Hydra-MDP: End-to-End Multimodal Planning with Multi-Target Hydra-Distillation
:page_facing_up: Read on arXiv
Overview
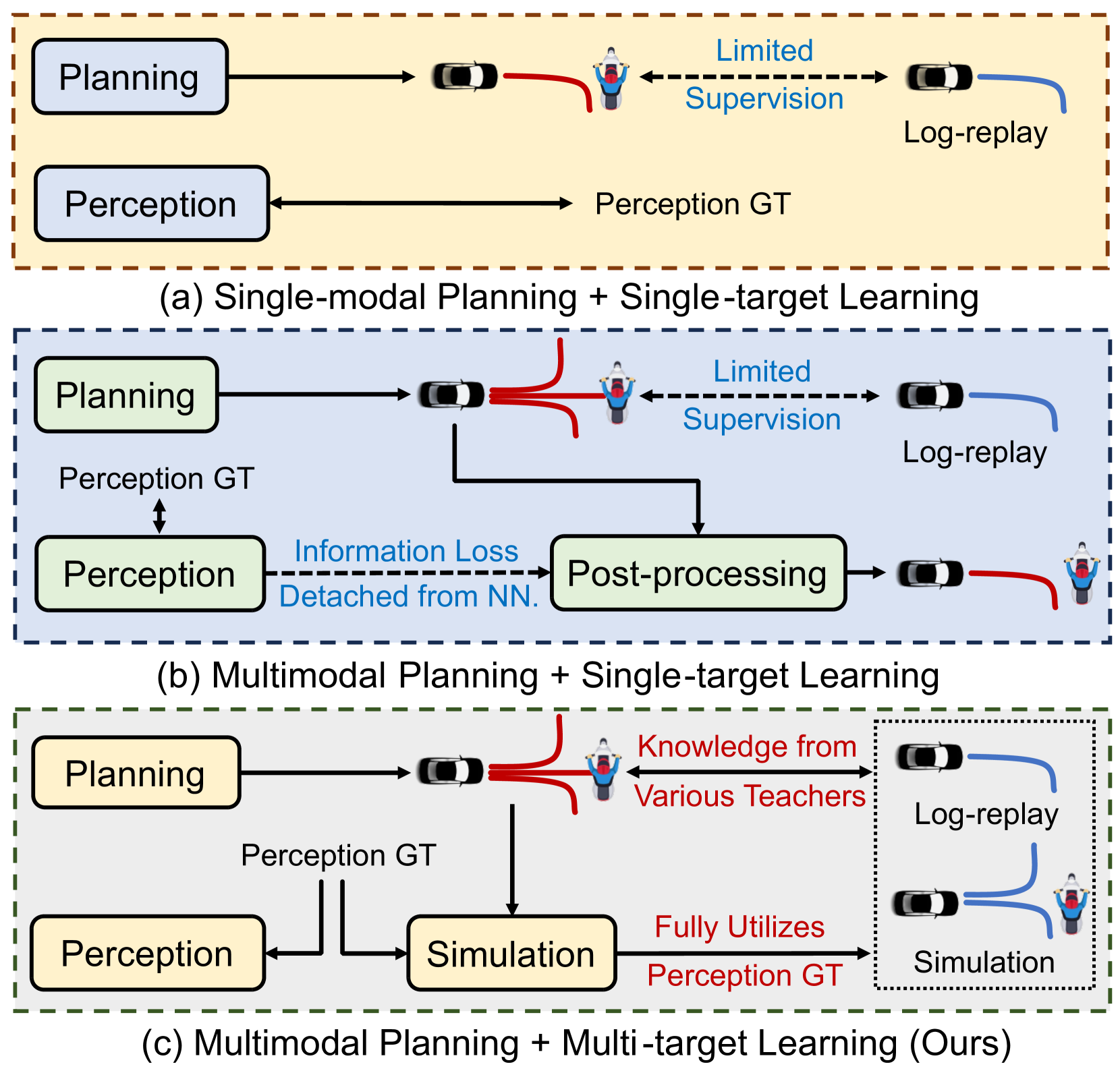
Hydra-MDP addresses a fundamental limitation of imitation learning for autonomous driving: standard behavior cloning learns only to mimic human demonstrations, with no explicit optimization for safety-critical metrics like collision avoidance, drivable area compliance, or time-to-collision. The paper proposes a multi-target knowledge distillation framework where multiple "teacher" signals -- both human demonstrations and rule-based safety evaluators -- are distilled into a single student network through specialized prediction heads (the "Hydra" heads).
The core insight is that autonomous driving evaluation is inherently multi-dimensional (safety, compliance, comfort, progress), and collapsing these into a single scalar score before distillation loses critical information. Instead, Hydra-MDP trains the student to predict each metric independently via separate Hydra Prediction Heads, then selects the trajectory that optimizes a composite score at inference time. This preserves the multi-objective structure of the problem through the entire pipeline.
Hydra-MDP won first place in the NAVSIM challenge, achieving 86.5 PDM Score with the best single model and up to 91.0 with larger vision backbones. The results demonstrate strong scalability -- unlike prior work suggesting diminishing returns, performance consistently improves with larger backbones and richer planning vocabularies.
Key Contributions
- Multi-target Hydra distillation: Separate prediction heads for each closed-loop metric (NC, DAC, TTC, Comfort, EP), avoiding information loss from score aggregation
- Planning vocabulary via K-means clustering: Discretizes continuous trajectory space into 4,096–8,192 representative trajectory clusters (selected from 700,000 expert trajectories via K-means), converting planning into a scoring/selection problem
- Offline simulation for teacher labels: Runs ground-truth-perception simulation for every trajectory candidate in the vocabulary, generating per-metric supervision without online simulation
- Elimination of non-differentiable post-processing: The neural network directly learns the relationship between sensor observations and safety metrics, enabling end-to-end gradient flow
- Scaling behavior: Demonstrates consistent improvements with larger vision backbones and planning vocabularies, contradicting prior claims of diminishing returns
Architecture / Method
┌──────────────────────────────────────────────────────────────────┐
│ HYDRA-MDP PIPELINE │
│ │
│ ┌──────────┐ ┌──────────┐ │
│ │ Camera │ │ LiDAR │ │
│ └────┬─────┘ └────┬─────┘ │
│ │ │ │
│ ▼ ▼ │
│ ┌──────────────────────────────┐ │
│ │ TransFuser Perception │ │
│ │ (image + LiDAR fusion) │ │
│ │ via transformer layers │ │
│ └──────────────┬───────────────┘ │
│ │ Environmental tokens │
│ ▼ │
│ ┌──────────────────────────────────────────────────────────┐ │
│ │ Trajectory Scoring (over Planning Vocabulary) │ │
│ │ 4,096–8,192 candidates (K-means of 700K expert trajs) │ │
│ │ │ │
│ │ ┌────────┐ ┌────────┐ ┌────────┐ ┌────────┐ ┌────────┐│ │
│ │ │NC Head │ │DAC Head│ │TTC Head│ │C Head │ │EP Head ││ │
│ │ │(collisn)│ │(drivbl)│ │(time- │ │(comfrt)│ │(progrs)││ │
│ │ │ │ │ │ │ to-col)│ │ │ │ ││ │
│ │ └───┬────┘ └───┬────┘ └───┬────┘ └───┬────┘ └───┬────┘│ │
│ │ │ │ │ │ │ │ │
│ │ └──────────┴──────┬───┴──────────┴──────────┘ │ │
│ │ ▼ │ │
│ │ Composite Score per Trajectory │ │
│ └──────────────────────┬───────────────────────────────────┘ │
│ ▼ │
│ ┌──────────────────────┐ │
│ │ Best Trajectory │ │
│ │ (argmax composite) │ │
│ └──────────────────────┘ │
│ │
│ TEACHER SUPERVISION (training only): │
│ ┌──────────────────────────────────────────────────────┐ │
│ │ Offline Sim (GT perception) ──► per-metric labels │ │
│ │ Human demos ──► expert trajectory targets │ │
│ └──────────────────────────────────────────────────────┘ │
└──────────────────────────────────────────────────────────────────┘
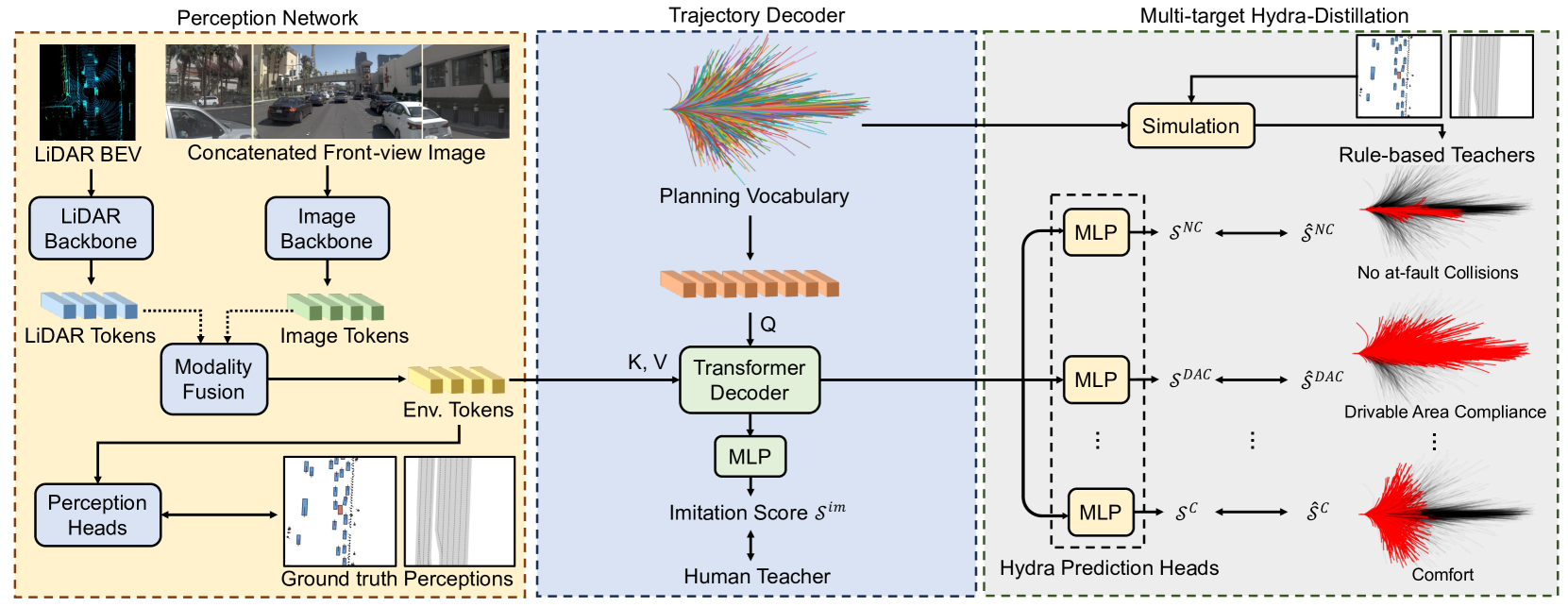
Perception Network
Hydra-MDP builds on the TransFuser architecture for sensor fusion. The perception network processes front-view camera images and LiDAR point clouds through separate backbones (e.g., ResNet or larger vision models), fusing them via transformer layers to produce environmental tokens encoding rich semantic information about the driving scene.
Planning Vocabulary
Rather than predicting continuous trajectories directly, Hydra-MDP discretizes the action space using a planning vocabulary created by K-means clustering of ~700,000 expert trajectories from the training dataset down to 4,096–8,192 representative trajectories (V4096 and V8192 variants). Each trajectory in the vocabulary consists of 40 timesteps of (x, y, heading) coordinates over a 4-second planning horizon. At inference, the model scores every trajectory in the vocabulary and selects the highest-scoring one.
Multi-Target Hydra Heads
The trajectory decoder uses a set of specialized prediction heads -- one per evaluation metric:
| Head | Metric | Description |
|---|---|---|
| NC Head | No at-fault Collisions | Predicts collision-free probability |
| DAC Head | Drivable Area Compliance | Predicts road boundary compliance |
| TTC Head | Time to Collision | Predicts time-to-collision safety margin |
| C Head | Comfort | Predicts jerk/acceleration comfort score |
| EP Head | Ego Progress | Predicts forward progress along route |
Each head is trained with supervision from offline simulation: for every trajectory in the planning vocabulary, a rule-based simulator with ground-truth perception evaluates the trajectory against each metric, producing per-metric labels. The student model learns to predict these scores from raw sensor inputs.
Teacher-Student Paradigm
- Human teacher: Provides expert trajectory demonstrations from log-replay data
- Rule-based teachers: Offline simulation models that evaluate trajectory candidates against closed-loop metrics using ground truth perception
The key advantage of this paradigm is that teachers operate with perfect perception (ground truth), while the student must learn from noisy real sensor observations. This separation forces the student to develop robust perception-to-planning mappings that generalize to real-world conditions.
Results
Hydra-MDP achieved first place in the NAVSIM challenge with state-of-the-art performance across all metrics:
| Method | PDM Score | NC (%) | DAC (%) | TTC | Comfort | EP |
|---|---|---|---|---|---|---|
| Hydra-MDP (best single) | 86.5 | 98.3 | 96.0 | -- | -- | -- |
| Hydra-MDP (large backbone) | 91.0 | -- | -- | -- | -- | -- |
| TransFuser baseline | 78.0 | 97.2 | 89.1 | -- | -- | 76.0 |
| Single aggregated score distillation | 80.2 | -- | -- | -- | -- | -- |
Key findings from ablations:
- Multi-target vs. single-score distillation: Distilling a single aggregated score instead of per-metric scores causes significant performance degradation, confirming the multi-target approach is essential
- Planning vocabulary size: Larger vocabularies consistently improve all metrics, highlighting the benefit of richer trajectory candidate sets
- Backbone scaling: Performance scales strongly with larger vision backbones (up to 91.0 PDM), contradicting prior claims of diminishing returns in E2E driving
Limitations & Open Questions
- Dependence on planning vocabulary: The discrete trajectory set is fixed at training time; novel maneuvers outside the vocabulary cannot be generated
- Offline simulation fidelity: Teacher labels come from rule-based simulation with GT perception -- the quality of distillation depends on simulator fidelity
- LiDAR dependency: The TransFuser backbone requires LiDAR input, limiting deployment to LiDAR-equipped vehicles
- Closed-loop validation: While winning NAVSIM (a pseudo-simulation benchmark), full closed-loop and real-world deployment results are not reported
- Vocabulary scalability: As vocabulary size grows, inference cost increases linearly; efficient retrieval or hierarchical scoring could improve scalability
Connections
Related papers in the wiki:
- Transfuser Imitation With Transformer Based Sensor Fusion For Autonomous Driving -- Hydra-MDP builds on the TransFuser architecture for its perception backbone
- Learning By Cheating -- The privileged distillation paradigm (teacher with GT, student with sensors) that Hydra-MDP extends to multi-target distillation
- Diffusiondrive Truncated Diffusion Model For End To End Autonomous Driving -- Alternative approach to multimodal trajectory generation using truncated diffusion (88.1 PDMS on NAVSIM)
- Goalflow Goal Driven Flow Matching For Multimodal Trajectory Generation -- Flow matching approach achieving 90.3 PDMS on NAVSIM, competing paradigm to vocabulary-based scoring
- Navsim V2 Pseudo Simulation For Autonomous Driving -- The evaluation benchmark (NAVSIM) where Hydra-MDP won first place
- Sparsedrive End To End Autonomous Driving Via Sparse Scene Representation -- SparseDriveV2 also uses factorized trajectory vocabulary scoring, achieving 92.0 PDMS
- Dima Distilling Multi Modal Large Language Models For Autonomous Driving -- Another distillation approach for E2E driving, distilling MLLM reasoning rather than metric scores
- Driveadapter Breaking The Coupling Barrier Of Perception And Planning In End To End Autonomous Driving -- Related teacher-student paradigm for decoupling perception and planning
- Planning -- Broader context on planning paradigms in autonomous driving
- End To End Architectures -- Taxonomy of E2E approaches; Hydra-MDP is a Type 3 jointly trained system with vocabulary-based planning