DriveMLM: Aligning Multi-Modal LLMs with Behavioral Planning States
Overview
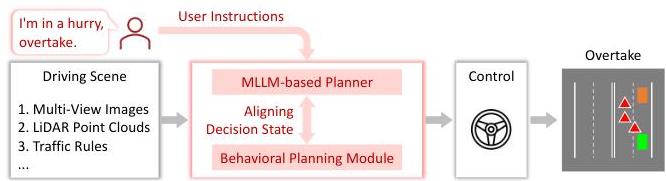
DriveMLM proposes using a multimodal LLM as a plug-and-play behavioral planning module within existing autonomous driving stacks (Apollo, Autoware), rather than replacing the entire pipeline end-to-end. The core innovation is aligning high-level MLLM decisions with standardized behavioral planning states that downstream motion planners can execute directly, bridging the gap between language model outputs and vehicle control.
Most driving VLMs aim to be end-to-end replacements for the entire driving stack, but DriveMLM takes a pragmatically different approach. Existing modular AD systems have battle-tested perception and control modules developed over years of engineering. Rather than discarding this investment, DriveMLM inserts an LLM between perception outputs and the motion planner, using it specifically for behavioral planning -- the high-level decision-making about what maneuver to execute. The LLM receives multimodal inputs (camera images, LiDAR point clouds) and produces behavioral planning states plus natural language explanations.
Key Contributions
- LLM as plug-and-play behavioral planning module: Standardizes behavioral planning states using an off-the-shelf motion planning module and trains a multimodal LLM to output driving decisions plus explanations that interface with existing AD stacks
- Compatible with Apollo/Autoware: Designed for integration with industry-standard AD frameworks, not requiring end-to-end replacement
- Behavioral state abstraction: Defines an intermediate representation bridging LLM output and motion planner input -- speed decisions [KEEP, ACCELERATE, DECELERATE, STOP] and path decisions [FOLLOW, LEFT_CHANGE, RIGHT_CHANGE, LEFT_BORROW, RIGHT_BORROW]
- Efficient data collection strategy: 280 hours of driving data across 50,000 routes with automatic decision annotation from expert trajectories, avoiding costly manual labeling
- Driving score improvements on CARLA demonstrating the viability of the modular LLM integration approach
Architecture / Method
┌──────────────────────────────────────────────────────────────┐
│ DriveMLM: LLM as Plug-and-Play Planner │
│ │
│ ┌───────────────────────────────────────────────────┐ │
│ │ Multi-Modal Tokenizer │ │
│ │ │ │
│ │ ┌──────────┐ ┌──────────────┐ ┌────────────┐ │ │
│ │ │ Multi-cam│ │ LiDAR Points │ │ System Msg │ │ │
│ │ │ Images │ │ │ │ (decisions)│ │ │
│ │ └────┬─────┘ └──────┬───────┘ └─────┬──────┘ │ │
│ │ ▼ ▼ │ │ │
│ │ ┌─────────┐ ┌────────────┐ │ │ │
│ │ │CLIP ViT │ │ SST LiDAR │ │ │ │
│ │ │+ Temporal│ │ Encoder │ │ │ │
│ │ │CrossAttn │ │(CLIP-align)│ │ │ │
│ │ └────┬─────┘ └─────┬──────┘ │ │ │
│ │ └───────┬────────┘ │ │ │
│ │ ▼ │ │ │
│ │ Visual Tokens │ │ │
│ └───────────────┬──────────────────────────┘ │ │
│ ▼ │ │
│ ┌───────────────────────────────────────────┐ │ │
│ │ LLaMA-7B MLLM Decoder │ │ │
│ │ Input: [visual tokens] + [system msg] │ │ │
│ └──────────────────┬────────────────────────┘ │ │
│ ▼ │ │
│ ┌─────────────────────────────────────┐ │ │
│ │ Output: │ │ │
│ │ Speed: KEEP|ACCEL|DECEL|STOP │ │ │
│ │ Path: FOLLOW|LEFT|RIGHT|BORROW │ │ │
│ │ + Natural Language Explanation │ │ │
│ └──────────────────┬──────────────────┘ │ │
│ ▼ │ │
│ ┌──────────────────────┐ │ │
│ │ Apollo / Autoware │ │ │
│ │ Motion Planner │──► Vehicle Control │ │
│ └──────────────────────┘ │ │
└──────────────────────────────────────────────────────────────┘
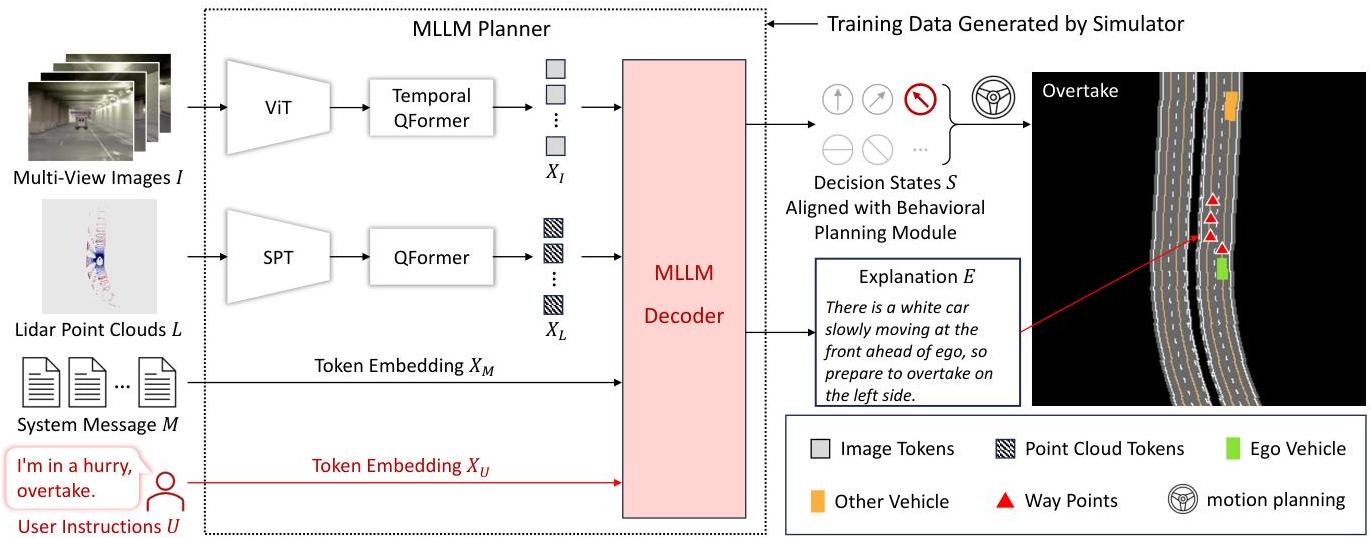
DriveMLM's architecture consists of three main components.
Behavioral Planning States Alignment: The framework defines two decision categories: Speed Decisions [KEEP, ACCELERATE, DECELERATE, STOP] and Path Decisions [FOLLOW, LEFT CHANGE, RIGHT CHANGE, LEFT BORROW, RIGHT BORROW]. These are incorporated into system messages fed to the MLLM planner, ensuring predictions converge into predefined decisions executable by downstream motion planning and control modules. At each timestep, one speed and one path decision are generated.
Multi-Modal MLLM Planner: Processes diverse sensor inputs through a multi-modal tokenizer and MLLM decoder (LLaMA-7B). Temporal multi-view images are processed using a CLIP vision encoder, with features projected to match text token dimensions and a temporal cross-attention mechanism fusing current and historical image features. LiDAR point clouds are aligned via an image-LiDAR CLIP model using a frozen ViT-L/14 image encoder alongside a randomly initialized single-stride sparse transformer (SST) LiDAR encoder, trained to maximize cosine similarity between LiDAR and image features. A specially designed system message template guides the model, with training using standard cross-entropy loss with next token prediction.
Efficient Data Collection Strategy: 280 hours of driving data (50,000 routes) across 30 challenging scenarios in 8 CARLA maps with diverse environmental conditions. Speed and path decision states are automatically inferred from expert driving trajectories using hand-crafted rules, avoiding costly manual annotation. Explanation generation uses GPT-3.5 to expand variety and richness of human-annotated initial explanations.
Results

| Method | Driving Score | Route Completion | Decision Accuracy |
|---|---|---|---|
| DriveMLM | 76.1 | 98.1% | 75.23% |
| Apollo | 71.4 | - | 18.53% |
| ThinkTwice | 70.9 | - | - |
| Interfuser | 68.3 | - | - |
| LLaVA 1.5 | - | - | 22.92% |
| InstructBLIP | - | - | 17.92% |
- Decision prediction accuracy: 75.23% compared to LLaVA 1.5 (22.92%), InstructBLIP (17.92%), and Apollo (18.53%)
- Explanation quality: Highest NLP scores including BLEU-4 (40.46), CIDEr (124.91), METEOR (56.54)
- Closed-loop CARLA Town05 Long: Driving Score 76.1 (highest among all methods, surpassing Apollo at 71.4), Route Completion 98.1%, Miles Per Intervention 0.96
- Complex scenario handling: System employs intelligent strategies like "borrow lane" maneuvers instead of simply stopping; correctly yields to emergency vehicles demonstrating enhanced common sense reasoning
- Zero-shot generalization: Initial evaluations on nuScenes revealed ability to generalize to real-world driving scenes without additional training, achieving zero-shot decision accuracy of 0.395
- Interactive capabilities: Successfully interprets natural language instructions (e.g., "I am in a hurry, please overtake") while accepting or reasonably rejecting user requests based on real-time traffic conditions
- Practical integration demonstrated with Apollo-style frameworks, confirming plug-and-play compatibility
Limitations & Open Questions
- Simulator-based validation only -- no real-world deployment evidence, which is the ultimate test for the "LLM in the stack" approach
- Behavioral state abstraction may lose information compared to end-to-end approaches -- the discrete vocabulary of maneuvers cannot capture the full continuous space of driving behaviors
- The gap between LLM-generated behavioral states and robust low-level control in safety-critical edge cases remains unaddressed