Mistral 7B
Overview
Mistral 7B (Jiang et al., Mistral AI, 2023) challenged the prevailing assumption that larger language models are always better by demonstrating that a carefully designed 7-billion-parameter model can outperform models with nearly twice its parameter count. At a time when the LLM field was racing toward ever-larger models, Mistral 7B showed that architectural efficiency -- through Grouped-Query Attention (GQA) and Sliding Window Attention (SWA) -- could deliver superior performance per parameter, achieving 3.3x parameter efficiency on MMLU and 5.4x on reasoning benchmarks relative to Llama 2.
The paper's core insight is that attention mechanism design matters as much as raw scale. By combining GQA (which reduces key-value cache memory and accelerates inference) with SWA (which limits each token's attention to a fixed window, reducing complexity from O(n^2) to O(n * w)), Mistral 7B handles longer contexts efficiently while maintaining quality. The model outperformed Llama 2 13B on every benchmark tested -- including mathematics (GSM8K: 52.2% vs. 34.3%) and code generation (HumanEval: 30.5% vs. 18.9%) -- and approached Llama 1 34B on several tasks despite being nearly 5x smaller.
Released under the Apache 2.0 license, Mistral 7B became one of the most widely adopted open-weight language models, serving as the base for countless fine-tuned variants across research and industry. Its instruction-tuned version (Mistral 7B -- Instruct) surpassed Llama 2 13B -- Chat on human evaluation benchmarks. The paper also introduced a rolling cache mechanism for KV storage that enables efficient inference on long sequences without the memory overhead of full attention.
Key Contributions
- Grouped-Query Attention (GQA): Multiple query heads share key-value heads, accelerating inference and reducing memory while maintaining quality -- a middle ground between Multi-Head Attention (MHA) and Multi-Query Attention (MQA)
- Sliding Window Attention (SWA): Limits each token's attention to a fixed window of W=4096 recent tokens, reducing attention complexity from O(n^2) to O(n * w) and enabling efficient long-context processing
- Rolling buffer KV cache: A fixed-size cache that wraps around, allowing constant memory usage regardless of sequence length during inference
- Superior parameter efficiency: Outperforms Llama 2 13B across all benchmarks with roughly half the parameters, demonstrating that architectural innovations can substitute for scale
- Open-weight release under Apache 2.0: Democratized access to high-performance language models, catalyzing the open-source LLM ecosystem
Architecture / Method
┌─────────────────────────────────────────────────────────┐
│ Mistral 7B Transformer │
│ │
│ Input Tokens ──► Embedding + RoPE │
│ │ │
│ ┌──────────┴──────────┐ x32 layers │
│ │ Transformer Block │ │
│ │ │ │
│ │ ┌───────────────┐ │ │
│ │ │ RMSNorm │ │ │
│ │ └───────┬───────┘ │ │
│ │ ▼ │ │
│ │ ┌───────────────┐ │ Sliding Window │
│ │ │ GQA Attention │ │ Attention (W=4096) │
│ │ │ 32Q / 8KV │ │ │
│ │ └───────┬───────┘ │ ┌──────────────────┐ │
│ │ + residual │ │ Rolling KV Cache │ │
│ │ ▼ │ │ pos i → slot │ │
│ │ ┌───────────────┐ │ │ (i mod W) │ │
│ │ │ RMSNorm │ │ │ O(W) memory │ │
│ │ └───────┬───────┘ │ └──────────────────┘ │
│ │ ▼ │ │
│ │ ┌───────────────┐ │ Effective receptive │
│ │ │ SwiGLU FFN │ │ field: 32 x 4096 │
│ │ └───────┬───────┘ │ = ~131K tokens │
│ │ + residual │ │
│ └──────────┴──────────┘ │
│ │ │
│ ▼ │
│ Output Logits (32K vocab) │
└─────────────────────────────────────────────────────────┘

Mistral 7B is a decoder-only transformer with the following architecture:
| Parameter | Value |
|---|---|
| Parameters | 7B |
| Layers | 32 |
| Hidden dimension | 4096 |
| Attention heads | 32 |
| KV heads (GQA) | 8 |
| Sliding window size | 4096 tokens |
| Vocabulary size | 32,000 |
| Context length | 8,192 tokens (effective much longer via SWA) |
Grouped-Query Attention (GQA): Instead of each query head having its own key and value projections (as in standard MHA), GQA groups query heads to share key-value heads. With 32 query heads and 8 KV heads, each group of 4 query heads shares one KV head. The attention computation becomes:
- Q_i = W_Q^i * X
- K_g = W_K^g * X
- V_g = W_V^g * X (where g = floor(i * G / H))
This reduces the KV cache size by 4x compared to standard MHA, directly accelerating inference.
Sliding Window Attention (SWA): Each token attends only to the W=4096 most recent tokens in the sequence. Because information propagates through layers, a token at layer k can theoretically access information from up to k * W tokens back. With 32 layers and W=4096, the theoretical receptive field reaches ~131K tokens despite each layer only attending to 4096.
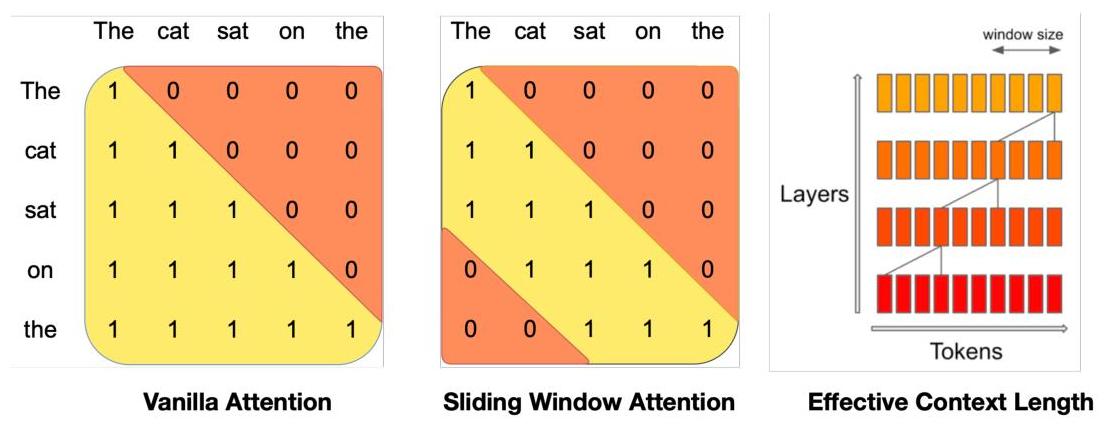
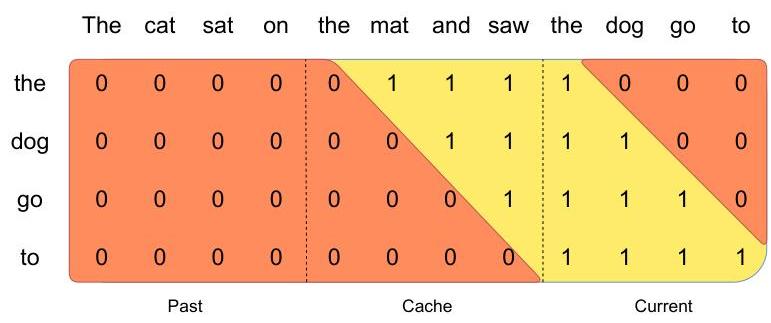
Rolling Buffer Cache: During inference, the KV cache uses a fixed buffer of size W. Position i writes to cache slot (i mod W), overwriting stale entries. This bounds memory usage at O(W) regardless of sequence length, a critical advantage for deployment.
Additional architecture choices include: RoPE positional embeddings, SiLU activation, pre-norm with RMSNorm, and no bias terms -- following the LLaMA recipe.
Results

Key experimental findings across standard LLM benchmarks:
| Model | Params | MMLU | HellaSwag | WinoGrande | ARC-c | GSM8K | HumanEval |
|---|---|---|---|---|---|---|---|
| Mistral 7B | 7B | 60.1 | 81.3 | 75.3 | 55.5 | 52.2 | 30.5 |
| Llama 2 7B | 7B | 44.4 | 77.1 | 69.5 | 43.2 | 16.0 | 11.6 |
| Llama 2 13B | 13B | 55.6 | 80.7 | 72.9 | 48.8 | 34.3 | 18.9 |
| Llama 1 34B | 34B | 56.8 | 83.7 | 76.2 | 54.4 | 44.1 | 25.0 |
Mistral 7B matches or exceeds Llama 2 13B on every benchmark despite being nearly half the size. On math (GSM8K) and code (HumanEval), the gap is particularly large -- 52.2% vs. 34.3% and 30.5% vs. 18.9% respectively. The model approaches Llama 1 34B (a nearly 5x larger model) on MMLU and reasoning benchmarks.
The instruction-tuned variant (Mistral 7B -- Instruct) outperforms Llama 2 13B -- Chat on MT-Bench (human preference evaluation), demonstrating that the architectural advantages carry through to the aligned setting.
Limitations & Open Questions
- Training data undisclosed: Unlike Llama, Mistral AI did not disclose the training dataset composition, making it difficult to assess data contamination or reproduce results
- No scaling study: The paper only presents the 7B model, leaving open the question of how GQA + SWA scale to larger model sizes (later answered by Mixtral 8x7B)
- SWA information loss: While the theoretical receptive field spans 131K tokens, the actual information propagation through layers is lossy -- it is unclear how much long-range dependency information survives in practice
- Benchmark saturation: At the 7B scale, many of these benchmarks may not capture the full picture of model capability versus larger models in complex reasoning tasks
- Safety evaluation limited: The paper includes basic guardrail analysis for the Instruct variant but does not provide comprehensive safety or bias evaluations
Connections
Related papers in the wiki: - Attention Is All You Need -- the original transformer architecture that Mistral 7B builds upon - Language Models Are Few Shot Learners -- GPT-3 established the scaling paradigm that Mistral 7B challenges by showing efficiency can substitute for scale - Training Compute Optimal Large Language Models -- Chinchilla's compute-optimal scaling laws informed the training philosophy: train smaller models on more data - Scaling Laws For Neural Language Models -- Kaplan et al. scaling laws that Mistral 7B implicitly argues need revision when architectural efficiency is considered - Bert Pre Training Of Deep Bidirectional Transformers For Language Understanding -- another approach to efficient pretraining, bidirectional vs. Mistral's autoregressive - Foundation Models -- broader context on how efficient open models shape the foundation model landscape