DriveDreamer: Towards Real-World-Driven World Models for Autonomous Driving
Overview
DriveDreamer (ECCV 2024) is the first world model built entirely from real-world driving data, addressing fundamental limitations of prior approaches that relied on simulated environments. The system uses a latent-diffusion-based architecture called Auto-DM (Autonomous-driving Diffusion Model), built on Stable Diffusion v1.4, to learn controllable video generation from real driving scenarios, enabling both high-fidelity driving video synthesis and action-conditioned future prediction.
The two-stage training pipeline progressively builds understanding: Stage 1 ("Structured Traffic Comprehension") first learns to generate images from structured conditions (HD maps, 3D bounding boxes, text) and then extends to video; Stage 2 ("Future State Anticipation") introduces an ActionFormer module that predicts future HD maps and 3D boxes from action sequences, which are then decoded back into future videos and actions. On nuScenes, DriveDreamer achieves FID 14.9 / FVD 340.8 (vs DriveGAN's 27.8 / 390.8), matches AD-MLP's L2 trajectory error of 0.29m with a roughly 21% relative reduction in collision rate, and its synthetic data improves 3D detection (BEVFusion +3.0 mAP / +1.9 NDS; FCOS3D +0.7 mAP / +0.2 NDS).
Key Contributions
- First real-world-driven world model: Entirely trained on real driving data (nuScenes) rather than simulated environments
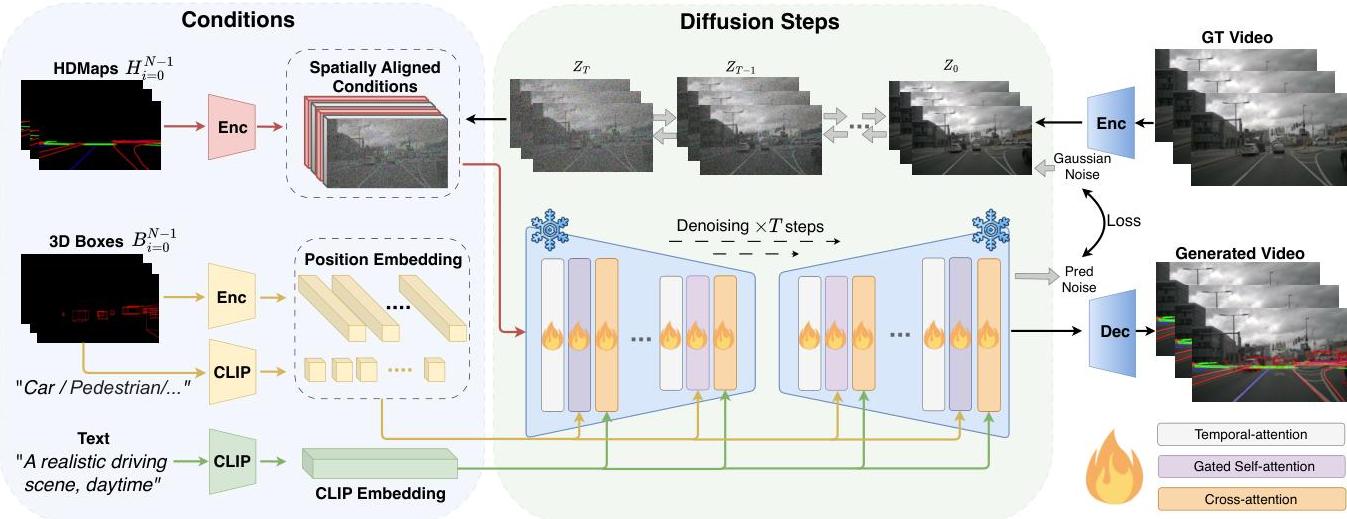
- Auto-DM architecture: Latent diffusion model (built on Stable Diffusion v1.4) with three conditional input types -- spatially aligned conditions (HD maps, concatenated with noisy latents after convolutional encoding), position conditions (3D bounding boxes, via MLP + Fourier embeddings and gated self-attention), and CLIP-embedded text prompts injected through cross-attention
- Two-stage progressive training: Stage 1 "Structured Traffic Comprehension" (image generation, then video generation by adding temporal attention); Stage 2 "Future State Anticipation" with an ActionFormer module that predicts future HD maps and 3D boxes from action sequences
- Controllable generation: Supports video generation conditioned on traffic layout, text descriptions, and driving actions simultaneously
- Data augmentation utility: Synthetic data from DriveDreamer measurably improves 3D object detection (BEVFusion +3.0 mAP / +1.9 NDS; FCOS3D +0.7 mAP / +0.2 NDS), demonstrating practical value beyond planning
Architecture / Method
┌──────────────────────────────────────────────────────────────┐
│ DriveDreamer (Auto-DM) │
│ latent diffusion, init from SD v1.4 │
│ │
│ Conditional Inputs: │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────────────┐ │
│ │ HD Maps │ │ 3D Bounding │ │ Text Prompts │ │
│ │ (lanes / │ │ Boxes + cat. │ │ ("rainy, night") │ │
│ │ dividers / │ │ │ │ │ │
│ │ crossings) │ │ │ │ │ │
│ └──────┬───────┘ └──────┬───────┘ └──────────┬───────────┘ │
│ │ conv enc. │ MLP + Fourier │ CLIP enc. │
│ │ concat w/ │ gated self-attn │ cross-attn │
│ │ noisy latent │ │ │
│ ▼ ▼ ▼ │
│ ┌───────────────────────────────────────────────────────┐ │
│ │ Diffusion U-Net Denoiser │ │
│ │ Noise z_t ──► ResBlocks + Attention ──► z_{t-1} │ │
│ │ Loss: MSE between predicted and added noise │ │
│ └───────────────────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ Generated Video Frame(s) │
│ │
│ ════════════════════════════════════════════════════════ │
│ Stage 1 "Structured Traffic Comprehension": │
│ Step 1: image gen (no temporal attn) │
│ Step 2: video gen (add temporal attn) │
│ Stage 2 "Future State Anticipation": │
│ ActionFormer predicts future HD maps & 3D boxes from │
│ action sequences (GRU + attention); fed back into Auto-DM │
│ to generate future videos + actions jointly │
│ (video: MSE/Gaussian, action: L1/Laplace) │
└──────────────────────────────────────────────────────────────┘

DriveDreamer's Auto-DM is a latent diffusion model (initialized from Stable Diffusion v1.4) that integrates three types of conditional inputs into the denoising process:
-
Spatially Aligned Conditions (HD maps): Lane boundaries, dividers, and pedestrian crossings are encoded through convolutional layers and concatenated with the noisy latent features during diffusion (rather than injected via cross-attention).
-
Position Conditions (3D bounding boxes): Vehicle and pedestrian 3D bounding boxes together with their category labels are processed through MLP layers and Fourier embeddings, and then integrated via gated self-attention so the generated scenes reflect object positions.
-
Text Prompts: Natural language descriptions of environmental attributes (sunny, rainy, night, traffic density) are converted to CLIP embeddings and injected through cross-attention layers to control scene style.
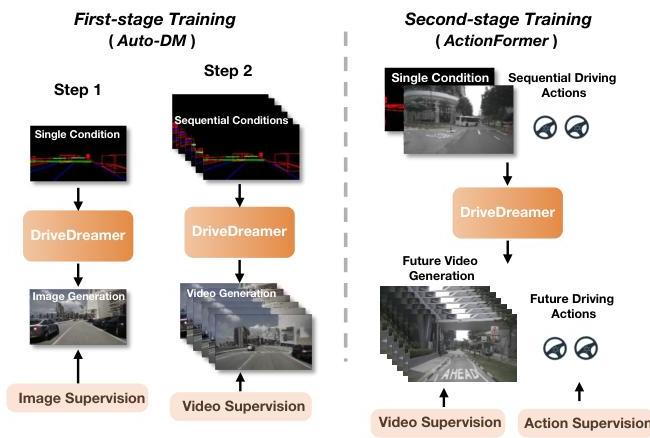
Stage 1 -- Structured Traffic Comprehension: Trained in two steps. Step 1 generates single images from HD maps, 3D boxes, and text, with temporal attention layers omitted. Step 2 adds temporal attention to extend the model to video generation, learning motion dynamics. The objective is the standard diffusion MSE between predicted and added noise.
Stage 2 -- Future State Anticipation: An ActionFormer module encodes the initial structured conditions (HD maps, 3D boxes) into a 1D latent space and, using attention together with GRU-based iterative updates, predicts future hidden states from input driving action sequences. These are decoded back into future HD maps and 3D boxes, which feed (together with a reference image and text prompt) back into the pre-trained Auto-DM to generate future videos and actions jointly. Video prediction uses an MSE (Gaussian) loss; action prediction uses an L1 (Laplace) loss.
This yields action-conditioned video rollouts suitable for planning.
Results
| Metric | DriveDreamer | Comparison |
|---|---|---|
| FID (video quality) | 14.9 | DriveGAN: 27.8 |
| FVD | 340.8 | DriveGAN: 390.8 |
| L2 trajectory error (m) | 0.29 | AD-MLP: 0.29 (tied) |
| Collision rate reduction | ~21% relative | vs. AD-MLP baseline |
| 3D detection aug. (BEVFusion) | +3.0 mAP / +1.9 NDS | -- |
| 3D detection aug. (FCOS3D) | +0.7 mAP / +0.2 NDS | -- |
- Video generation quality: Substantially outperforms DriveGAN on both FID (14.9 vs 27.8) and FVD (340.8 vs 390.8)
- Open-loop planning (nuScenes): 0.29m average L2 error, matching the AD-MLP baseline while cutting collision rate by roughly 21% relative
- Data augmentation: Adding DriveDreamer-generated synthetic data to 3D detection training improves BEVFusion by 3.0 mAP / 1.9 NDS and FCOS3D by 0.7 mAP / 0.2 NDS
- Controllability: Successfully generates diverse scenarios by varying text prompts and traffic layouts
- Dataset/hardware: Trained on nuScenes (700 training / 150 validation scenes) on A800 GPUs with AdamW

Limitations & Open Questions
- Open-loop evaluation only; closed-loop performance in reactive simulation is not validated
- HD map dependency limits applicability to map-free driving scenarios
- Video generation resolution and temporal horizon are constrained by computational cost
- The relationship between video generation quality and downstream planning performance is not fully characterized
- The main planning evaluation remains open-loop and map-conditioned; while the paper also presents separate multi-view image/video generation extensions, downstream surround-view planning utility is not fully characterized
Connections
- Autonomous Driving -- world models for autonomous driving
- Planning -- imagination-based planning via world model rollouts
- Prediction -- future scene prediction for driving
- Denoising Diffusion Probabilistic Models -- foundational diffusion model framework
- Nuscenes A Multimodal Dataset For Autonomous Driving -- primary evaluation dataset
- Vad Vectorized Scene Representation For Efficient Autonomous Driving -- E2E driving baseline
- End To End Learning For Self Driving Cars -- pioneering E2E driving approach