End-to-end Driving via Conditional Imitation Learning
Overview
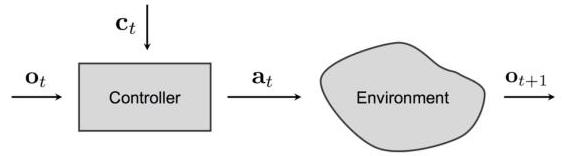
This paper introduces conditional imitation learning for end-to-end autonomous driving, where a neural network policy is conditioned on a discrete high-level command (turn left, turn right, go straight, follow lane) to resolve the fundamental multimodal action ambiguity at intersections. The same visual scene at an intersection can correspond to three or more correct actions depending on navigation intent, and without conditioning on intent, a learned policy will average these modes and produce erratic or incorrect behavior.
The key insight is that perception alone is insufficient for determining the correct action at decision points. The model takes three inputs: a front-facing camera image, low-dimensional measurements (primarily vehicle speed), and a categorical high-level command. It outputs a continuous 2D control vector: steering angle and acceleration (combined throttle/brake). By adding command conditioning, the policy becomes controllable and responsive to navigation intent. The paper introduces a branched architecture with separate fully-connected heads per command, gated by command selection, which outperforms the naive approach of concatenating the command with visual features. This conditional policy formulation -- F(i, m, c) = A_c(J(i, m)) -- became a foundational design pattern for the field.
This paper is foundational for the entire VLA driving research trajectory. The branched command-conditioned architecture became a durable design pattern that persists in modern VLA models, with the discrete four-word command vocabulary simply replaced by natural language instructions. The progression from CIL's discrete commands to LMDrive's natural language to EMMA's full prompt-driven interface is a direct evolutionary line, making this paper the proto-VLA for autonomous driving.
Key Contributions
- Branched command-conditioned architecture: Separate FC heads per high-level command (left/right/straight/follow), gated by command selection, outperforms naive command-input concatenation
- Conditional policy formulation: F(i, m, c) = A_c(J(i, m)), where the CNN encoder and measurement MLP jointly produce features J(i, m), and the command-specific branch A_c produces a 2D control output (steering + acceleration) -- the first clean formalization of intent-conditioned driving with multi-modal inputs
- Data augmentation with noise injection to handle the distribution shift problem inherent to imitation learning, where the policy encounters states not seen during expert demonstration
- Dual validation in simulation and real world: Evaluated in CARLA simulator and on a physical 1/5-scale truck in residential environments
- Identification of the multimodal output problem: Clearly demonstrated that identical visual inputs at intersections cause oscillation and wrong turns without intent conditioning
Architecture / Method
┌─────────────────────────────────────────────────────────────────┐
│ Branched Conditional Imitation Learning │
│ │
│ ┌───────────────┐ ┌───────────────┐ │
│ │ Front Camera │ │ Measurements │ │
│ │ Image (i) │ │ m (speed...) │ │
│ └───────┬───────┘ └───────┬───────┘ │
│ ▼ ▼ │
│ ┌───────────────┐ ┌───────────────┐ │
│ │ 8-layer CNN │ │ MLP module │ │
│ │ I(i) │ │ M(m) │ │
│ └───────┬───────┘ └───────┬───────┘ │
│ └─────────┬─────────┘ │
│ ▼ │
│ ┌───────────────────┐ │
│ │ Joint repr J(i,m) │ │
│ └─────────┬─────────┘ │
│ │ │
│ ┌─────────┴──────────────────────────┐ │
│ ▼ ▼ ▼ ▼ │
│ ┌─────────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ A_left │ │ A_right │ │ A_str. │ │ A_follow │ │
│ │ Turn Left │ │ T. Right │ │ Straight │ │ Lane │ │
│ │ FC Branch │ │ FC Branch│ │ FC Branch│ │ FC Branch│ │
│ └──────┬──────┘ └────┬─────┘ └────┬─────┘ └────┬─────┘ │
│ │ │ │ │ │
│ └─────────────┴──── c ─────┴─────────────┘ │
│ ▼ │
│ (command selects branch) │
│ ▼ │
│ ┌───────────────────────────┐ │
│ │ Output: steering + accel │ │
│ │ (2D continuous action) │ │
│ └───────────────────────────┘ │
└─────────────────────────────────────────────────────────────────┘
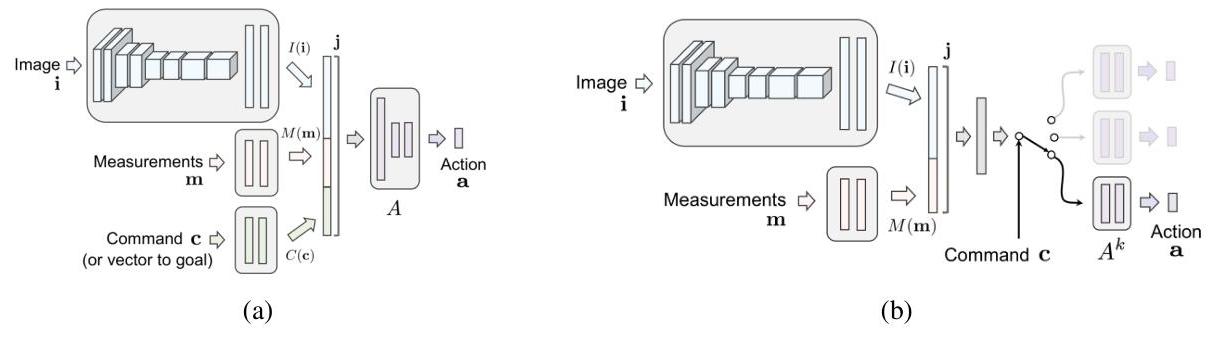
The architecture consists of two main components: a perception/measurement module and a set of command-conditional control modules. The perception module is an 8-layer convolutional network that takes a single front-facing camera image and extracts visual features. In addition to the image, the network also ingests low-dimensional measurements -- most importantly vehicle speed -- through a separate MLP. The visual features and measurement features are jointly combined into a shared representation J(i, m) before being passed to the command-conditional branches.
The control module uses a branched design. Rather than a single output head, there are separate fully-connected network branches for each high-level command: turn left, turn right, go straight, and follow lane. At inference time, the navigation system provides the current command c, and only the corresponding branch f_c is activated to produce the control output: a 2D action vector consisting of steering angle and a combined acceleration value (throttle/brake). The full policy is F(i, m, c) = A_c(J(i, m)). This branching allows each command-specific head to specialize in the action distribution for that maneuver type, avoiding the averaging problem that occurs when all maneuvers share parameters.
The paper compares this branched architecture against two alternatives: (1) an unconditional model with no command input, which must handle all maneuvers with a single output head, and (2) a command-input model that concatenates a one-hot command encoding with the visual features before a shared output head. The branched design outperforms both.
Training uses standard behavioral cloning on expert demonstrations from CARLA, with two key augmentation strategies. First, viewpoint perturbation: cameras are placed at offset positions during data collection, with labels adjusted to steer back toward the center, creating recovery examples. Second, noise injection: small random perturbations are applied to the expert's controls during data collection, creating slightly off-policy states that the model learns to correct from.
Results
CARLA Simulator Performance
| Method | Town 1 Success | Town 2 Success |
|---|---|---|
| Branched conditional model | 88% | 64% |
| Command input architecture | 78% | 52% |
| Non-conditional baseline | 20% | 26% |
Physical Robot Tests
| Configuration | Missed Turns | Human Interventions/Run |
|---|---|---|
| Branched model | 0% | 0.67 |
| Without noise injection | 24.4% | 8.67 |
| Without data augmentation | 73% | 39 |
- Conditional model significantly outperforms unconditional baselines at intersections in CARLA simulation, resolving the oscillation and wrong-turn failure modes that plague unconditional policies
- Branched architecture outperforms command-input architecture: separate heads per command allow each branch to specialize in one maneuver type, yielding cleaner action predictions with higher success rates
- Real-world transfer demonstrated: successfully trained a 1/5-scale truck to drive in residential environments following high-level commands, showing the approach is not limited to simulation
- Noise injection mitigates distribution shift: adding perturbation noise during training substantially improves robustness during autonomous execution, with the model learning to recover from small deviations
- Ablation studies confirm that both the branched architecture and noise injection are independently important, with their combination providing the best performance
Limitations & Open Questions
- The "language" interface is a predefined 4-word vocabulary, not free-form natural language -- the gap from discrete commands to natural language instructions remained open for years
- Inherits fundamental imitation learning distribution shift and generalization issues despite noise injection -- compounding errors in long-horizon driving remain problematic
- No reasoning or explanation capability -- the policy is a black box that maps (image, command) to controls, providing no interpretability