Overview
Neural Turing Machines (NTMs) augment neural networks with a differentiable external memory matrix and soft attention-based read/write heads, enabling them to learn simple algorithms that generalize beyond training sequence lengths. Standard RNNs encode all state in a fixed-size hidden vector, which makes precise storage and retrieval of multiple items fundamentally difficult. NTM showed that coupling a controller network with an addressable memory bank yields a system that can learn copy, sort, and associative-recall algorithms end-to-end via backpropagation.
The key innovation is the addressing mechanism: a hybrid of content-based addressing (cosine similarity lookup, like attention) and location-based addressing (interpolation, shift, sharpening, like a pointer). This combination allows the NTM to both look up items by content (like a hash table) and iterate through sequential locations (like a tape head), providing the two fundamental memory access patterns needed for algorithmic computation.
This work launched the memory-augmented neural network line of research, leading to Differentiable Neural Computers (Graves et al., 2016) and influencing the broader recognition that attention mechanisms could serve as a general-purpose information routing primitive. The NTM's read/write attention patterns foreshadowed the query-key-value attention that would become central to transformers.
Key Contributions
- Differentiable external memory: An N x M memory matrix read and written through soft attention weights, keeping the entire system differentiable and trainable with gradient descent
- Hybrid addressing: Content-based addressing (cosine similarity lookup) combined with location-based addressing (interpolation, shift, sharpening) allows both associative retrieval and sequential pointer manipulation
- Erase-then-add write mechanism: A gated write operation that first erases selected memory locations then adds new content, analogous to a programmable register file
- Generalization beyond training distribution: On the copy task, networks trained on sequences of length 1-20 generalize to length 120 (6x longer), suggesting the learned program is genuinely algorithmic
- Multiple read/write heads: Parallel heads enable simultaneous memory operations, increasing the expressiveness of learned programs
Architecture / Method
┌─────────────────────────────────────────────────────────────┐
│ External Memory (N × M) │
│ ┌──────┬──────┬──────┬──────┬──────┬──────┬──────┐ │
│ │ m_1 │ m_2 │ m_3 │ m_4 │ ... │m_N-1 │ m_N │ │
│ └──┬───┴──┬───┴──────┴──────┴──────┴──────┴──┬───┘ │
│ │ │ │ │
│ │ Read │ w_r (attention weights) Write │ w_w │
│ │ Head │◄───────────┐ ┌───────────►Head │ │
└───────┼──────┼────────────┼──┼────────────┼────┼────────────┘
│ │ │ │ │ │
│ r_t │ │ │ e_t,a_t │
▼ │ │ │ │ │
┌───────────────────────────────────────────────────────────┐
│ Controller (LSTM / FFN) │
│ │
│ Inputs: x_t + r_t Outputs: y_t + addressing │
│ parameters │
└──────────────┬────────────────────────────────────────────┘
│
┌──────────────▼────────────────────────────────────────────┐
│ Addressing Mechanism │
│ 1. Content: cosine_sim(k_t, m_i) ──► softmax(β_t·sim) │
│ 2. Interpolate: g_t·w_content + (1-g_t)·w_{t-1} │
│ 3. Shift: convolve with shift kernel s_t │
│ 4. Sharpen: w^γ_t / Σ w^γ_t │
└───────────────────────────────────────────────────────────┘
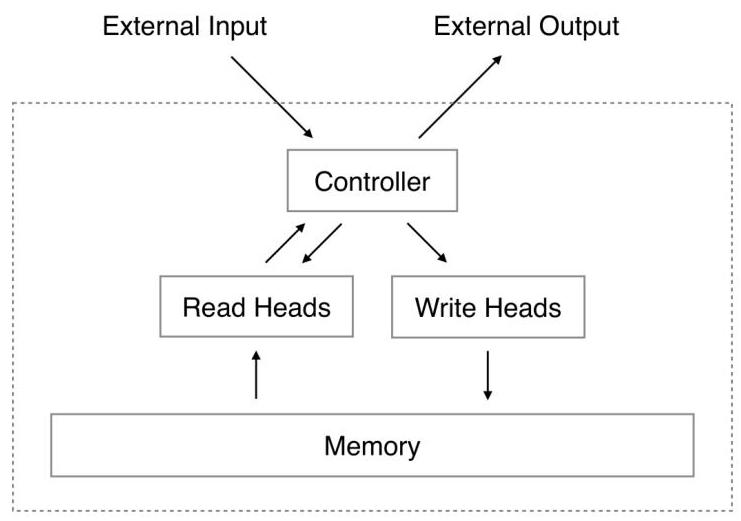
The NTM consists of a controller network and an external memory matrix M of size N x M (N memory locations, each an M-dimensional vector). The controller can be either a feedforward network or an LSTM.
Read operation: A read head produces an attention vector w_t over N locations (summing to 1). The read vector r_t = sum_i w_t(i) * M_t(i) is a weighted combination of memory rows, identical to soft attention. Unlike traditional computers that access memory locations discretely, NTMs employ "blurry" or attentional operations that interact with all memory locations simultaneously, weighted by attention distributions -- this design is crucial for maintaining differentiability.
Write operation: Decomposes into two differentiable steps inspired by LSTM gates. First, an erase operation selectively removes information: M_t'(i) = M_{t-1}(i) * (1 - w_t(i) * e_t). Then an add operation writes new content: M_t(i) = M_t'(i) + w_t(i) * a_t, where e_t is the erase vector and a_t is the add vector, both produced by the controller. This two-step process allows selective modification without destroying unrelated memory contents.
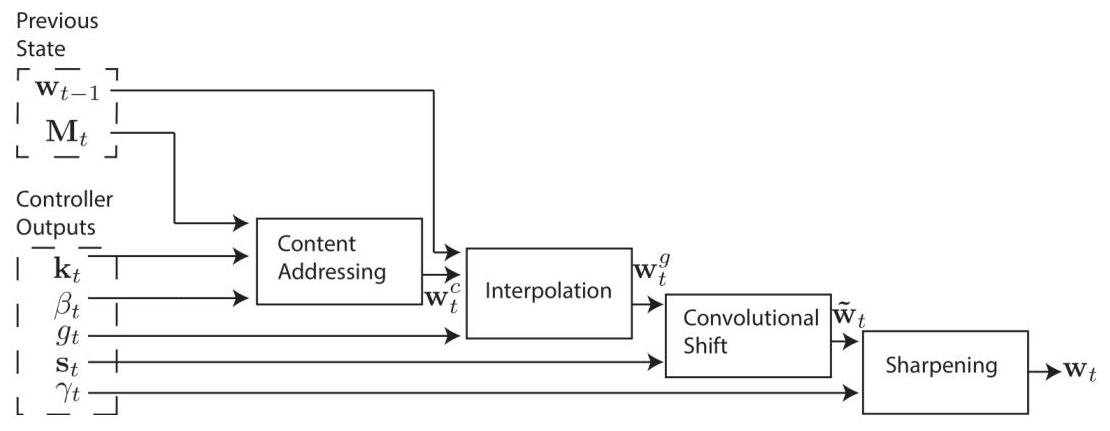
Addressing mechanism (the core innovation): The attention weight w_t is computed in four stages: 1. Content addressing: Compute cosine similarity between a key vector k_t (emitted by controller) and each memory row, sharpen with inverse temperature beta_t, apply softmax to get content weights w_c 2. Interpolation: Blend content weights with previous weights: w_g = g_t * w_c + (1 - g_t) * w_{t-1}, where g_t is a learnable gate 3. Convolutional shift: Apply a learned shift kernel s_t to enable the head to move to adjacent locations: w_s(i) = sum_j w_g(j) * s_t(i - j) 4. Sharpening: Raise to power gamma_t and renormalize to prevent attention from blurring over time
The controller emits all addressing parameters (k, beta, g, s, gamma, e, a) at each timestep, and the entire system is trained end-to-end with BPTT.
Results
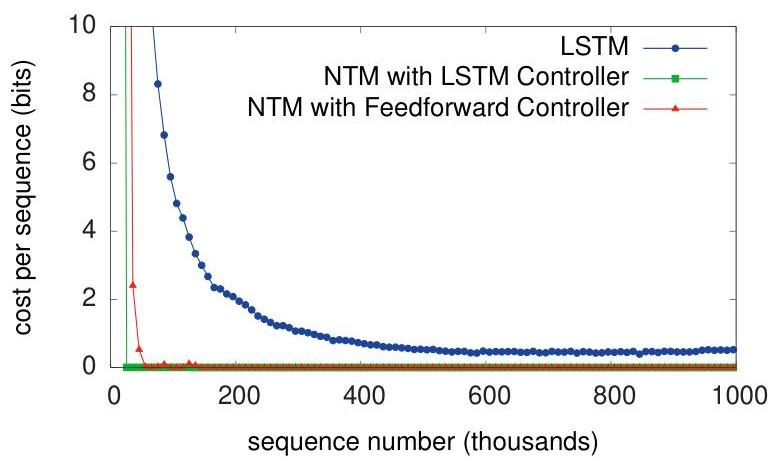
- NTM outperforms LSTM on all five algorithmic tasks (copy, repeat copy, associative recall, dynamic N-grams, and priority sort): NTM converges faster and achieves near-zero error, while LSTM struggles especially as sequence length grows
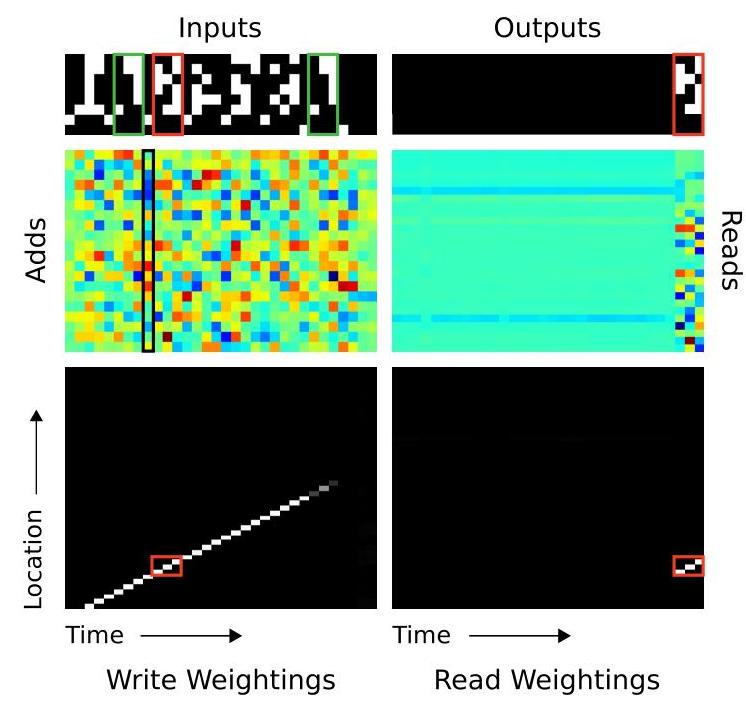
- Copy task: NTMs learned much faster than LSTMs and successfully copied sequences up to 6x longer than training examples (trained on lengths up to 20, generalized to length 120); learned behavior reveals an algorithmic approach -- writing inputs sequentially to memory, then returning to the beginning and reading sequentially, with write operations following a clear diagonal pattern
- Associative recall: NTM substantially outperformed LSTM, learning to create compressed representations and use content-based addressing to locate queried items followed by location-based shifts to retrieve associated values; LSTM error rate grows linearly with stored pairs
- Priority sorting: Required multiple parallel read/write heads; NTM successfully learned to sort by mapping priorities to specific memory locations during writing, then reading sequentially from sorted locations
- Learned addressing patterns are interpretable: visualizations of attention weights reveal sequential sweeps during copy and content-based lookups during recall, matching hand-designed algorithms
- Length generalization is robust: copy task accuracy remains high at 6x the training length (trained on lengths up to 20, tested on length 120), whereas LSTM degrades rapidly beyond training lengths
- The LSTM controller variant outperforms the feedforward controller, suggesting that maintaining internal state complements external memory
Limitations & Open Questions
- Soft attention over all N memory slots is O(N) per step, limiting scalability to very large memories (thousands of slots become prohibitively expensive)
- Training is sensitive to initialization and hyperparameters; convergence can be fragile on more complex tasks, and curriculum learning (starting with short sequences) is often required
- The paper evaluates only on synthetic algorithmic benchmarks; transfer to realistic NLP or vision tasks was not demonstrated until later work (Differentiable Neural Computer applied to question answering and graph traversal)
The NTM concept proved highly influential, inspiring subsequent architectures like Differentiable Neural Computers and establishing the field of differentiable programming. The work also has cognitive science significance, offering a computational model capturing aspects of human working memory while remaining trainable through gradient descent.
Connections
- Machine Learning -- memory-augmented neural networks
- Neural Machine Translation By Jointly Learning To Align And Translate -- concurrent development of attention for sequence models
- Attention Is All You Need -- transformers generalized attention as the core computation
- Pointer Networks -- related use of attention for discrete selection