Overview
As pretrained language models grow to hundreds of billions of parameters, full fine-tuning -- updating every weight for each downstream task -- becomes prohibitively expensive in storage, memory, and deployment complexity. LoRA (Low-Rank Adaptation) addresses this by freezing the pretrained weight matrices and injecting trainable low-rank decomposition matrices into each transformer layer. The core insight is that the weight updates during adaptation have a low intrinsic rank, so a full-rank gradient update is unnecessary.
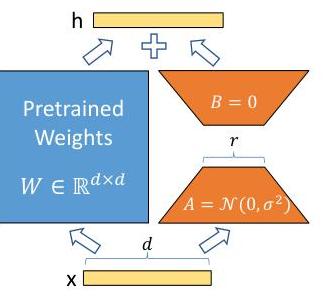
Concretely, for a pretrained weight matrix W_0 in R^{d x k}, LoRA parameterizes the update as Delta-W = BA, where B in R^{d x r} and A in R^{r x k} with rank r << min(d, k). During forward pass, the output becomes h = W_0 x + (alpha/r) * B A x. The pretrained weights W_0 remain frozen; only A and B are trained. At inference time, BA can be merged into W_0 with no additional latency -- a critical advantage over adapter-based methods that add sequential modules and increase inference depth.
Applied to GPT-3 175B, LoRA reduces trainable parameters by 10,000x (from 175B to ~4.7M at rank 4) and GPU memory requirements by ~3x compared to full fine-tuning, while matching or exceeding the performance of full fine-tuning, adapters, and prefix-tuning on benchmarks including WikiSQL, MNLI, and SAMSum. LoRA has since become the default adaptation method for large language models and is now a foundational technique across NLP, computer vision, and robotics -- including driving VLA systems that fine-tune frozen VLMs for embodied control.
Key Contributions
- Low-rank reparameterization of weight updates: Instead of updating W directly, parameterize Delta-W = BA with rank r, reducing trainable parameters by orders of magnitude while preserving expressiveness
- Zero inference overhead: Unlike adapters or prefix-tuning, LoRA's low-rank matrices merge into the pretrained weights at deployment, adding no latency or architectural changes
- Task-switching via matrix swaps: Different downstream tasks require only swapping the small A and B matrices while sharing the same frozen base model, enabling efficient multi-task serving
- Empirical validation at extreme scale: Demonstrated on GPT-3 175B (the largest model tested for parameter-efficient fine-tuning at the time), showing the approach scales gracefully
- Low-rank structure of adaptation: Provided evidence that weight updates during fine-tuning occupy a low-dimensional subspace, with effective ranks as low as 1-2 for many weight matrices
Architecture / Method
┌───────────────────────────────────────────────────┐
│ LoRA: Low-Rank Adaptation │
│ │
│ Input x │
│ │ │
│ ┌─────┴─────┐ │
│ │ │ │
│ ▼ ▼ │
│ ┌──────┐ ┌──────┐ │
│ │ W_0 │ │ A │ r x k (Gaussian init) │
│ │ (d x k)│ │(rank r)│ │
│ │ FROZEN │ └──┬───┘ │
│ │ │ ▼ │
│ │ │ ┌──────┐ │
│ │ │ │ B │ d x r (zero init) │
│ │ │ │(rank r)│ │
│ └──┬─────┘ └──┬───┘ │
│ │ │ │
│ │ h = W_0·x + (α/r)·B·A·x │
│ │ │ │
│ └─────┬─────┘ │
│ ▼ │
│ Output h │
│ │
│ At inference: W = W_0 + (α/r)·BA (merged, no │
│ extra latency) │
│ │
│ Typical r = 4-8, trainable params: ~0.003% of W_0│
└───────────────────────────────────────────────────┘
Core mechanism
For each weight matrix W_0 in the pretrained model, LoRA adds a parallel low-rank path:
h = W_0 x + (alpha / r) * B A x
where: - W_0 in R^{d x k} is frozen (no gradient updates) - A in R^{r x k} is initialized from a random Gaussian distribution - B in R^{d x r} is initialized to zero (so Delta-W = BA = 0 at the start of training) - r is the rank (typically 1-64; the paper finds r = 4-8 sufficient for most tasks) - alpha is a scaling hyperparameter (typically set equal to the first r used, then kept fixed)
The zero initialization of B ensures that training begins from the pretrained model's behavior, providing stable optimization from the start.
Where to apply LoRA
The paper experiments with applying LoRA to different attention weight matrices in the transformer: W_q, W_k, W_v, and W_o. Key findings:
- Adapting both W_q and W_v together yields the best results
- Adapting all four matrices (W_q, W_k, W_v, W_o) with rank r = 2 outperforms adapting only W_q with rank r = 8, despite the same total parameter count -- suggesting that distributing rank across more matrices is preferable to concentrating it in fewer
- The paper does not apply LoRA to MLP layers, though subsequent work (QLoRA, etc.) has shown benefits from doing so
Rank analysis
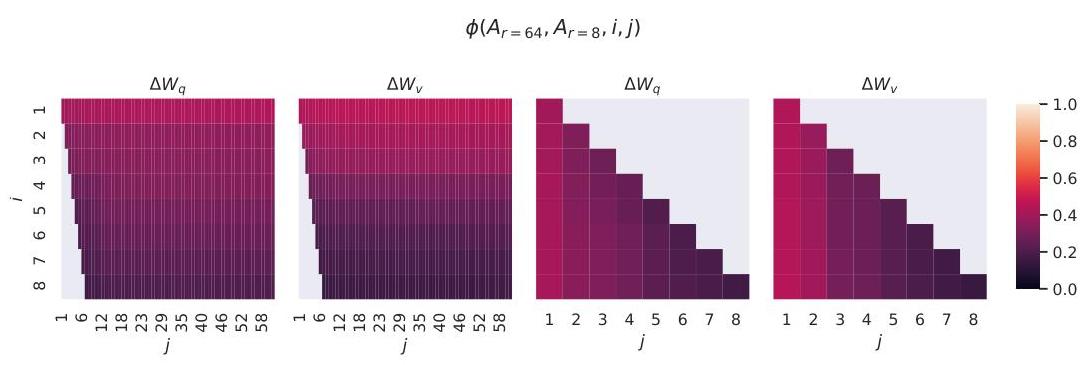
Analysis of the learned Delta-W matrices reveals that the top singular values contain most of the information. The paper computes the normalized subspace similarity between LoRA solutions learned at different ranks and finds high overlap, confirming that the useful adaptation directions are genuinely low-dimensional. At r = 1, performance is surprisingly competitive on many tasks, and increasing r beyond 4-8 yields diminishing returns.
Comparison with other methods
| Method | Trainable params (GPT-3) | Inference latency | Task switching | Performance |
|---|---|---|---|---|
| Full fine-tuning | 175B (100%) | Baseline | Requires separate model copies | Best reference |
| Adapter (Houlsby) | 7.1M-40M | +20-30% overhead | Moderate | Competitive |
| Prefix-tuning | 0.1% | Baseline | Easy | Good on generation tasks |
| LoRA (r=4) | 4.7M (0.003%) | Baseline (merged) | Swap A, B matrices | Matches full FT |
Results
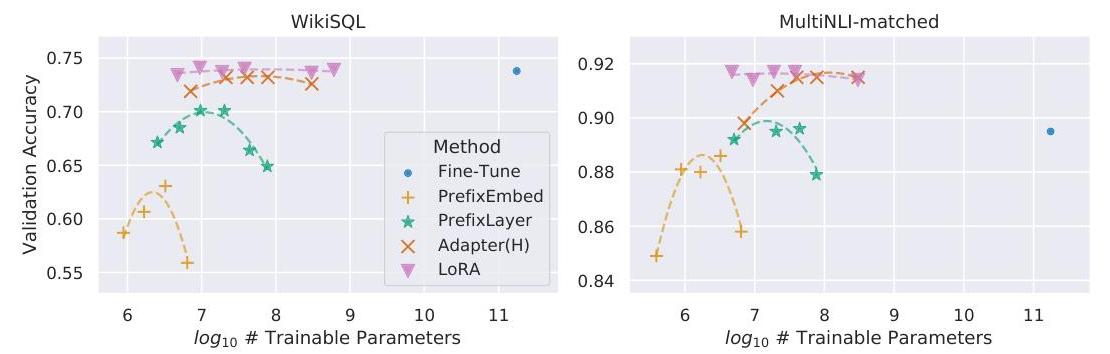
GPT-3 175B results
| Method | WikiSQL Acc | MNLI-m Acc | SAMSum R1 | SAMSum R2 | SAMSum RL | Trainable Params |
|---|---|---|---|---|---|---|
| Full fine-tuning | 73.8 | 89.5 | 52.0 | 28.0 | 44.5 | 175.0B |
| BitFit | 71.3 | 91.0 | 51.3 | 27.6 | 49.1 | 14.2M |
| Prefix-embed | 63.1 | 88.6 | 49.2 | 25.6 | 46.7 | 3.5M |
| Prefix-layer | 70.1 | 89.7 | 50.8 | 27.5 | 48.5 | 20.2M |
| Adapter (H) | 73.2 | 91.5 | 53.0 | 28.9 | 50.8 | 7.1M |
| LoRA (r=4) | 73.4 | 91.7 | 53.8 | 29.8 | 45.9 | 4.7M |
LoRA matches or exceeds all baselines on GPT-3 175B with the fewest trainable parameters, achieving the best results on MNLI and SAMSum while being competitive on WikiSQL.
RoBERTa and DeBERTa results
On RoBERTa-base (GLUE benchmark), LoRA with r = 8 outperforms full fine-tuning (87.2 vs 86.4 with only 0.3M vs 125M trainable parameters). On RoBERTa-large, performance is similarly competitive. On DeBERTa XXL (1.5B parameters), LoRA achieves 91.1% on MNLI, matching the fine-tuned result.
Efficiency gains
- Parameter reduction: 10,000x fewer trainable parameters than full fine-tuning on GPT-3
- Memory reduction: ~3x less GPU memory (no need to store optimizer states for frozen parameters)
- Training speedup: ~25% faster training throughput compared to full fine-tuning (fewer gradient computations)
- No inference overhead: After merging, identical inference cost to the original model
Limitations & Open Questions
- Rank selection: The optimal rank r is task-dependent and found by grid search. No principled method exists for predicting the right rank a priori
- MLP layers not explored: The paper only applies LoRA to attention weights; subsequent work suggests MLP adaptation can also help
- Batch inference with different tasks: Merging LoRA weights into W_0 prevents batching inputs for different tasks in a single forward pass (must choose one task's A, B per batch). The paper notes this but leaves dynamic batching as future work
- Limited theoretical justification: The paper provides empirical evidence for low intrinsic rank but limited formal analysis of why fine-tuning updates are low-rank or when this assumption might break
- Interaction with quantization: Not explored in the original paper; later work (QLoRA) showed LoRA and quantization are synergistic, enabling fine-tuning of 65B models on a single GPU
Connections
Related papers in the wiki: - Attention Is All You Need -- LoRA targets the attention weight matrices of the transformer architecture introduced here - Language Models Are Few Shot Learners -- GPT-3 is the primary large-scale testbed for LoRA; LoRA provides a practical way to adapt GPT-3-scale models - Bert Pre Training Of Deep Bidirectional Transformers For Language Understanding -- BERT-style models (RoBERTa, DeBERTa) are evaluated in the LoRA paper; LoRA applies to the pretrain-then-adapt paradigm BERT established - Scaling Laws For Neural Language Models -- Scaling laws predict that models will continue growing, making parameter-efficient adaptation methods like LoRA increasingly critical - Training Compute Optimal Large Language Models -- Chinchilla-optimal models are even larger per FLOP, further motivating LoRA-style adaptation - Foundation Models -- LoRA is a key enabler of the pretrain-then-adapt paradigm that defines foundation model deployment - Machine Learning -- LoRA addresses the fundamental ML challenge of adapting large pretrained models efficiently