Overview
Reason2Drive provides the largest reasoning chain dataset for driving (>600K video-text pairs from nuScenes, Waymo, and ONCE) and introduces an aggregated evaluation metric (ADRScore) that addresses fundamental problems with using BLEU/CIDEr to assess driving reasoning quality. Driving VLM research lacked datasets with annotated reasoning chains and suffered from inappropriate evaluation metrics where standard language metrics are ambiguous for driving reasoning -- a correct but differently-worded chain scores low while a fluent but incorrect one can score high.
Reason2Drive addresses both gaps simultaneously. The dataset provides >600K pairs spanning perception, prediction, and reasoning stages collected from three open-source driving datasets, offering cross-dataset diversity in scenarios, geographies, and driving conditions. The aggregated evaluation metric (ADRScore) combines multiple scoring components to reduce individual metric biases and better assess chain-based reasoning quality in autonomous driving.
This is a benchmark-first contribution that stress-tests whether driving VLMs actually reason correctly rather than just producing fluent text. The baseline evaluations show that current VLMs have significant room for improvement on chain reasoning for driving, establishing both the difficulty and the value of the benchmark. Reason2Drive fills a critical role in the driving VLA ecosystem by providing a standardized way to evaluate the reasoning capabilities that are supposed to justify using large language models for driving.
Key Contributions
- Large-scale reasoning chain dataset: >600K video-text pairs automatically collected from nuScenes, Waymo Open Dataset, and ONCE, organized as perception -> prediction -> reasoning chains
- Cross-dataset diversity: Spans three major driving datasets, providing varied scenarios, geographies, and driving conditions that no single-dataset benchmark can match
- ADRScore evaluation metric: A novel aggregated metric combining Reasoning Alignment (RA), Redundancy (RD), and Missing Step (MS) components to address the semantic ambiguities of BLEU and CIDEr for assessing chain-based reasoning quality; ADRScore-S extends this to penalize spatial/visual element errors via MSE on geometric coordinates
- Reasoning chain structure: Characterizes driving as a sequential chain (perception -> prediction -> reasoning) with explicit stage annotations
- Baseline VLM evaluation: Evaluates multiple VLMs on chain reasoning, establishing difficulty and room for improvement
Architecture / Method
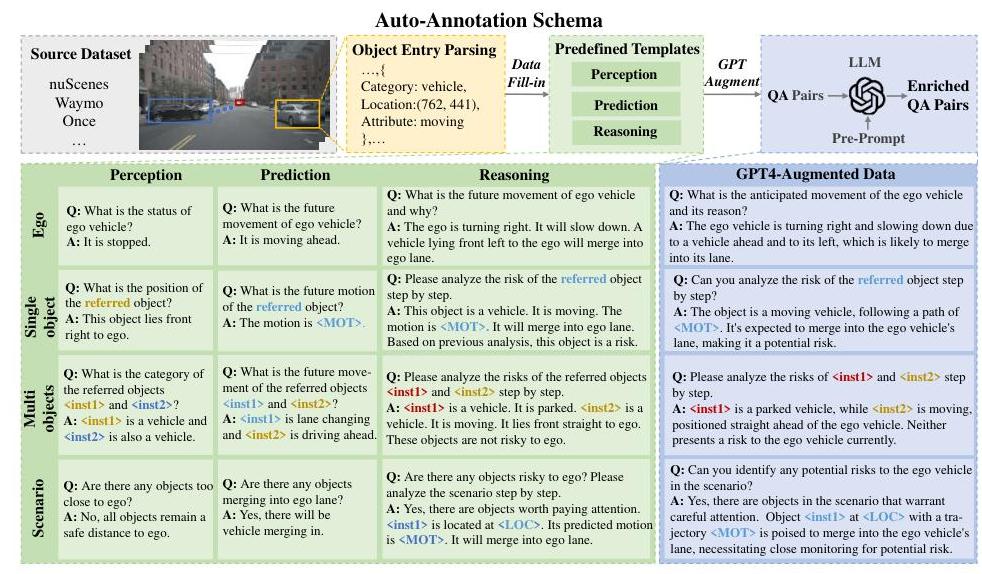
Reason2Drive is a dataset and benchmark contribution, not an architectural one. The methodology covers data construction and evaluation design:
Data construction pipeline: Starting from three source datasets (nuScenes, Waymo Open, ONCE), the pipeline extracts structured information from 3D annotations (object positions, velocities, trajectories) and map data (lanes, traffic signals). This structured information is converted into natural language chains through template-based generation, with each chain following the three-stage structure: 1. Perception: identifying objects, their attributes (moving status, distance), and positions 2. Prediction: inferring future states and intentions of objects (future motion, merging status) 3. Reasoning: step-by-step analysis of perceptual and predicted states to deduce inferences and driving decisions (Chain-of-Thought style)
GPT-4 and manual augmentation diversify and enrich the template-generated QA pairs to produce longer, more intricate reasoning chains. The tasks are also split into object-level (specific individual objects) and scenario-level (global driving environment) sub-types.
ADRScore evaluation metric: For each reasoning chain, the metric computes three components: (1) Reasoning Alignment (RA) — average semantic similarity between each hypothesis step and the most similar reference step; (2) Redundancy (RD) — minimum alignment, penalizing steps not required for the correct solution; (3) Missing Step (MS) — minimum alignment between reference steps and the hypothesis, identifying missing steps. ADRScore = (RA + RD + MS) / 3. The extended ADRScore-S additionally penalizes spatial reasoning errors by incorporating MSE on geometric coordinates (locations, motions) when comparing steps that contain visual elements. The aggregation reduces the failure modes of individual metrics (BLEU penalizing paraphrases, CIDEr rewarding frequent phrases).
Baseline evaluation protocol: VLMs receive the driving video frames and a prompt asking for a structured reasoning chain. Generated chains are evaluated at each stage independently and as a whole, revealing where models succeed (perception description) and fail (causal reasoning, decision justification).
Results
- Standard metrics are inadequate for driving reasoning: BLEU and CIDEr fail to capture causal relationships between reasoning steps and conclusions, and do not assess the accuracy of perceived visual elements
- The proposed method (Vicuna-7B) achieves ADRScore of 0.463 and ADRScore-S of 0.432, significantly outperforming InstructBLIP (ADRScore 0.351, ADRScore-S 0.214) and other baseline VLMs (Blip-2, MiniGPT-4)
- ADRScore-S reveals larger performance gaps between models than traditional metrics alone, validating its utility for spatial reasoning evaluation
- Ablation studies show reasoning tasks are the most crucial training signal; adding perception and prediction tasks yields further improvements (~4.1% and ~6.8% ADRScore-S gains respectively)
- The instructed vision decoder achieves bounding box accuracy of 0.806 and trajectory ADE of 1.875, surpassing MiniGPT-4 and Kosmos-2 baselines
- Pre-training on Reason2Drive before fine-tuning for control signal prediction (speed and steering) improves downstream planning performance compared to direct fine-tuning
- The model generalizes across datasets: training exclusively on nuScenes and testing on unseen Waymo and ONCE shows limited performance drop, demonstrating the value of the dataset's world knowledge and diversity
Limitations & Open Questions
- This is a reasoning benchmark, not an action policy -- it evaluates reasoning about actions, not action generation itself; the gap between correct reasoning and safe driving persists
- Automatic QA generation may encode biases from source datasets and collection scripts, potentially rewarding memorization of template patterns
- Reasoning evaluation remains fundamentally difficult even with improved metrics -- the gap between language-level correctness and driving-level safety is not fully bridged
Connections
- Autonomous Driving -- driving reasoning evaluation
- Vision Language Action -- evaluates VLA reasoning capabilities
- Drivelm Driving With Graph Visual Question Answering -- related driving VQA benchmark
- Textual Explanations For Self Driving Vehicles -- earlier work on driving explanations
- Orion Holistic End To End Autonomous Driving By Vision Language Instructed Action Generation -- VLA evaluated on reasoning
- Nuscenes A Multimodal Dataset For Autonomous Driving -- source dataset for Reason2Drive