End to End Learning for Self-Driving Cars
Overview
This paper from NVIDIA, commonly known as "DAVE-2" or the "NVIDIA end-to-end driving paper," demonstrates that a single convolutional neural network can learn to map raw pixel inputs from a front-facing camera directly to steering commands for lane keeping on real roads. The CNN learns the entire processing pipeline -- from feature extraction through lane detection to steering control -- without any explicit intermediate representations, hand-crafted features, or modular decomposition. The system was trained on approximately 72 hours of real driving data and demonstrated autonomous driving on diverse road types including highways, residential streets, and unpaved roads.
The paper revives and modernizes the approach pioneered by Pomerleau's ALVINN (1989), which used a simple neural network to steer a vehicle. Where ALVINN used a shallow network with limited capacity, DAVE-2 leverages modern deep CNNs trained on large-scale real-world data with GPU acceleration. The key demonstration is that with sufficient data and model capacity, the end-to-end approach can handle the visual complexity of real driving without any explicit decomposition into perception and control subproblems.
This paper is historically significant as the canonical modern reference for camera-to-steering end-to-end driving. It catalyzed renewed interest in learned driving systems and directly motivated subsequent work on conditional imitation learning, which addressed its inability to handle intersections and navigation commands. While later work exposed the fundamental limits of the pure direct-control framing (no reasoning, no navigation, no multi-agent interaction), the core demonstration -- that a neural network can learn to drive from pixels -- remains foundational.
Key Contributions
- End-to-end learning from pixels to steering: Demonstrated that a single CNN can map raw camera images to steering angles without intermediate representations, hand-crafted features, or explicit lane detection
- Real-world training and deployment: Trained on 72 hours of real driving data (not simulation) and demonstrated on actual roads, including highway, rural, and suburban environments
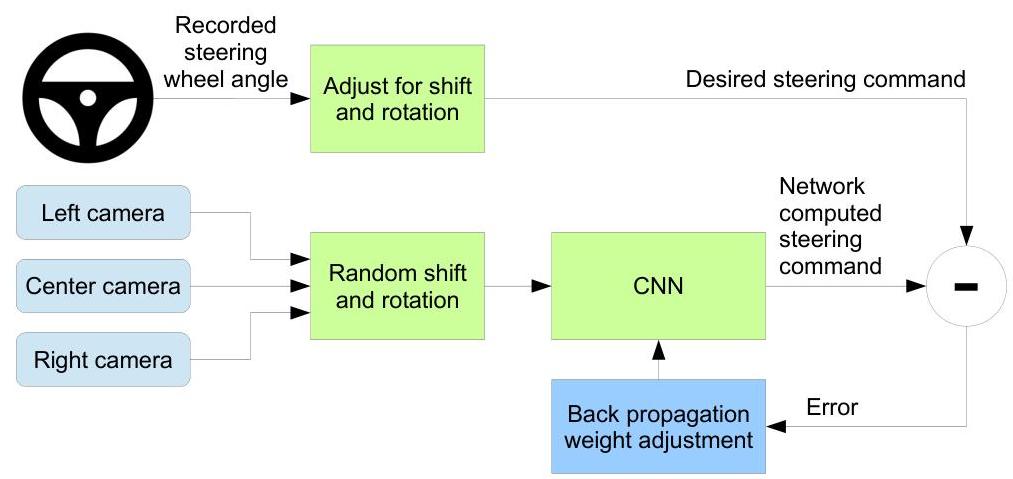
- Data augmentation via multi-camera setup: Used three cameras (center, left, right) with steering angle offsets for the side cameras, effectively tripling the training data and teaching the network to recover from off-center positions
- Visualization of learned features: Applied network visualization techniques to show that the CNN learns to detect road edges, lane markings, and other relevant features without explicit supervision
- Simplicity of approach: The entire system is a standard CNN (9 layers: normalization + 5 convolutional + 3 fully-connected + output) trained with MSE loss on the inverse turning radius (1/r) -- no complex architecture or training procedure required
Architecture / Method
┌─────────────────────────────────────────────────────────────────┐
│ DAVE-2 / NVIDIA E2E Architecture │
│ │
│ ┌───────────────────────────────────────┐ │
│ │ 3 Cameras: Left / Center / Right │ │
│ │ (side cameras get adjusted steering │ │
│ │ labels for recovery training) │ │
│ └───────────────────┬───────────────────┘ │
│ ▼ │
│ ┌───────────────────────────────────────┐ │
│ │ Input: 66 x 200 x 3 (YUV) │ │
│ └───────────────────┬───────────────────┘ │
│ ▼ │
│ ┌───────────────────────────────────────┐ │
│ │ Normalization Layer │ │
│ ├───────────────────────────────────────┤ │
│ │ Conv1: 24 filters, 5x5, stride 2 │ │
│ │ Conv2: 36 filters, 5x5, stride 2 │ │
│ │ Conv3: 48 filters, 5x5, stride 2 │ │
│ │ Conv4: 64 filters, 3x3, stride 1 │ │
│ │ Conv5: 64 filters, 3x3, stride 1 │ │
│ ├───────────────────────────────────────┤ │
│ │ Flatten │ │
│ ├───────────────────────────────────────┤ │
│ │ FC1: 1164 neurons │ │
│ │ FC2: 100 neurons │ │
│ │ FC3: 50 neurons │ │
│ ├───────────────────────────────────────┤ │
│ │ Output: 1 (1/r, inverse turning │ │
│ │ radius) │ │
│ └───────────────────────────────────────┘ │
│ │
│ Loss: MSE(predicted 1/r, actual 1/r) │
│ Inference: ~30 FPS on NVIDIA Drive PX │
└─────────────────────────────────────────────────────────────────┘
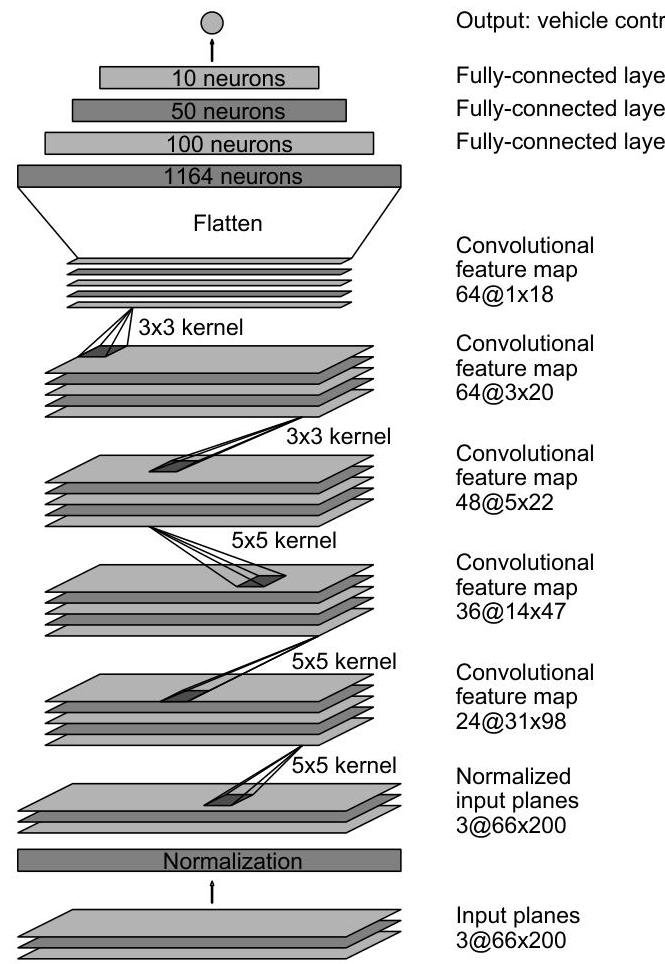
The DAVE-2 network architecture is a relatively straightforward CNN for its era. The input is a single camera image (66x200 pixels, YUV color space) captured from the front of the vehicle. The network consists of a normalization layer, five convolutional layers (with 24, 36, 48, 64, and 64 filters respectively, using strided convolutions for downsampling), followed by three fully-connected layers (with 1164, 100, and 50 neurons) and a final output neuron, totaling approximately 250,000 parameters across roughly 27 million connections. The output is a single scalar representing the inverse turning radius (1/r), rather than steering angle directly, which avoids mathematical singularities associated with straight-line driving where radius approaches infinity.
The training data collection uses three cameras mounted behind the windshield: one center, one shifted left, and one shifted right. The center camera provides ground-truth steering labels directly from the human driver. The left and right cameras are paired with adjusted steering angles that add a small correction toward the center, teaching the network to recover from off-center positions. This is a simple but effective form of data augmentation that addresses the distribution shift problem: during autonomous driving, small errors accumulate and push the vehicle off the demonstrated trajectory, so the network needs to learn recovery behaviors.
Training uses standard supervised learning with mean squared error loss between predicted and actual inverse turning radius (1/r) values. Random shifts and rotations are applied as additional data augmentation. The system outputs only the steering angle; throttle and brake are controlled by a separate adaptive cruise control system.
During deployment, the network runs at approximately 30 FPS on an NVIDIA Drive PX computer. The system was tested on a variety of roads in New Jersey, including multi-lane highways, single-lane roads with and without lane markings, and unpaved roads. An autonomy metric tracks the fraction of time the system drives without human intervention.
Results

- The system achieved 98% autonomous steering time during typical drives and demonstrated zero interventions over 10 miles on a multi-lane highway, with the network learning to stay in lane on diverse road types without explicit lane detection
- Visualization of internal features showed the network automatically learned to detect lane markings, road edges, and other driving-relevant visual features, validating that end-to-end learning discovers meaningful intermediate representations
- The multi-camera augmentation strategy was critical for stable driving -- without the left/right camera recovery examples, the system was prone to drift and lane departure
- The approach generalized across road types (highway, rural, suburban) and conditions (daylight, shadows, curves) without requiring separate models or explicit condition handling
- Real-time inference at 30 frames per second was achieved on NVIDIA hardware, demonstrating the practical feasibility of neural network-based steering for automotive deployment using less than 100 hours of training data
Limitations & Open Questions
- Outputs only steering angle -- does not handle acceleration, braking, or full vehicle control, limiting the scope to lane-keeping only
- No mechanism for handling intersections, turns, or navigation decisions -- the system can only follow the current lane, which Codevilla et al. later addressed with conditional imitation learning
- No multi-agent reasoning or interaction modeling -- the system treats other vehicles as static obstacles to avoid rather than agents with intentions