Overview
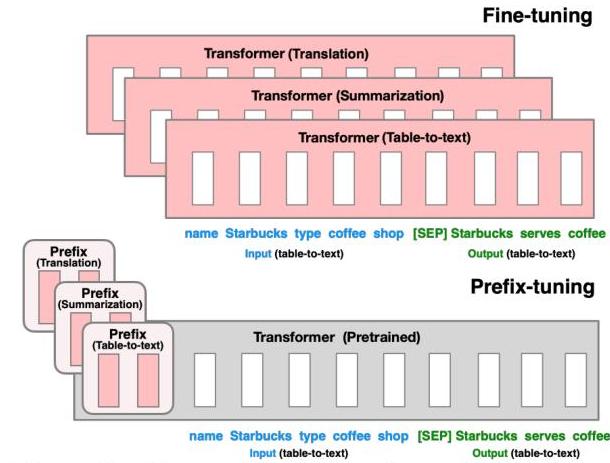
Large pretrained language models like GPT-2 and BART achieve strong performance on generation tasks, but full fine-tuning requires storing a separate copy of all model parameters for each task -- a prohibitive cost when models have hundreds of millions or billions of parameters. Prefix-tuning, proposed by Xiang Lisa Li and Percy Liang at Stanford, addresses this by keeping the entire pretrained model frozen and learning only a small continuous vector (the "prefix") that is prepended to the key-value pairs at every transformer layer. This prefix acts as a set of virtual tokens that steer the model's generation behavior without modifying any of the original weights.
The core insight is that task-specific adaptation can be achieved in the activation space rather than the weight space. Instead of discrete text prompts (which are constrained to the model's vocabulary and are difficult to optimize), prefix-tuning optimizes a continuous prefix matrix directly via gradient descent. This gives the optimizer far more expressive power per parameter than discrete prompt engineering while requiring only 0.1% of the parameters that full fine-tuning demands -- a 1000x reduction.
Prefix-tuning matches or exceeds full fine-tuning performance on table-to-text generation (E2E, WebNLG, DART) and abstractive summarization (XSUM), particularly excelling in low-data regimes where full fine-tuning overfits. The method also generalizes better to unseen table categories and topics, suggesting that the frozen LM backbone preserves its pretrained knowledge more effectively than a fully fine-tuned model. This work was a foundational contribution to the parameter-efficient fine-tuning (PEFT) paradigm that now includes LoRA, adapters, and prompt tuning, and has become central to how large language models are deployed in multi-task and personalized settings.
Key Contributions
- Continuous prefix optimization: Introduced the idea of prepending trainable continuous vectors to the keys and values at every transformer layer, enabling task-specific adaptation with only 0.1% of model parameters
- Reparameterization for training stability: Proposed decomposing the prefix matrix through a smaller matrix and an MLP during training, then discarding the MLP at inference -- this addresses the optimization difficulty of directly tuning high-dimensional prefix embeddings
- Universality across architectures: Demonstrated the approach on both autoregressive (GPT-2) and encoder-decoder (BART) models, showing it generalizes across generation paradigms
- Superior low-data and extrapolation performance: Showed that prefix-tuning outperforms full fine-tuning when data is scarce and generalizes better to unseen categories, because the frozen backbone retains more of its pretrained knowledge
- Practical multi-task deployment: Enabled serving many task-specific models by storing only small prefix vectors per task while sharing a single frozen backbone -- a critical efficiency for production systems
Architecture / Method
Standard Fine-Tuning Prefix-Tuning
───────────────────── ─────────────
┌─────────────────┐ ┌─────────────────┐
│ Transformer │ │ Transformer │
│ (ALL params │ │ (FROZEN) │
│ updated) │ │ │
│ │ │ Layer L: │
│ Layer L: │ │ K=[P_key;K_orig] │
│ K,V from input │ │ V=[P_val;V_orig] │
│ │ │ ▲ │
│ Layer 2: │ │ Layer 2: │
│ K,V from input │ │ K=[P_key;K_orig] │
│ │ │ V=[P_val;V_orig] │
│ Layer 1: │ │ ▲ │
│ K,V from input │ │ Layer 1: │
└─────────────────┘ │ K=[P_key;K_orig] │
│ V=[P_val;V_orig] │
Trainable: 100% └────────┬────────┘
│
┌────────┴────────┐
│ Prefix P'(l,d') │
│ │ │
│ MLP_theta │
│ │ │
│ P_theta(l,d) │
│ (reparameterized│
│ then discarded │
│ at inference) │
└─────────────────┘
Trainable: ~0.1%
How prefixes work
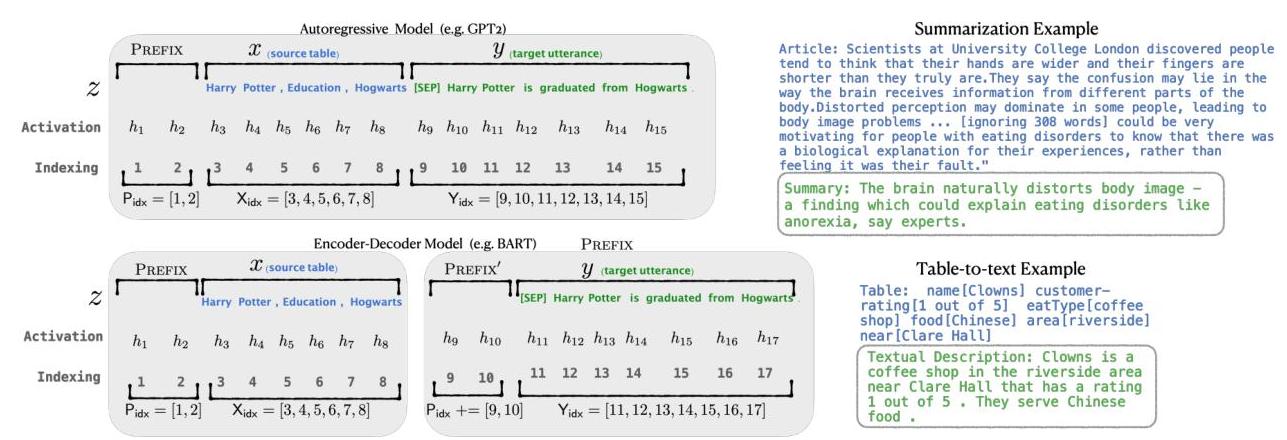
In a standard transformer, each layer computes attention over the key-value pairs derived from the input sequence. Prefix-tuning prepends a set of l trainable prefix vectors to the keys and values at every layer of the transformer. Concretely, for a model with L layers, the trainable parameters are:
- For autoregressive models (GPT-2): prefix matrices
P_key[i]andP_value[i]of shape(l, d)for each layeri, prepended to the key and value matrices so that all subsequent tokens can attend to these virtual prefix tokens - For encoder-decoder models (BART): separate prefixes for the encoder and the decoder, allowing independent steering of encoding and generation
The prefix length l is the primary capacity knob. Optimal values are approximately 200 for GPT-2 on summarization tasks and 10-20 for BART on table-to-text (structured-to-text) tasks; shorter prefixes suffice for encoder-decoder architectures because cross-attention already provides strong conditioning.
Reparameterization trick
Directly optimizing the prefix parameters P_theta in the high-dimensional space is unstable. Instead, the prefix is decomposed as:
P_theta[i, :] = MLP_theta(P'_theta[i, :])
where P'_theta is a smaller matrix of dimension (l, d') with d' < d, and the MLP upprojects to the full dimension. This reparameterization improves training stability and convergence. After training, the MLP is discarded and only the resulting P_theta values are stored -- so inference cost is unchanged.
Comparison to related approaches
| Method | What is tuned | Params (%) | Modifies LM weights? |
|---|---|---|---|
| Full fine-tuning | All parameters | 100% | Yes |
| Adapter tuning | Small bottleneck layers inserted between transformer layers | ~2-4% | No (adds new layers) |
| Prefix-tuning | Continuous prefix vectors at every layer | ~0.1% | No |
| Discrete prompting | Text tokens prepended to input | 0% (manual) | No |
Initialization
Initialization matters significantly. Initializing prefix vectors using activations from real words related to the task (e.g., "summarize" or "table") outperforms random initialization, especially in low-data settings. This provides a warm start that aligns the prefix with the model's existing representation space.
Results
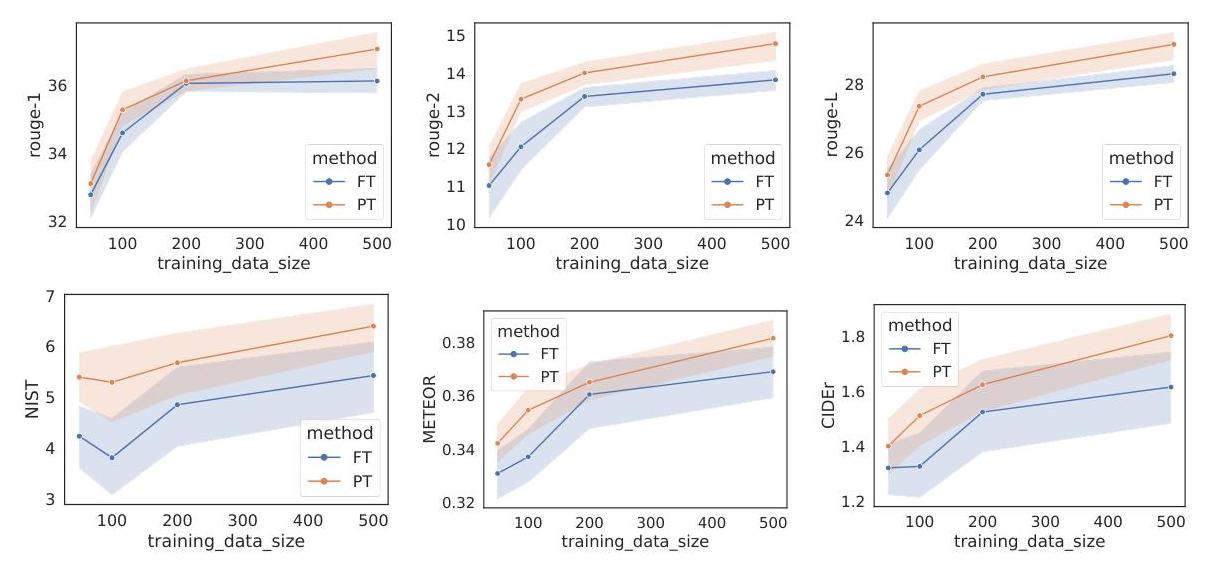
Table-to-text generation (E2E, WebNLG, DART)
| Method | E2E (BLEU) | E2E (NIST) | WebNLG (BLEU) | DART (BLEU) |
|---|---|---|---|---|
| Full fine-tuning (GPT-2 Medium) | 68.2 | 8.62 | 63.7 | 46.2 |
| Prefix-tuning (GPT-2 Medium) | 69.7 | 8.81 | 62.9 | 46.4 |
| Adapter tuning | 66.3 | 8.41 | 60.4 | -- |
Prefix-tuning matches or slightly exceeds full fine-tuning across all three benchmarks while training 1000x fewer parameters.
Abstractive summarization (XSUM with GPT-2 / BART)
On XSUM, prefix-tuning with BART-Large achieves comparable ROUGE scores to full fine-tuning. The optimal prefix length for BART is much shorter (10-20 tokens vs. ~200 for GPT-2 on summarization), likely because the encoder-decoder architecture already provides strong conditioning through cross-attention.
Low-data regime
When training data is reduced to small subsets, prefix-tuning consistently outperforms full fine-tuning. With only 100 or 200 training examples, the gap widens significantly -- full fine-tuning overfits while the frozen backbone in prefix-tuning acts as a strong regularizer.
Extrapolation to unseen categories
On WebNLG, which has seen and unseen topic categories, prefix-tuning shows substantially better generalization to unseen categories compared to full fine-tuning. This confirms that freezing the pretrained model preserves transferable knowledge.
Limitations & Open Questions
- Prefix length sensitivity: Performance is sensitive to prefix length, and the optimal value varies across tasks and architectures with no clear principled way to select it
- Expressiveness ceiling: With only 0.1% of parameters, there may be tasks where prefix-tuning cannot match full fine-tuning -- the paper focuses on generation tasks and does not extensively explore classification or other discriminative settings
- Interaction with model scale: The paper experiments with GPT-2 Medium and BART-Large; whether the 0.1% parameter budget remains sufficient (or becomes even more efficient) at GPT-3 scale is left open
- Relationship to discrete prompts: The connection between optimized continuous prefixes and interpretable discrete prompts is unclear -- the learned prefixes do not correspond to any natural language tokens
- Composability: Whether prefixes from different tasks can be combined (e.g., averaged or concatenated) for multi-task inference is unexplored
Connections
Related papers in the wiki: - Attention Is All You Need — The transformer architecture that prefix-tuning operates on; prefixes modify the attention mechanism by providing additional key-value pairs - Language Models Are Few Shot Learners — GPT-3 demonstrated in-context learning via discrete prompts; prefix-tuning can be seen as a continuous, optimizable generalization of prompting - Bert Pre Training Of Deep Bidirectional Transformers For Language Understanding — Established the pretrain-then-fine-tune paradigm that prefix-tuning makes parameter-efficient - Scaling Laws For Neural Language Models — Scaling laws motivate ever-larger models, making parameter-efficient methods like prefix-tuning essential for practical deployment - Foundation Models — Prefix-tuning is a key technique in the broader PEFT paradigm that enables foundation model adaptation - Machine Learning — Represents the shift from full fine-tuning to parameter-efficient adaptation in the transformer era