habitat:", "RT-1:") prefix the action to provide dataset context, which is especially important for improving performance on low-data domains through positive transfer from data-rich domains.
Classifier-free guidance controls the strength of action conditioning during inference, allowing the model to balance between action fidelity and visual quality.

Training data. UniSim is trained on a diverse mixture of datasets: - Robotic manipulation data (Bridge Data, RT-1) - Human activity video (Ego4D, EPIC-KITCHENS, Something-Something V2) - Internet image-text data (LAION, ALIGN) - Indoor panorama scans (Matterport3D, for view synthesis) - Simulated environments (Habitat, Language Table)
The model has 5.6 billion parameters and was trained on 512 TPU-v3 units for 20 days.
Results
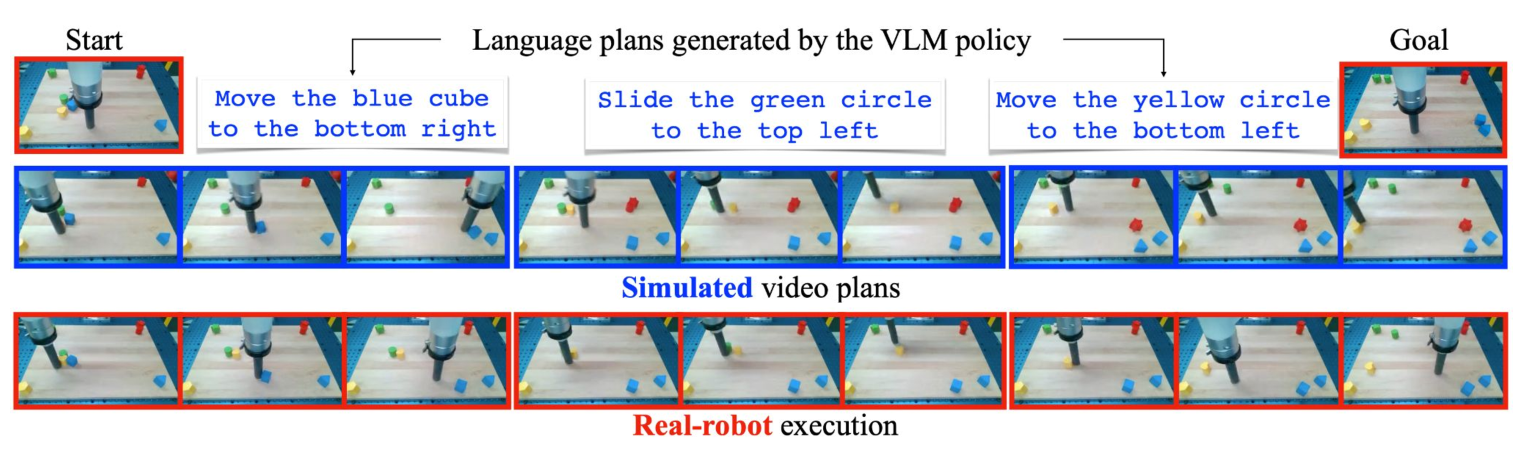
UniSim demonstrates strong performance across several application areas:
Simulated robot policy training. Vision-language policies trained in UniSim's simulation and transferred zero-shot to real hardware achieve 3-4x better goal reduction compared to baselines. This validates the simulator's physical fidelity for control-relevant details.
Long-horizon generation. UniSim generates coherent manipulation sequences that maintain object permanence and spatial relationships across extended rollouts -- a key requirement for planning applications.
Video captioning augmentation. Using UniSim to generate training data for video captioning improves CIDEr score from 15.2 to 46.23 on ActivityNet, demonstrating that the simulator produces semantically meaningful video that can augment downstream vision-language tasks.
RL in the learned simulator. Reinforcement learning agents trained entirely within UniSim's simulation show successful zero-shot sim-to-real transfer, establishing that the learned dynamics are accurate enough to support policy optimization.

| Application | Metric | UniSim | Baseline |
|---|---|---|---|
| Robot policy transfer | Goal reduction | 3-4x better | 1x |
| Video captioning (ActivityNet) | CIDEr | 46.23 | 15.2 |
| Sim-to-real RL | Zero-shot transfer | Successful | N/A |
Limitations & Open Questions
- Resolution and fidelity: Generation at 192x320 is far below the resolution needed for safety-critical driving applications; scaling to higher resolutions would significantly increase compute
- Temporal coherence at scale: Autoregressive rollout accumulates errors over long horizons; the paper does not quantify degradation rates systematically
- Action grounding precision: Whether the unified action space preserves fine-grained control accuracy across all domains (especially precise manipulation) versus being a jack-of-all-trades is not fully characterized
- Sim-to-real gap characterization: While zero-shot transfer is demonstrated, the systematic failure modes and domain gap analysis are limited
- Compute cost: 512 TPU-v3s for 20 days places this firmly in industry-scale research; reproducibility for academic labs is limited
- Evaluation breadth: Most quantitative results are on specific applications; a comprehensive benchmark across all claimed simulation capabilities is absent
Connections
Related papers in the wiki: - Cosmos World Foundation Model Platform For Physical Ai -- Cosmos (2025) extends the world foundation model paradigm with both diffusion and autoregressive architectures at larger scale (10K H100s), building on the vision UniSim established for universal physical simulation - Drivedreamer Towards Real World Driven World Models -- DriveDreamer applies diffusion-based world modeling specifically to driving; UniSim generalizes across domains - Denoising Diffusion Probabilistic Models -- UniSim's generation backbone builds on DDPM-style diffusion - Rt 1 Robotics Transformer For Real World Control At Scale -- RT-1 robotics data is part of UniSim's training mixture; UniSim provides simulation for training RT-style policies - Rt 2 Vision Language Action Models Transfer Web Knowledge To Robotic Control -- RT-2's vision-language-action paradigm is complementary; UniSim provides the simulation environment, RT-2 provides the policy architecture - Carla An Open Urban Driving Simulator -- CARLA is a hand-engineered driving simulator; UniSim represents the learned alternative - Occworld Learning A 3D Occupancy World Model For Autonomous Driving -- OccWorld learns world models in 3D occupancy space for driving; UniSim operates in pixel space across domains - Drive Occworld Driving In The Occupancy World -- Another occupancy-based world model for planning, domain-specific vs UniSim's universal approach - Foundation Models -- UniSim as a world foundation model paradigm - Robotics -- Sim-to-real transfer for robot policy training