Learning by Cheating
Overview
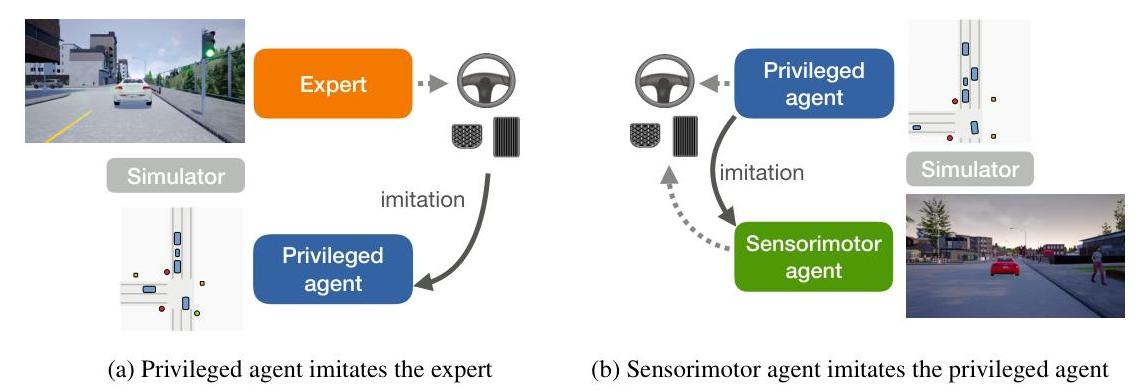
Learning by Cheating introduces a two-stage training paradigm for end-to-end autonomous driving that has become one of the most influential design patterns in the field. The core idea is to decompose the difficult problem of learning to drive from camera images into two easier problems: first, train a "privileged" agent that has access to ground-truth simulator state (bird's-eye-view layout, exact positions of all actors, traffic light states), and second, train a sensorimotor agent that uses only camera images to imitate the privileged agent's behavior. The privileged agent "cheats" by using information unavailable at deployment time, but it provides a much cleaner learning signal for the vision-based student.
The insight is that the primary difficulty in end-to-end driving is not learning the correct driving policy given perfect perception, but rather learning to extract driving-relevant information from raw sensor data. By separating these challenges, each stage becomes tractable. The privileged agent learns an effective driving policy from compact, noise-free state representations. The sensorimotor agent then learns to map camera images to the same intermediate representations, effectively using the privileged agent as an automatic labeling oracle.
This teacher-student decomposition became the standard training paradigm for CARLA-based driving research and influenced nearly all subsequent work on end-to-end driving in simulation. The privileged agent pattern appears in TransFuser, Roach, TCP, InterFuser, and many other systems, making this paper one of the most practically influential in autonomous driving research.
Key Contributions
- Two-stage privileged training paradigm: Decompose learning to drive into (1) learning a driving policy from privileged state information, and (2) learning a perception system that maps camera images to the same representation space
- Privileged agent with BEV state access: A compact agent that receives the ground-truth bird's-eye-view layout of the scene and learns an effective driving policy using imitation learning from the autopilot
- Sensorimotor agent as student: A vision-based agent trained to imitate the privileged agent's intermediate representations and outputs, using the privileged agent as a teacher rather than directly imitating the expert autopilot
- Demonstration of representation learning as the bottleneck: Shows that driving policy learning is relatively easy given good representations, and the hard problem is extracting those representations from images
- CARLA benchmark results: Achieves strong driving performance on the CARLA NoCrash benchmark, substantially outperforming prior end-to-end approaches
Architecture / Method
┌─────────────────────────────────────────────────────────┐
│ Stage 1: Train Privileged Agent (has ground truth) │
│ │
│ ┌───────────────────┐ ┌──────────────┐ │
│ │ BEV Rasterized │ │ CARLA Expert │ │
│ │ Image (GT state: │ │ Autopilot │ │
│ │ roads, vehicles, │ │ Demonstrations│ │
│ │ traffic lights, │ └──────┬───────┘ │
│ │ route) │ │ │
│ └────────┬──────────┘ │ │
│ ▼ ▼ │
│ ┌────────────────┐ Behavioral Cloning Loss │
│ │ CNN Encoder │◄──────────────────────── │
│ │ + Command Head │ │
│ └────────┬───────┘ │
│ ▼ │
│ ┌────────────────┐ │
│ │ Waypoints ──► PID ──► (steer, throttle, brake) │
│ └────────────────┘ │
└─────────────────────────────────────────────────────────┘
┌─────────────────────────────────────────────────────────┐
│ Stage 2: Train Sensorimotor Agent (camera only) │
│ │
│ ┌────────────────┐ ┌────────────────────┐ │
│ │ Front Camera │ │ Privileged Agent │ │
│ │ RGB Image │ │ (teacher / oracle) │ │
│ └────────┬───────┘ └─────────┬──────────┘ │
│ ▼ │ │
│ ┌────────────────┐ │ │
│ │ CNN Encoder │ Imitation │ │
│ │ (vision-based) │◄─── Loss ────┘ │
│ │ + Command Heads │ (match teacher's │
│ │ (all branches) │ representations │
│ └────────┬───────┘ + waypoints) │
│ ▼ │
│ ┌────────────────┐ │
│ │ Waypoints ──► PID ──► (steer, throttle, brake) │
│ └────────────────┘ │
│ │
│ + Online DAgger refinement with privileged agent │
│ + White-box supervision (all command branches) │
└─────────────────────────────────────────────────────────┘
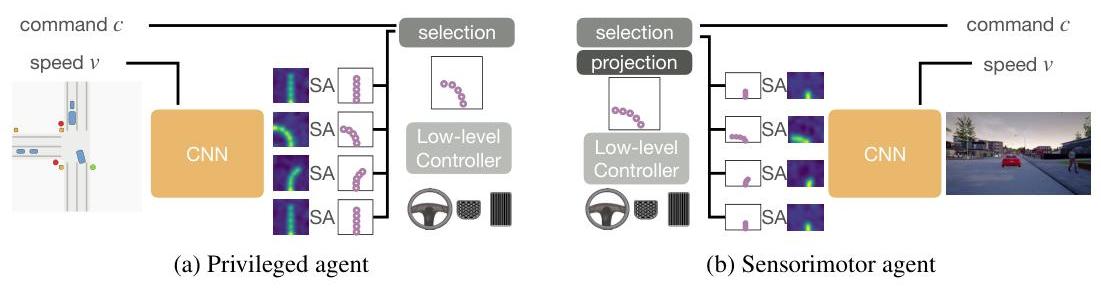
The method proceeds in two stages with distinct architectures.
Stage 1 (Privileged Agent): The privileged agent receives a bird's-eye-view (BEV) rasterized image of the scene as input. This BEV image encodes the road layout, lane markings, positions and orientations of all vehicles and pedestrians, traffic light states, and the planned route. From this compact representation, a relatively simple convolutional network learns to predict waypoints along the desired trajectory. The agent is trained via behavioral cloning on demonstrations from the CARLA autopilot (the built-in rule-based expert driver). Because the input is a clean, noise-free top-down view with complete information, the policy learning problem is straightforward and the agent achieves near-expert performance.
Stage 2 (Sensorimotor Agent): The sensorimotor agent receives only front-facing camera images as input. Training follows two phases:
Offline Imitation: Initial training uses camera images paired with privileged agent waypoint predictions.
Online Refinement: Further improvement through simulator driving with adaptive supervision from the privileged agent (similar to DAgger / Dataset Aggregation). A critical innovation is "white-box supervision," where the sensorimotor agent predicts all conditional branches simultaneously (for all navigation commands: turn left/right, go straight, follow lane), providing richer learning signals and acting as data augmentation.
Both agents use similar architectures with convolutional neural networks processing input, command-specific prediction heads for different navigation commands, and waypoint prediction modules. Predicted waypoints convert to low-level controls (steering, throttle, brake) via PID controller, allowing agents to focus on waypoint prediction rather than direct control.
Data augmentation through rotation and shifting of bird's-eye view images simulates trajectory noise and improves robustness during privileged agent training.
Results
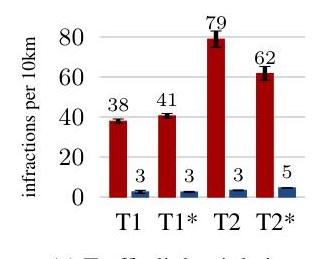
- 100% success rate on all CARLA benchmark tasks across navigation conditions with varying weather and traffic density
- NoCrash benchmark records: Significant outperformance over all methods including Conditional Imitation Learning (CILRS), Conditional Affordance Learning (CAL), and Modular Policy (MP), especially in dense traffic scenarios
- Substantially reduced infractions (collisions, traffic light violations) versus existing approaches, with dramatically fewer infractions across all measurements compared to CILRS
- The privileged agent achieves near-expert performance (close to the autopilot), confirming that policy learning from clean state representations is the easy part
- The sensorimotor agent recovers a substantial fraction of the privileged agent's performance, demonstrating effective knowledge distillation from BEV representations to camera-based perception
- Ablation findings: White-box supervision (access to all conditional branches) provides significant advantages over black-box supervision (only selected branch); online training substantially improves performance via covariate shift addressing; combined white-box supervision and online training yields optimal results
- Analysis shows that most failure cases trace to perception failures rather than policy failures, validating the decomposition hypothesis
- The approach generalizes across weather conditions and town layouts within CARLA
Limitations & Open Questions
- The approach is validated only in CARLA simulation -- real-world transfer remains untested, and the BEV-to-camera distillation may not work as cleanly with real sensor noise and domain gaps
- The privileged agent's BEV representation assumes access to ground-truth information that may not perfectly correspond to what any real perception system could extract
- The two-stage training does not allow end-to-end gradient flow from the driving objective through the perception system, potentially leaving perceptual accuracy on the table