Overview
Pointer Networks repurpose the attention mechanism as an output distribution, replacing the fixed output vocabulary of sequence-to-sequence models with attention weights over input positions. This enables the network to "point" to input elements and handle problems where the output dictionary size varies with input length. Standard seq2seq models generate tokens from a fixed vocabulary, which fundamentally cannot handle problems where the output space depends on the input size (e.g., selecting a subset or permutation of input elements).
The insight is elegant: instead of using attention to create a context vector that feeds into a fixed softmax classifier, the attention distribution itself is the output. At each decoding step, the model produces a probability distribution over all input positions, and the position with highest probability is selected. This allows the model to handle inputs of any length without architectural changes, since the output "vocabulary" grows automatically with the input.
Pointer Networks enabled neural approaches to combinatorial optimization problems (convex hull, TSP, Delaunay triangulation) by treating them as sequence-to-sequence tasks where geometric problems are solved by pointing to input coordinates in the right order. The copy mechanism in pointer-generator networks (See et al., 2017) and the pointing/copying ability in modern LLMs trace directly back to this work. The Set2Set readout in MPNNs also borrows from the pointer mechanism.
Key Contributions
- Attention as output: Instead of using attention to create a context vector that feeds into a fixed softmax, the attention weights themselves are the output -- P(point to position i) = softmax(score(decoder_state_t, encoder_states)) over all n input positions
- Dynamic output vocabulary: The output space is {1, 2, ..., n} where n is the input sequence length, not a fixed vocabulary V, naturally handling variable-length inputs without architectural changes
- Encoder-decoder with pointer mechanism: An LSTM encoder processes the input sequence into hidden states; an LSTM decoder produces query vectors that attend over encoder states via additive scoring
- Supervised training on combinatorial problems: Treats geometric problems as seq2seq tasks -- input is a sequence of 2D coordinates, output is an ordered selection of indices, with cross-entropy loss over input positions
- Generalization across problem sizes: Models trained on n=50 points can generalize to n=200+ points because the pointer mechanism scales naturally with input length
Architecture / Method
Standard Seq2Seq Pointer Network
──────────────── ───────────────
Input: x1 x2 ... xn Input: x1 x2 ... xn
│ │
▼ ▼
┌──────────┐ ┌──────────┐
│ LSTM │ │ LSTM │
│ Encoder │ │ Encoder │
└──┬───────┘ └──┬───────┘
│ e1..en │ e1..en
▼ ▼
┌──────────┐ ┌──────────┐
│ LSTM │ │ LSTM │
│ Decoder │ │ Decoder │
└──┬───────┘ └──┬───────┘
│ d_t │ d_t
▼ ▼
┌──────────┐ ┌────────────────────┐
│ Attention│──► context c_t │ Attention scores │
│ │ │ │ u_i = v^T tanh( │
└──────────┘ ▼ │ W1*e_i + W2*d_t) │
┌────────────┐ └─────────┬──────────┘
│ Fixed vocab │ │
│ softmax(Wc) │ ▼
└────────────┘ ┌────────────────────┐
│ softmax(u) ──► P(i)│
Output: tokens │ "point" to input i │
from vocab V └────────────────────┘
Output: indices into
input {1..n}
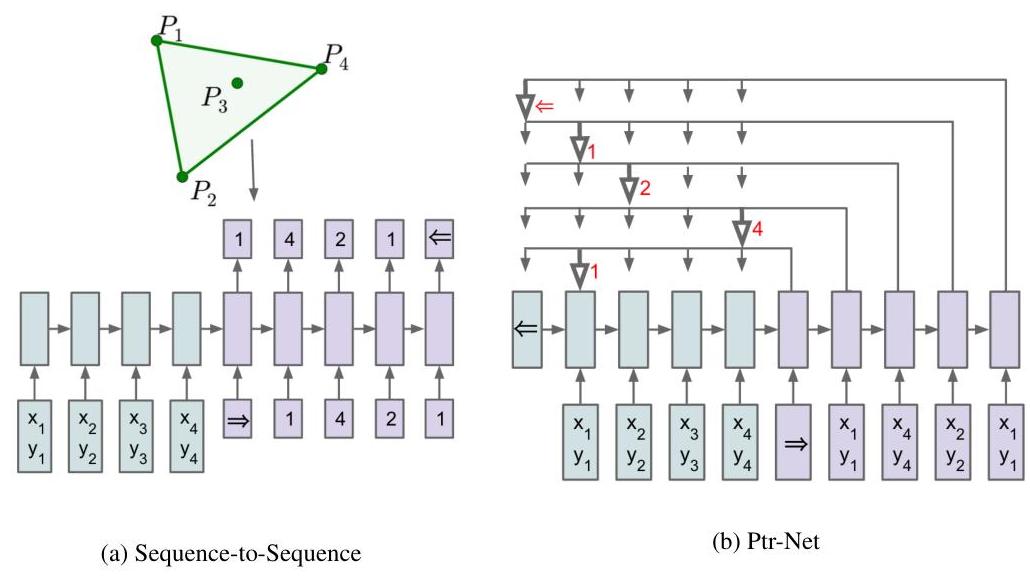
The architecture follows the encoder-decoder paradigm with a critical modification at the output layer.
Encoder: An LSTM (single-layer, 256 or 512 hidden units) processes the input sequence and produces hidden states {e_1, e_2, ..., e_n}, one per input element.
Decoder: An LSTM generates a sequence of outputs autoregressively. At each step t, the decoder state d_t is used to compute attention scores over all encoder states. The scoring function is additive attention: u_i^t = v^T * tanh(W_1 * e_i + W_2 * d_t), where v, W_1, W_2 are learned parameters. The output probability distribution: p(C_i | C_1, ..., C_{i-1}, P) = softmax(u_i), where C_i represents the index of the input element chosen as the i-th output.
Pointer output: The attention scores are normalized via softmax, producing a probability distribution over input positions. The position with highest probability is selected as the output for step t. The selected element's encoder state is then fed as input to the decoder for the next step.
Training: Standard supervised learning with cross-entropy loss: L = -sum_t log P(c_t^ | d_t), where c_t^ is the ground-truth index at step t. Trained with SGD at learning rate 1.0, batch size 128, and L2 gradient clipping. Training data: 1 million examples for each problem. For small TSP instances (up to 20 cities), exact optimal solutions computed using Held-Karp algorithm; for larger instances, approximate solutions from established algorithms. During inference, beam search finds high-probability output sequences, with validity constraints enforced for TSP to ensure each city is visited exactly once.
The critical difference from standard attention: in a normal seq2seq model, attention produces a context vector c_t = sum_i alpha_i * e_i which feeds into a fixed-vocabulary softmax. In Pointer Networks, the attention weights alpha_i ARE the output distribution. This seemingly small change has profound implications -- it decouples the output vocabulary from a fixed dictionary and ties it to the input instead.
Results
| Task | Model | Exact Accuracy | Coverage |
|---|---|---|---|
| Convex Hull (n=50) | Ptr-Net | 72.6% | 99.9% area |
| Convex Hull (n=50) | LSTM+Attn | 38.9% | 99.7% area |
| Convex Hull (n=500) | Ptr-Net | 1.3% | 99.2% area |
| TSP (n=50) | Ptr-Net | -- | Tour: 6.42 |
| TSP (n=50) | Algorithm A1 | -- | Tour: 6.46 |
| Delaunay (n=5) | Ptr-Net | 80.7% | 93.0% triangle |
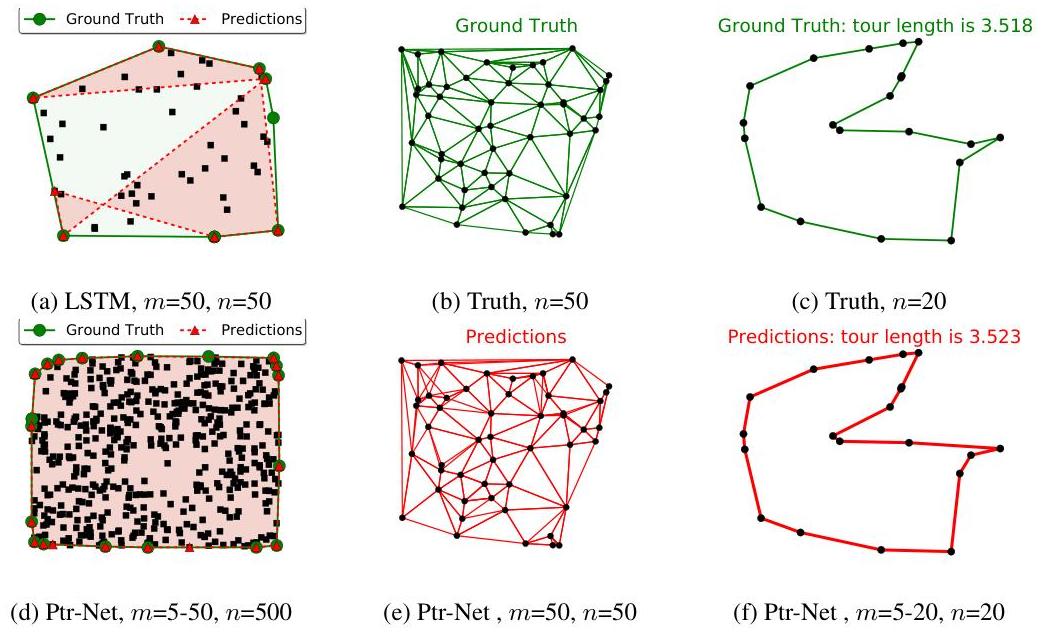
- Convex hull (n=50): 72.6% exact accuracy and 99.9% area coverage, substantially outperforming LSTM with attention (38.9% accuracy, 99.7% coverage) and vanilla LSTM (negligible performance)
- Cross-size generalization: A single model trained on variable input lengths (5-50 points) generalized to n=500 points (10x training size), maintaining 99.2% area coverage despite only 1.3% exact accuracy -- suggesting the model learned underlying geometric principles rather than memorizing mappings
- TSP (n=50): When trained on suboptimal solutions from algorithm A1, the Ptr-Net produced better tour lengths (6.42) than the training algorithm itself (6.46), approaching superior approximation algorithms (A2: 5.84, A3: 5.79) -- demonstrating ability to synthesize knowledge and discover improved strategies
- Scalability limitations: Generalization excelled for polynomial-time problems (convex hull) but performance degraded more significantly for NP-hard TSP when extrapolating to larger instances; models trained on optimal solutions for n=5-20 performed well up to n=25 but showed substantial degradation at n=40-50
- On Delaunay triangulation: successfully learns to output triangulation edges as ordered sequences of point indices
- Outperforms fixed-vocabulary baselines: standard seq2seq fails entirely when test inputs exceed training vocabulary size; Pointer Networks handle arbitrary sizes gracefully
Limitations & Open Questions
- Training requires supervised examples with known optimal solutions, limiting applicability to problems where ground truth orderings are available or can be computed (later addressed by reinforcement learning in Bello et al., 2016)
- The sequential decoding process means output is generated autoregressively, which may not be optimal for problems with inherent symmetry or no natural ordering
- Performance on large-scale combinatorial instances (n > 500) degrades significantly compared to specialized algorithms, though the approach is much more flexible and generalizable
Connections
- Machine Learning -- attention mechanism as output
- Attention Is All You Need -- attention generalized to self-attention in transformers
- Order Matters Sequence To Sequence For Sets -- extends pointer mechanism to set-structured problems
- Neural Message Passing For Quantum Chemistry -- uses Set2Set readout derived from pointer mechanism
- Neural Machine Translation By Jointly Learning To Align And Translate -- original attention mechanism that Pointer Networks repurpose