Overview
Talk2Drive introduces an LLM-based framework for personalized autonomous driving through natural language interaction, demonstrated in real-world field experiments on a 2019 Lexus RX450h test vehicle. The core problem is that existing autonomous driving systems lack mechanisms for passengers to express preferences in natural language and have those preferences persistently shape driving behavior. Prior language-conditioned driving work (GPT-Driver, DriveGPT4, LMDrive) focused on using LLMs as planners or explainers but did not address personalization -- the system behaves identically regardless of who is in the car.
The key contribution is a cloud-based architecture where GPT-4 converts verbal passenger commands into executable control parameter adjustments via a five-step pipeline: speech recognition, command interpretation, context integration (weather, traffic, perception APIs), code generation for control adjustments, and execution with feedback. Critically, the system handles commands at varying levels of directness -- from explicit instructions ("drive at 30 mph") to implicit contextual hints ("I'm feeling a bit carsick") -- by leveraging the LLM's commonsense reasoning to infer appropriate driving style modifications.
A memory module stores historical commands, generated programs, and passenger feedback to build individualized driving profiles. This enables the system to learn that a particular passenger prefers gentler acceleration or wider following distances without requiring re-instruction. In field experiments across highway, intersection, and parking scenarios, Talk2Drive reduced human takeover rates by up to 78.8% (highway), 100% (parking), and 66.7% (intersection) versus rule-based baselines. The memory module provides an additional benefit, further reducing takeover rates by up to 65.2% compared to Talk2Drive without the memory module.
Key Contributions
- First real-world LLM-driven personalized driving system: Deployed on a physical test vehicle with full sensor suite (LiDAR, front camera, radar, GNSS), not just simulation or open-loop evaluation
- Multi-level command interpretation: Handles explicit commands, implicit preferences, and contextual hints through GPT-4's commonsense reasoning, covering a broader range of human communication than prior structured-command approaches
- Memory module for persistent personalization: Stores and retrieves historical interaction patterns to build individualized driving profiles, reducing repeated instruction and improving passenger satisfaction over time
- Cloud-based LLM-to-control pipeline: Five-step architecture converting speech to executable control parameter adjustments via code generation, with contextual integration from weather, traffic, and perception APIs
- Significant takeover rate reduction: Up to 65.2% reduction in human takeovers with memory-augmented personalization in real-world driving scenarios
Architecture / Method
Talk2Drive: LLM-based Personalized Driving Pipeline
Passenger ──► "I'm feeling carsick"
│
▼
┌───────────────┐
│ Speech-to-Text │
└───────┬───────┘
▼
┌───────────────────────────────────────┐
│ GPT-4 (Cloud) │
│ ┌─────────────────────────────────┐ │
│ │ 1. Command Interpretation │ │
│ │ (explicit/implicit/contextual) │ │
│ ├─────────────────────────────────┤ │
│ │ 2. Context Integration │◄──┼── Weather / Traffic APIs
│ │ (weather, traffic, perception) │◄──┼── Perception (LiDAR, Cam)
│ ├─────────────────────────────────┤ │
│ │ 3. Code Generation │ │
│ │ (control param adjustments) │ │
│ └─────────────────────────────────┘ │
│ ▲ │ │
│ │ │ │
│ ┌──────┴──────┐ │ │
│ │Memory Module │ │ │
│ │(past cmds, │ │ │
│ │ feedback) │ │ │
│ └─────────────┘ │ │
└────────────────────┼───────────────────┘
▼
┌─────────────────────┐
│ Vehicle Control Stack│
│ (speed, accel, dist) │
└──────────┬──────────┘
▼
┌─────────────────────┐
│ Feedback (takeover?) │──► Memory Module
└─────────────────────┘
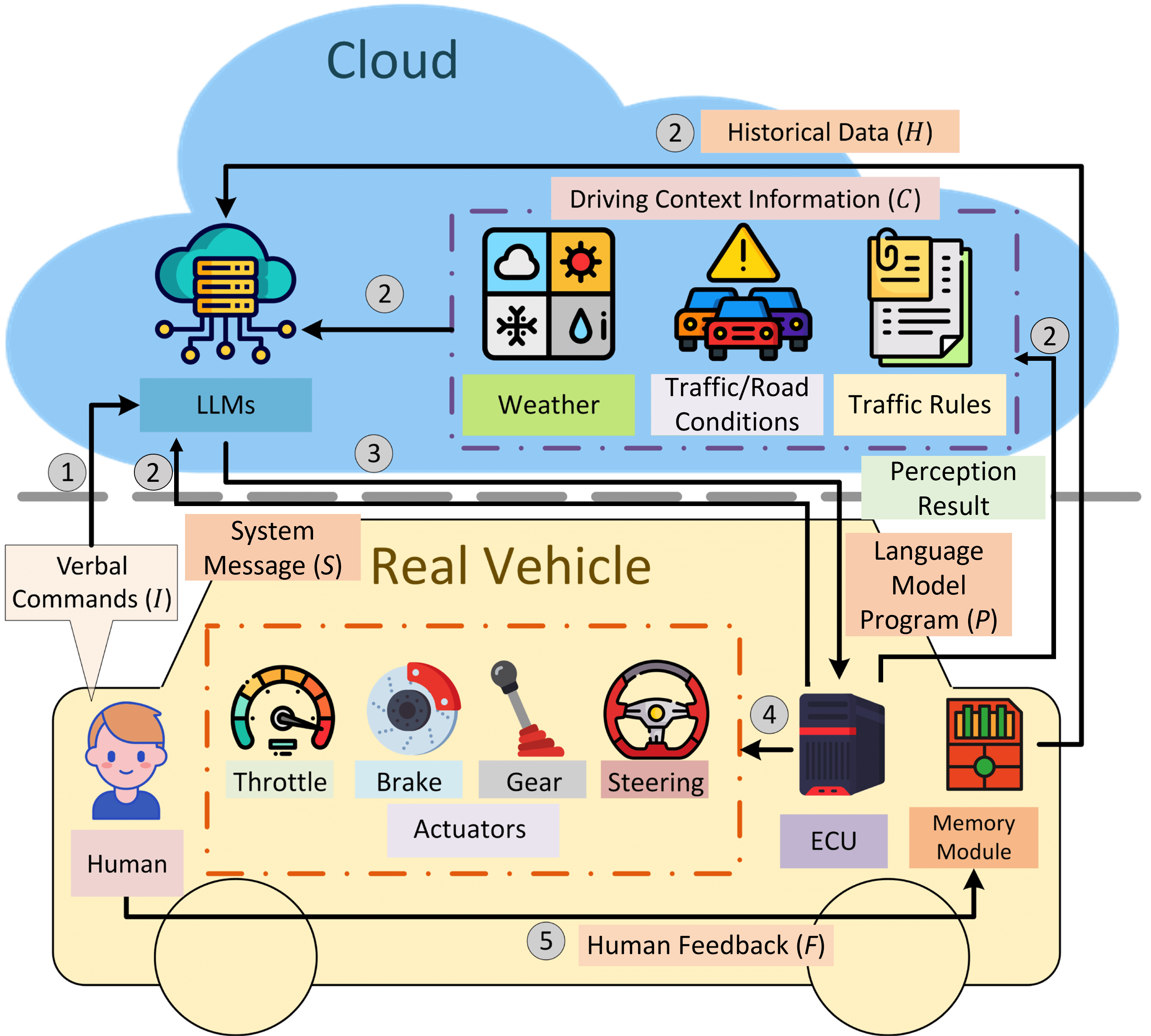
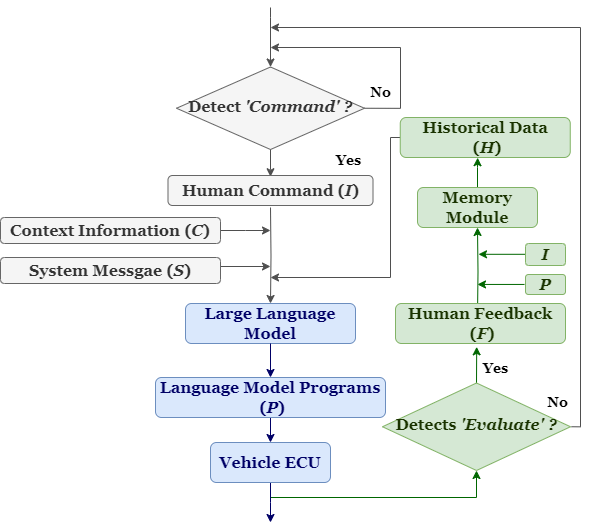
Talk2Drive uses a cloud-based pipeline where the LLM (GPT-4) operates as an intermediary between passenger speech and the vehicle's control stack. The architecture consists of five sequential stages:
- Speech-to-text: Passenger verbal commands are transcribed via speech recognition
- Command interpretation: GPT-4 classifies the command type (explicit instruction, implicit preference, or contextual hint) and extracts the intended driving behavior modification
- Context integration: The system queries external APIs for weather conditions, traffic state, and onboard perception outputs (object detection, lane detection from the sensor suite) to ground the LLM's reasoning in the current driving scenario
- Code generation: GPT-4 generates executable ROS topic commands that adjust specific control parameters (look-ahead distance, pure pursuit ratio, and target velocity) based on the interpreted command and context
- Execution and feedback: The generated code is executed on the vehicle's control stack, and the passenger's feedback (acceptance or takeover) is recorded
The memory module is the key differentiator from a stateless LLM interface. It maintains a structured history of: (1) raw commands issued by each passenger, (2) the generated control programs, and (3) feedback signals (takeover events, explicit approval/disapproval). When a new command is received, the memory module retrieves relevant past interactions for the current passenger, providing them as context to GPT-4. This allows the system to learn individual preferences without retraining -- the LLM adapts its code generation based on what has worked (and failed) for this specific passenger in similar scenarios.
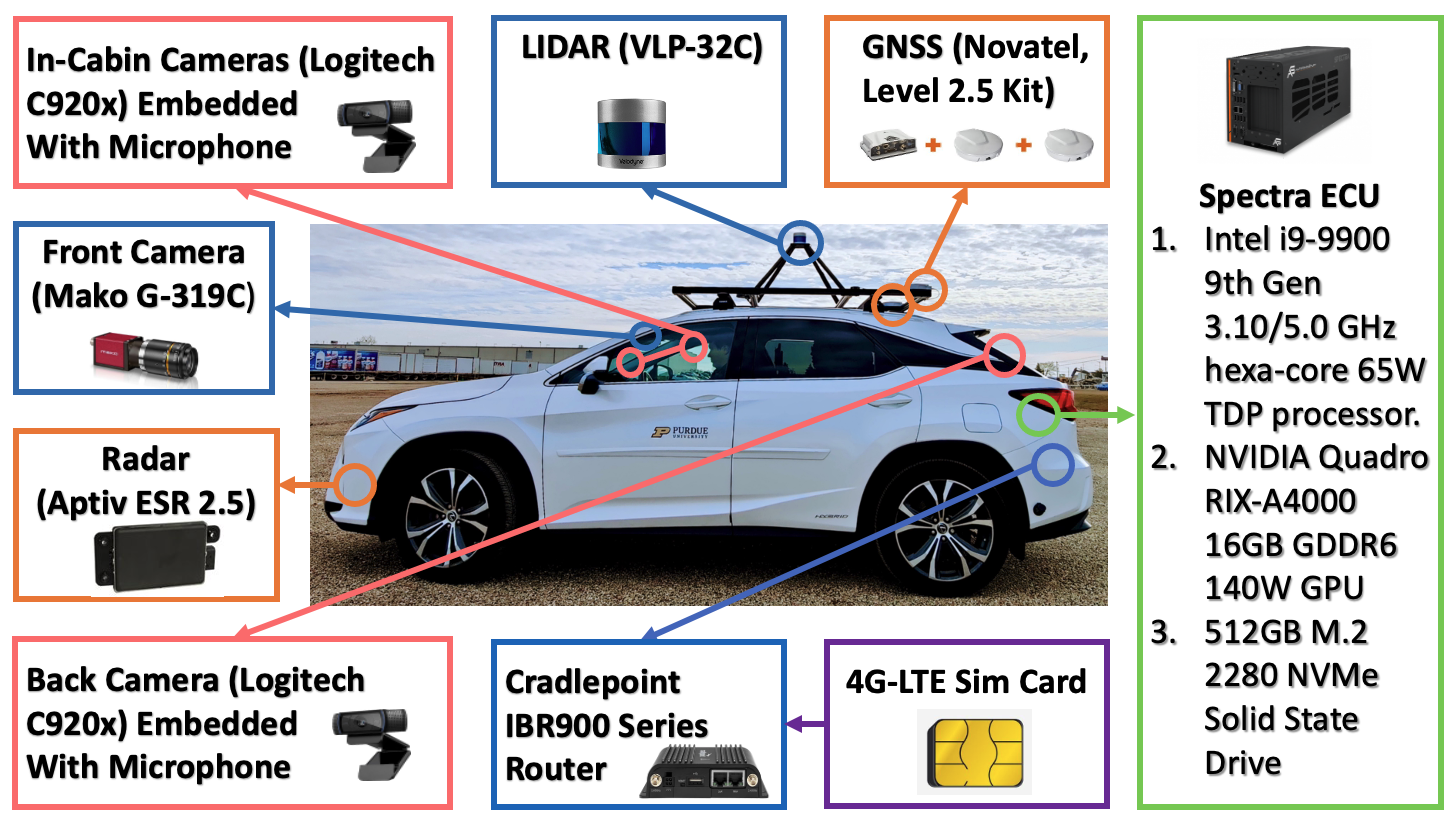
The test vehicle is a 2019 Lexus RX450h equipped with a Velodyne VLP-32C LiDAR, a Mako G-319C front camera, an Aptiv ESR 2.5 radar, Novatel GNSS, and an Intel i9-9900 ECU for onboard computation. The LLM inference runs in the cloud, introducing latency that constrains the system to parameter adjustment rather than real-time trajectory planning.
Results
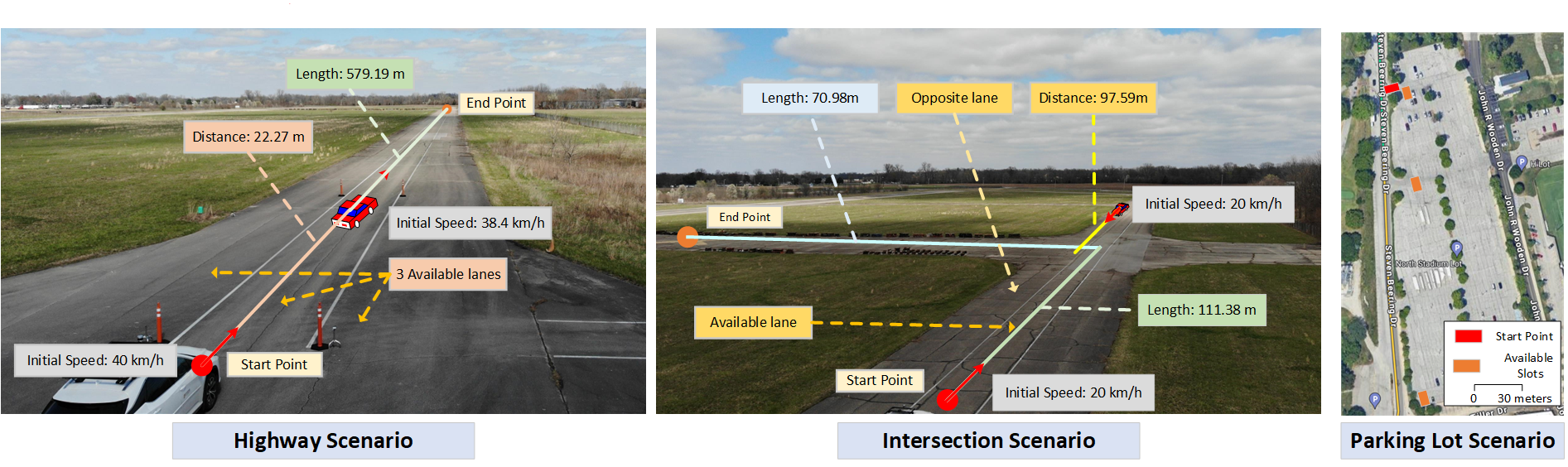
The system was evaluated across three driving scenarios with varying complexity:
| Scenario | Takeover Rate (Rule-based) | Takeover Rate (Talk2Drive w/o memory) | Takeover Rate (Talk2Drive w/ memory) | Reduction |
|---|---|---|---|---|
| Highway | ~33% | ~15% | ~7% | 78.8% vs rule-based |
| Intersection | ~9% | ~6% | ~3% | 66.7% vs rule-based |
| Parking | ~5% | ~2% | 0% | 100% vs rule-based |
Key findings:
- The memory module consistently reduces takeover rates across all scenarios, with the largest absolute improvement on highway driving where personalization of speed and following distance preferences matters most
- The system successfully interprets implicit commands (e.g., "I'm running late" leading to increased speed within safety bounds) through GPT-4's commonsense reasoning
- Cloud-based LLM latency (~1-3 seconds for GPT-4 inference) constrains the system to parameter adjustment rather than reactive control, making it suitable for preference tuning but not emergency maneuvers
- Parking scenarios show the strongest personalization effect, likely because parking preferences (distance to obstacles, approach angle) are highly individual and well-captured by the memory module
Limitations & Open Questions
- Cloud latency: The reliance on cloud-based GPT-4 introduces 1-3 second latency, limiting the system to style/preference adjustments rather than real-time reactive planning. On-device LLMs could address this but at reduced capability
- Safety guarantees: The system adjusts control parameters within predefined safety bounds, but there is no formal verification that LLM-generated code cannot produce unsafe behavior outside the guardrails
- Scalability of memory: The memory module stores raw interaction histories, which may become unwieldy over time. More sophisticated summarization or embedding-based retrieval could improve long-term personalization
- Limited scenario diversity: Testing covers highway, intersection, and parking but does not include adversarial weather, dense urban traffic, or high-speed merging scenarios
- Single LLM dependency: The entire pipeline depends on GPT-4's availability and behavior consistency. API changes or model updates could alter driving behavior without explicit system changes
- Open question: Should the "interaction LLM" (passenger interface) and "planning LLM" (trajectory generation) be unified or separated in production AV stacks? Talk2Drive implicitly argues for separation by adjusting parameters rather than generating trajectories
Connections
Related papers in the wiki: - Talk2Car Taking Control Of Your Self Driving Car -- direct predecessor establishing natural language command grounding for driving; Talk2Drive extends from object grounding to personalized control - Drive As You Speak Enabling Human Like Interaction With Large Language Models In Autonomous Vehicles -- concurrent work on LLM as bidirectional human-vehicle interface; similar framing but Talk2Drive adds the memory/personalization dimension and real-world deployment - Gpt Driver Learning To Drive With Gpt -- pioneered LLM-as-planner paradigm; Talk2Drive uses LLM for preference adjustment rather than direct trajectory generation - Drivegpt4 Interpretable End To End Autonomous Driving Via Large Language Model -- multimodal instruction tuning for joint control + explanation; Talk2Drive focuses on personalization rather than interpretation - Lmdrive Closed Loop End To End Driving With Large Language Models -- first closed-loop language-conditioned driving; LMDrive targets instruction following while Talk2Drive targets preference personalization - Driving With Llms Fusing Object Level Vector Modality For Explainable Autonomous Driving -- Wayve's LLM-for-driving with explainability focus; shares the "LLM as reasoning layer" concept but without personalization - Autonomous Driving -- broader context for language-conditioned driving systems - Planning -- Talk2Drive modifies planning parameters rather than generating plans directly