BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
Overview
Vision-language pre-training (VLP) methods before BLIP suffered from two fundamental limitations: (1) model architectures were typically optimized for either understanding tasks (e.g., image-text retrieval, VQA) or generation tasks (e.g., image captioning), but not both simultaneously; and (2) pre-training relied on noisy web-scraped image-text pairs, where alt-text and captions frequently fail to describe the visual content accurately. BLIP addresses both problems in a single unified framework.
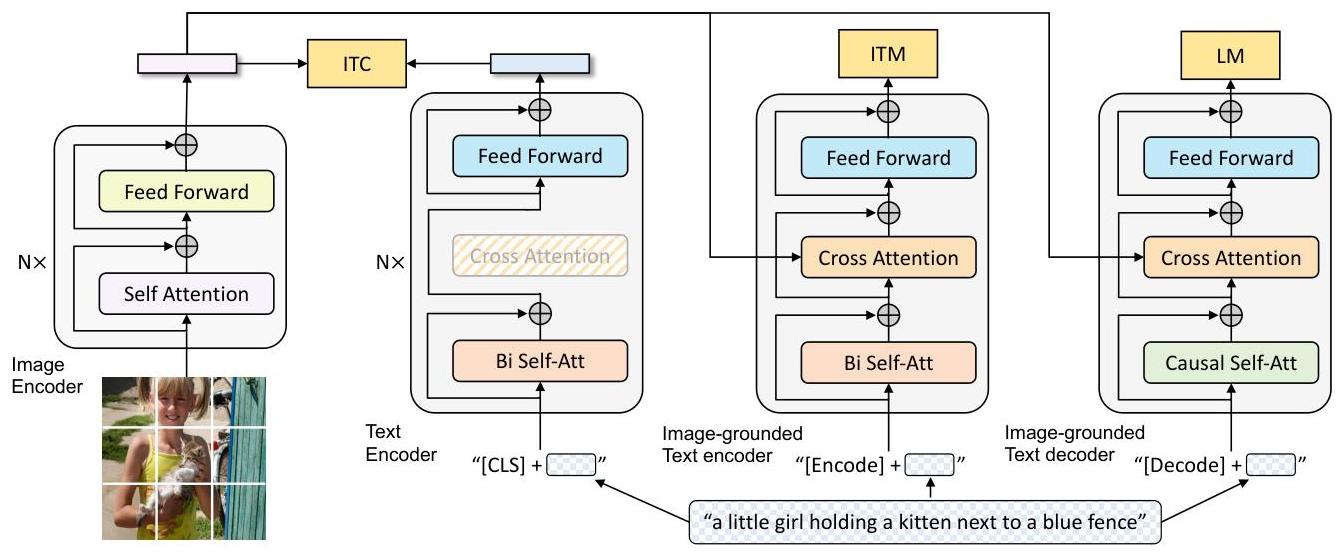
The core architectural contribution is the Multimodal mixture of Encoder-Decoder (MED), a flexible vision-language model that operates in three functional modes sharing a single text transformer backbone: (1) a unimodal encoder for contrastive learning (ITC), (2) an image-grounded text encoder for matching (ITM), and (3) an image-grounded text decoder for generation (LM). By sharing parameters across these modes while maintaining distinct self-attention patterns (bidirectional for understanding, causal for generation), MED achieves strong performance on both understanding and generation tasks from a single pre-trained checkpoint.
The second major contribution is Captioning and Filtering (CapFilt), a data bootstrapping method that improves the quality of the training corpus. A captioner (fine-tuned decoder) generates synthetic captions for web images using nucleus sampling, while a filter (fine-tuned encoder) removes noisy original and synthetic captions that do not match the image. The authors show that diverse synthetic captions generated via stochastic decoding provide richer learning signals than conservative deterministic captions, and that this bootstrapped dataset significantly improves downstream performance. BLIP achieves state-of-the-art results across image-text retrieval (+2.7% average recall@1 on COCO), image captioning (+2.8% CIDEr on COCO), VQA (+1.6% on VQAv2), and demonstrates strong zero-shot transfer to video-language tasks (+12.4% on MSRVTT text-to-video retrieval over fine-tuned baselines).
Key Contributions
- Multimodal mixture of Encoder-Decoder (MED): A unified architecture that jointly pre-trains a vision-language model for both understanding and generation tasks by sharing a text transformer across three functional modes with distinct attention masks
- Captioning and Filtering (CapFilt): A bootstrapping method that uses a fine-tuned captioner to generate synthetic captions and a fine-tuned filter to remove noisy pairs, improving the quality of web-scraped training data without requiring human annotation
- Unified pre-training objectives: Three complementary losses -- Image-Text Contrastive (ITC), Image-Text Matching (ITM) with hard negative mining, and Language Modeling (LM) -- that jointly optimize the shared model for alignment, matching, and generation
- Strong zero-shot video-language transfer: Demonstrates that image-language pre-training can transfer effectively to video tasks by simply averaging frame features, outperforming models fine-tuned on video data
- Nucleus sampling for data diversity: Shows that stochastic caption generation produces more diverse and informative training data than beam search, a finding with broad implications for synthetic data generation
Architecture / Method
┌────────────────────────────────────────────────────────────────┐
│ BLIP: Multimodal mixture of Encoder-Decoder (MED) │
├────────────────────────────────────────────────────────────────┤
│ │
│ Image ──► ┌──────────┐ │
│ │ ViT │──► Image embeddings │
│ │ Encoder │ │ │
│ └──────────┘ │ │
│ │ │
│ ┌───────────────────────┼──────────────────────┐ │
│ │ │ │ │
│ ┌────┴─────┐ ┌──────┴──────┐ ┌──────┴─────┐ │
│ │ Mode 1: │ │ Mode 2: │ │ Mode 3: │ │
│ │ Unimodal │ │ Img-Grounded│ │ Img-Ground.│ │
│ │ Text Enc.│ │ Text Encoder│ │ Text Decode│ │
│ │ │ │ │ │ │ │
│ │ Bi-dir │ │ Bi-dir │ │ Causal │ │
│ │ Self-Attn│ │ Self-Attn │ │ Self-Attn │ │
│ │ │ │ +Cross-Attn │ │ +Cross-Attn│ │
│ │ [CLS] │ │ [Encode] │ │ [Decode] │ │
│ └────┬─────┘ └──────┬──────┘ └──────┬─────┘ │
│ │ │ │ │
│ ▼ ▼ ▼ │
│ ITC Loss ITM Loss (binary) LM Loss (CE) │
│ (contrastive) (hard neg mining) (autoregress) │
│ │
├────────────────────────────────────────────────────────────────┤
│ CapFilt Bootstrapping │
│ │
│ Web Images ──► Captioner (fine-tuned decoder, nucleus p=0.9) │
│ │ │ │
│ Original captions Synthetic captions │
│ │ │ │
│ └──────┬───────┘ │
│ ▼ │
│ Filter (fine-tuned ITM encoder) ──► Remove noisy pairs │
│ │ │
│ ▼ │
│ Cleaned dataset + COCO ──► Re-pretrain from scratch │
└────────────────────────────────────────────────────────────────┘
Multimodal mixture of Encoder-Decoder (MED)
The visual encoder is a Vision Transformer (ViT) that processes the input image into a sequence of patch embeddings. An additional [CLS] token is prepended. The text transformer is shared across three functional modes:
-
Unimodal text encoder (for ITC): Encodes text independently using bidirectional self-attention. A
[CLS]token representation is projected to a shared embedding space with the image[CLS]token for contrastive alignment. Momentum encoders and soft labels (similar to ALBEF) are used to maintain a queue of negative features. -
Image-grounded text encoder (for ITM): Injects visual information into the text transformer via cross-attention layers inserted between the self-attention and feed-forward layers. A binary classifier on the
[Encode]token output predicts whether the image-text pair matches. Hard negative mining selects contrastive negatives with high ITC similarity but incorrect pairing. -
Image-grounded text decoder (for LM): Replaces bidirectional self-attention with causal self-attention to enable autoregressive text generation. Cross-attention layers attend to the visual encoder output. The
[Decode]token signals the beginning of generation. Trained with a standard language modeling (cross-entropy) loss to generate captions conditioned on the image.
The cross-attention layers and feed-forward networks are shared between the encoder and decoder modes. Only the self-attention layers differ (bidirectional vs. causal), enabling efficient parameter sharing while maintaining distinct functionalities.
Pre-training Objectives
| Objective | Mode | Loss | Purpose |
|---|---|---|---|
| Image-Text Contrastive (ITC) | Unimodal encoder | InfoNCE contrastive loss | Align image and text representations in shared embedding space |
| Image-Text Matching (ITM) | Image-grounded encoder | Binary cross-entropy | Learn fine-grained multimodal alignment via hard negative mining |
| Language Modeling (LM) | Image-grounded decoder | Cross-entropy (autoregressive) | Learn to generate text conditioned on visual input |
CapFilt: Captioning and Filtering
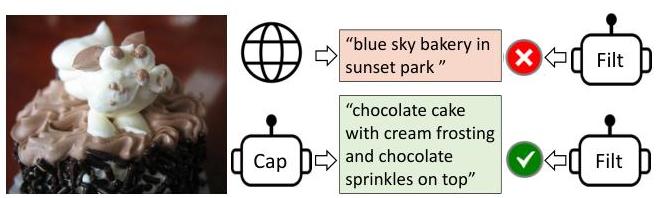
CapFilt bootstraps the training data in two steps:
-
Captioner: The image-grounded text decoder is fine-tuned on COCO captions, then used to generate synthetic captions for all web images using nucleus sampling (p=0.9). Nucleus sampling is critical -- it produces diverse captions that cover different aspects of the image, unlike beam search which generates conservative, repetitive captions.
-
Filter: The image-grounded text encoder is fine-tuned on COCO as an ITM model, then used to score both original web captions and synthetic captions. Pairs where the filter assigns low matching probability are removed.
The cleaned dataset (filtered web captions + filtered synthetic captions) is then combined with the human-annotated COCO data for a second round of pre-training from scratch. This bootstrapping loop can be repeated, though the paper finds diminishing returns after one iteration.
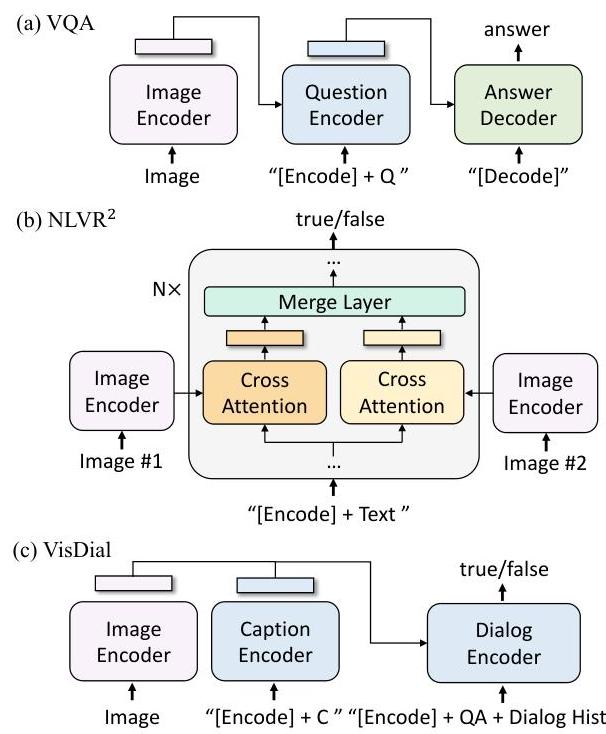
Downstream Task Adaptation
BLIP adapts to downstream tasks by selecting the appropriate functional mode:
- Image-text retrieval: Uses the ITC similarity for efficient candidate retrieval, followed by ITM re-ranking of top-k candidates
- Image captioning: Uses the image-grounded decoder directly, fine-tuned with LM loss
- VQA: Encodes the image and question with the encoder, then generates the answer autoregressively with the decoder (treating VQA as open-ended generation rather than classification)
- NLVR2: Extends the encoder with a merge attention layer that reasons over two images jointly
- Video-language tasks: Averages frame-level ViT features across uniformly sampled video frames
Results
Image-Text Retrieval (COCO and Flickr30K)
| Method | COCO TR@1 | COCO IR@1 | Flickr TR@1 | Flickr IR@1 |
|---|---|---|---|---|
| ALBEF (14M) | 77.6 | 60.7 | 95.9 | 85.6 |
| BLIP (14M) | 80.6 | 63.1 | 96.6 | 87.2 |
| BLIP (129M) | 81.9 | 64.3 | 97.3 | 87.3 |
| BLIP ViT-L (129M) | 82.4 | 65.1 | 97.4 | 87.6 |
Image Captioning (COCO, NoCaps)
| Method | COCO CIDEr | NoCaps CIDEr |
|---|---|---|
| LEMON-large (200M) | 135.7 | 113.4 |
| BLIP (14M) | 129.7 | 105.1 |
| BLIP (129M) | 131.4 | 106.3 |
| BLIP ViT-L (129M) | 136.7 | 113.2 |
Visual Question Answering
| Method | VQAv2 test-dev | VQAv2 test-std |
|---|---|---|
| ALBEF (14M) | 75.84 | 76.04 |
| BLIP (14M) | 77.54 | 77.62 |
| BLIP (129M) | 78.24 | 78.17 |
Zero-Shot Video-Language Transfer (MSRVTT)
| Method | Text-to-Video R@1 | Video-to-Text R@1 |
|---|---|---|
| ClipBERT (fine-tuned) | 22.0 | — |
| BLIP (zero-shot) | 34.4 | — |
The zero-shot video transfer result is particularly striking -- BLIP outperforms models specifically fine-tuned on video data by a large margin, validating that strong image-level vision-language representations generalize to temporal domains.
CapFilt Ablation
| Generation method | COCO TR@1 | COCO CIDEr |
|---|---|---|
| None (original web text) | 78.4 | 127.8 |
| + Synthetic captions (beam) | 79.6 | 128.9 |
| + Synthetic captions (nucleus) | 80.6 | 129.7 |
This ablation confirms that: (1) synthetic captions improve performance and (2) nucleus sampling outperforms beam search for caption generation. Filtering (applied on top of nucleus captions) yields a further gain in COCO TR@1 to 80.6 alongside VQA improvement, as shown in Table 1 of the paper.
Limitations & Open Questions
- Single bootstrapping iteration: The paper finds diminishing returns from repeated CapFilt, but does not explore whether architectural changes (e.g., stronger filter or captioner) could extend the bootstrapping loop further
- Image-only pre-training: While zero-shot video transfer is strong, the model does not explicitly model temporal dynamics -- it simply averages frame features, limiting its ability to capture motion and temporal reasoning
- Web data dependency: The 129M dataset (LAION, Conceptual Captions, etc.) is noisy and potentially biased; CapFilt mitigates but does not eliminate these issues
- Computational cost: Pre-training on 129M pairs with ViT-L requires substantial compute; the paper does not analyze compute-optimal scaling
- Filter quality ceiling: The filter is itself limited by the quality of the underlying ITM model; better filters may require external data or human feedback
Connections
Related papers in the wiki: - Learning Transferable Visual Models From Natural Language Supervision — CLIP introduced contrastive image-text pre-training; BLIP extends this with generation capabilities and data bootstrapping. BLIP's ITC objective directly follows CLIP's contrastive approach. - Bert Pre Training Of Deep Bidirectional Transformers For Language Understanding — BERT's masked language modeling and bidirectional encoding influenced BLIP's text encoder design and the ITM pre-training objective - Attention Is All You Need — The transformer architecture underpins both the ViT image encoder and the shared text transformer in MED - Palm E An Embodied Multimodal Language Model — PaLM-E builds on vision-language pre-training foundations like BLIP/CLIP to create embodied multimodal models for robotics - Foundation Models — BLIP sits at the intersection of vision-language pre-training and the "multimodal bridge" between pure language models and embodied systems - Vision Language Action — BLIP's unified understanding+generation architecture influenced the design of later VLA systems that require both perception (understanding) and action generation