VectorNet: Encoding HD Maps and Agent Dynamics From Vectorized Representation
Overview
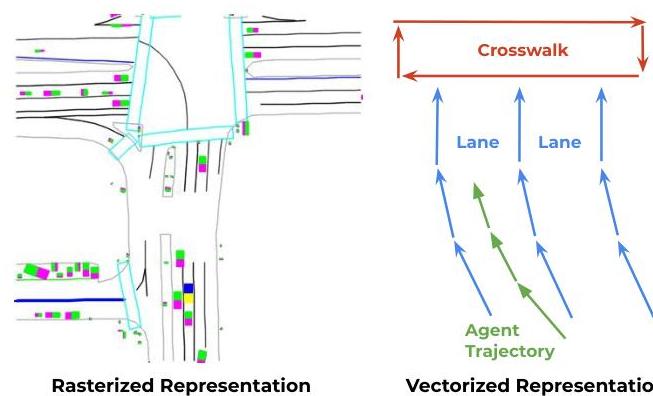
VectorNet (Gao et al., Waymo/Google, CVPR 2020) is a foundational paper that moved motion prediction and map encoding away from rasterized image-based representations toward vectorized, graph-based structures. Prior to VectorNet, the dominant approach for encoding HD maps and agent dynamics was to rasterize everything into multi-channel bird's-eye-view images and process them with CNNs. This was computationally expensive, threw away structural information (a lane boundary is naturally a polyline, not a pixel grid), and scaled poorly with map size.
VectorNet represents all scene elements -- lane boundaries, crosswalks, traffic signals, agent trajectories -- as sets of polylines, where each polyline is a sequence of vectors (directed line segments). A hierarchical graph neural network first encodes local structure within each polyline (a subgraph of vectors) and then models global interactions between polylines (a graph of polyline-level nodes). This unified representation treats maps and agents identically, using the same vector-based encoding for both static geometry and dynamic trajectories.
The paper's influence was substantial: VectorNet shifted the motion prediction community toward vectorized representations, directly inspiring subsequent work including LaneGCN, TNT, DenseTNT, and eventually the VAD planning paper. The key insight -- that structured, sparse representations preserve geometric and topological information while being more efficient than dense rasterization -- became a guiding principle for autonomous driving perception and prediction architectures.
Key Contributions
- Unified vectorized representation: Represents all scene elements (map lanes, crosswalks, traffic lights, agent trajectories) as sets of polylines composed of directed vectors, providing a unified encoding for both static and dynamic elements
- Hierarchical graph neural network: Two-level GNN architecture where the subgraph network encodes local structure within each polyline and the global interaction graph models relationships between polylines
- Elimination of rasterized rendering: Removes the need to render HD maps and agent histories into multi-channel BEV images, avoiding information loss from discretization and reducing computational cost
- Self-supervised auxiliary task: Uses a node completion pre-training objective (predict a masked polyline node from context) to learn better representations, analogous to masked language modeling in NLP
- State-of-the-art motion prediction: Achieves top results on the Argoverse motion forecasting benchmark at the time of publication
Architecture
┌──────────────────────────────────────────────────────────┐
│ VectorNet Architecture │
│ │
│ Scene Elements (unified vector representation): │
│ ┌───────────┐ ┌───────────┐ ┌───────────┐ │
│ │ Lane Bdry │ │ Crosswalk │ │Agent Traj │ ... │
│ │ v1─v2─v3 │ │ v1─v2─v3 │ │ v1─v2─v3 │ │
│ └─────┬─────┘ └─────┬─────┘ └─────┬─────┘ │
│ │ │ │ │
│ ▼ ▼ ▼ │
│ ┌───────────────────────────────────────────┐ │
│ │ Polyline Subgraph Networks (local GNN) │ │
│ │ 3 layers message passing + max-pool │ │
│ │ │ │
│ │ v1,v2,v3 ──► p_j (polyline node) │ │
│ └──────┬────────────┬───────────┬───────────┘ │
│ │ │ │ │
│ ▼ ▼ ▼ │
│ [p_1] [p_2] [p_3] ... [p_N] │
│ │ │ │ │ │
│ └────────────┴───────────┴──────────┘ │
│ │ │
│ ▼ │
│ ┌───────────────────────────────────────────┐ │
│ │ Global Interaction Graph │ │
│ │ (fully-connected, multi-head self-attn) │ │
│ │ Each polyline attends to all others │ │
│ └──────────────────┬────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌───────────────────────────────┐ │
│ │ MLP Prediction Head │ │
│ │ Single future trajectory │ │
│ │ (L2 regression loss) │ │
│ └───────────────────────────────┘ │
└──────────────────────────────────────────────────────────┘
Architecture / Method
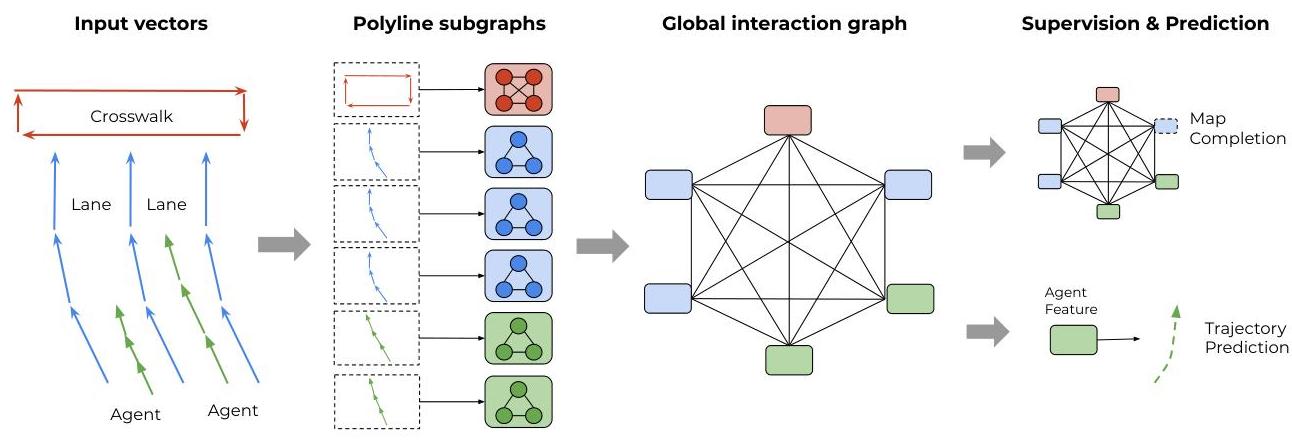
VectorNet processes the driving scene in two stages. Stage 1 -- Polyline Subgraph Encoding: Each scene element (a lane segment, an agent trajectory, a crosswalk boundary) is represented as an ordered sequence of vectors v_i = (d_x, d_y, attributes), where d_x, d_y are the displacement from the previous point and attributes include semantic type, timestamp (for trajectories), and other features. Within each polyline, a local subgraph GNN (3 layers of message passing with max-pool aggregation) encodes the vectors into a single polyline-level feature node p_j. This captures the internal structure of each element (lane curvature, trajectory shape).
Stage 2 -- Global Interaction Graph: The polyline-level nodes {p_j} form a fully-connected global graph. A global interaction network (multi-head self-attention, similar to a transformer) processes these nodes, allowing each polyline to attend to all others. This captures long-range spatial relationships: an agent's trajectory attends to nearby lane boundaries, traffic signals, and other agents' trajectories.
Prediction Head: The output node for the target agent is passed through an MLP to predict a single future trajectory. VectorNet does not include a multimodal decoder with multiple hypotheses or winner-take-all loss — that capability came in later work (TNT, DenseTNT).
Self-supervised Pre-training: A node completion objective randomly masks a polyline node and trains the network to predict its features from the remaining context, similar to BERT's masked language modeling. This pre-training improves downstream prediction performance.
Results
| Resource | VectorNet | ResNet-18 Baseline | Reduction |
|---|---|---|---|
| Parameters | 72K | 246K | 70% |
| FLOPs | 0.041 GFLOPs | 10.56 GFLOPs | 99.6% |
- State-of-the-art on Argoverse motion forecasting: Achieves top minADE and minFDE metrics at the time of publication, outperforming CNN-based rasterized approaches
- Computational efficiency: Over 200x fewer FLOPs than the best rasterized CNN baseline for a single agent (10.56G vs. 0.041G, about 99.6% fewer) while achieving better prediction accuracy, because vectorized representations scale with the number of scene elements rather than spatial resolution
- Self-supervised pre-training improves prediction: The node completion pre-training objective improves final prediction metrics by 5-8%, demonstrating that the graph structure supports effective self-supervised learning
- Unified encoding validated: Using the same vector representation for both maps and agents outperforms architectures that encode them with different modules, confirming the value of a unified representation
- Scalability to large scenes: Performance remains stable as the number of map elements increases, unlike rasterized approaches where computational cost grows with map area at fixed resolution
- Ablations validate hierarchy: Both the subgraph (local) and global interaction networks are necessary; removing either degrades performance significantly
Limitations & Open Questions
- The fully-connected global graph has O(N^2) complexity in the number of polylines, which can become expensive in dense urban scenes with hundreds of lane segments and agents
- The vector representation loses some fine-grained geometric information (road surface texture, elevation changes) that rasterized representations can capture through image channels
- The prediction head is a simple MLP predicting a single trajectory; multimodal prediction (multiple hypotheses with confidence scores) is not part of this paper and was addressed in subsequent work (TNT, DenseTNT)
- No explicit incorporation of traffic rules or semantic constraints beyond what the GNN learns implicitly from data