Neural Machine Translation by Jointly Learning to Align and Translate
Overview
This paper introduced the attention mechanism to deep learning, arguably the single most influential architectural innovation leading to modern transformers and LLMs. Before attention, encoder-decoder models compressed entire source sentences into a single fixed-size vector, creating an information bottleneck that severely degraded performance on long sequences. By allowing the decoder to "look back" at all encoder states with learned alignment weights, the paper improved BLEU scores by ~7 points on long sentences (>50 words) and provided interpretable alignment visualizations.
The core idea is elegant: at each decoding step, instead of relying on a single static context vector, compute a weighted combination of all encoder hidden states where the weights reflect how relevant each source position is to the current output position. These weights are learned end-to-end through backpropagation, jointly with the translation task itself. This eliminates the need for external alignment models used in statistical MT while producing linguistically plausible soft alignments.
The query-key-value pattern introduced here -- where a decoder state queries encoder states to produce a context-dependent representation -- became the foundation for "Attention Is All You Need" three years later. Nearly every modern neural architecture (transformers, LLMs, VLMs) traces its lineage to this paper's insight that dynamic, content-based information routing is more powerful than fixed-topology information flow.
Key Contributions
- Soft attention / alignment model: At each decoder step t, compute alignment score e(t,i) = a(s_{t-1}, h_i) between decoder state s_{t-1} and each encoder state h_i, normalize via softmax to get attention weights alpha(t,i), then compute context vector c_t = sum(alpha(t,i) * h_i)
- Bidirectional encoder: A bidirectional GRU produces forward and backward hidden states concatenated as h_i = [h_forward_i; h_backward_i], giving each position context from the entire source sentence
- Dynamic context vectors: Each decoder timestep receives a different context vector c_t, replacing the static final encoder state used in prior seq2seq models
- End-to-end alignment learning: Alignment is learned jointly with translation through backpropagation, eliminating the need for external alignment models used in statistical MT
Architecture / Method
Source: x_1, x_2, ..., x_T
│
┌───────────────▼────────────────┐
│ Bidirectional GRU Encoder │
│ ┌──►h1──►h2──►h3──►h4──► │
│ │ forward │
│ x1 x2 x3 x4 │
│ │ backward │
│ └◄──h1◄──h2◄──h3◄──h4◄── │
│ │
│ h_i = [h_fwd_i ; h_bwd_i] │
└───────────┬────────────────────┘
│ h_1..h_T (annotations)
│
┌────────────────▼────────────────────┐
│ Attention Layer │
│ │
│ e(t,i) = v^T tanh(W_s·s_{t-1} │
│ + W_h·h_i) │
│ α(t,i) = softmax(e(t,:)) │
│ c_t = Σ α(t,i)·h_i │
└────────────────┬────────────────────┘
│ c_t (context vector)
│
┌───────────▼────────────────────┐
│ GRU Decoder │
│ s_t = GRU(s_{t-1}, [y_{t-1};c_t])│
│ P(y_t) = softmax(W_o·[s_t;c_t;y_{t-1}])│
└───────────┬────────────────────┘
│
▼
Target: y_1, y_2, ..., y_T'
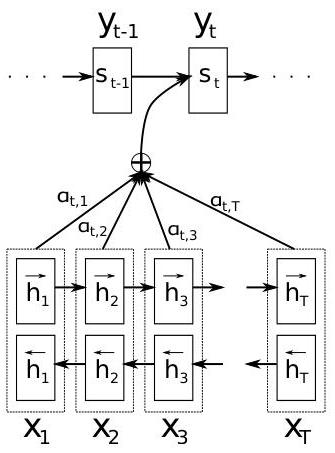
The encoder is a bidirectional GRU that processes the source sentence in both forward and reverse directions. For each source position i, the encoder produces an annotation h_i by concatenating the forward hidden state (capturing left context) and backward hidden state (capturing right context): h_i = [h_forward_i; h_backward_i].
The decoder is a unidirectional GRU that generates one target word at a time. At each step t, the decoder computes: 1. Alignment scores: e(t,i) = v^T * tanh(W_s * s_{t-1} + W_h * h_i) for each source position i, where s_{t-1} is the previous decoder hidden state 2. Attention weights: alpha(t,i) = softmax(e(t,:)), normalizing scores to a probability distribution over source positions 3. Context vector: c_t = sum_i alpha(t,i) * h_i, a weighted combination of encoder states 4. Decoder update: s_t = GRU(s_{t-1}, [y_{t-1}; c_t]), incorporating both the previous output and the attention-derived context 5. Output prediction: P(y_t | y_{<t}, x) = softmax(W_o * [s_t; c_t; y_{t-1}])
The alignment function a(s, h) is a single-layer feedforward network (additive attention), trained jointly with all other parameters through standard backpropagation. No pre-computed alignments or external alignment tools are needed.
Training uses standard maximum likelihood on parallel corpora (WMT'14 English-French), with sentences of up to 50 words. The model has ~36M parameters total.
Results
| Model | BLEU (all) | BLEU (known words) |
|---|---|---|
| RNNsearch-50 | 26.75 | 34.16 |
| RNNsearch-50 (extended training) | 28.45 | 36.15 |
| RNNencdec-50 | 17.82 | 21.97 |
| Moses (SMT) | 33.30 | 35.63 |
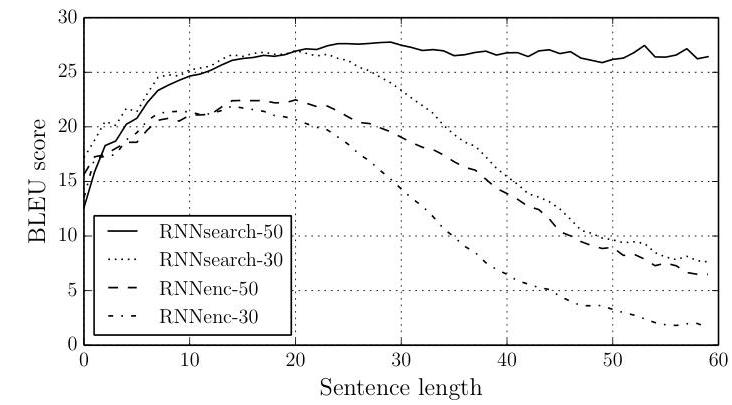
- Attention eliminates length degradation: Standard encoder-decoder BLEU drops sharply for sentences >20 words; the attention model (RNNsearch-50) maintains consistent performance even for sentences over 50 words long
- Quantitative gains: RNNsearch-50 achieved 26.75 BLEU on the standard test set (28.45 with extended training) vs. RNNencdec-50's 17.82 BLEU -- a dramatic improvement. Moses scored 33.30 BLEU overall; however, when excluding out-of-vocabulary effects, RNNsearch-50 reached 34.16 BLEU and the extended-training model (RNNsearch-50*) reached 36.15 BLEU vs. Moses SMT's 35.63 BLEU, surpassing phrase-based statistical MT on known-word sentences
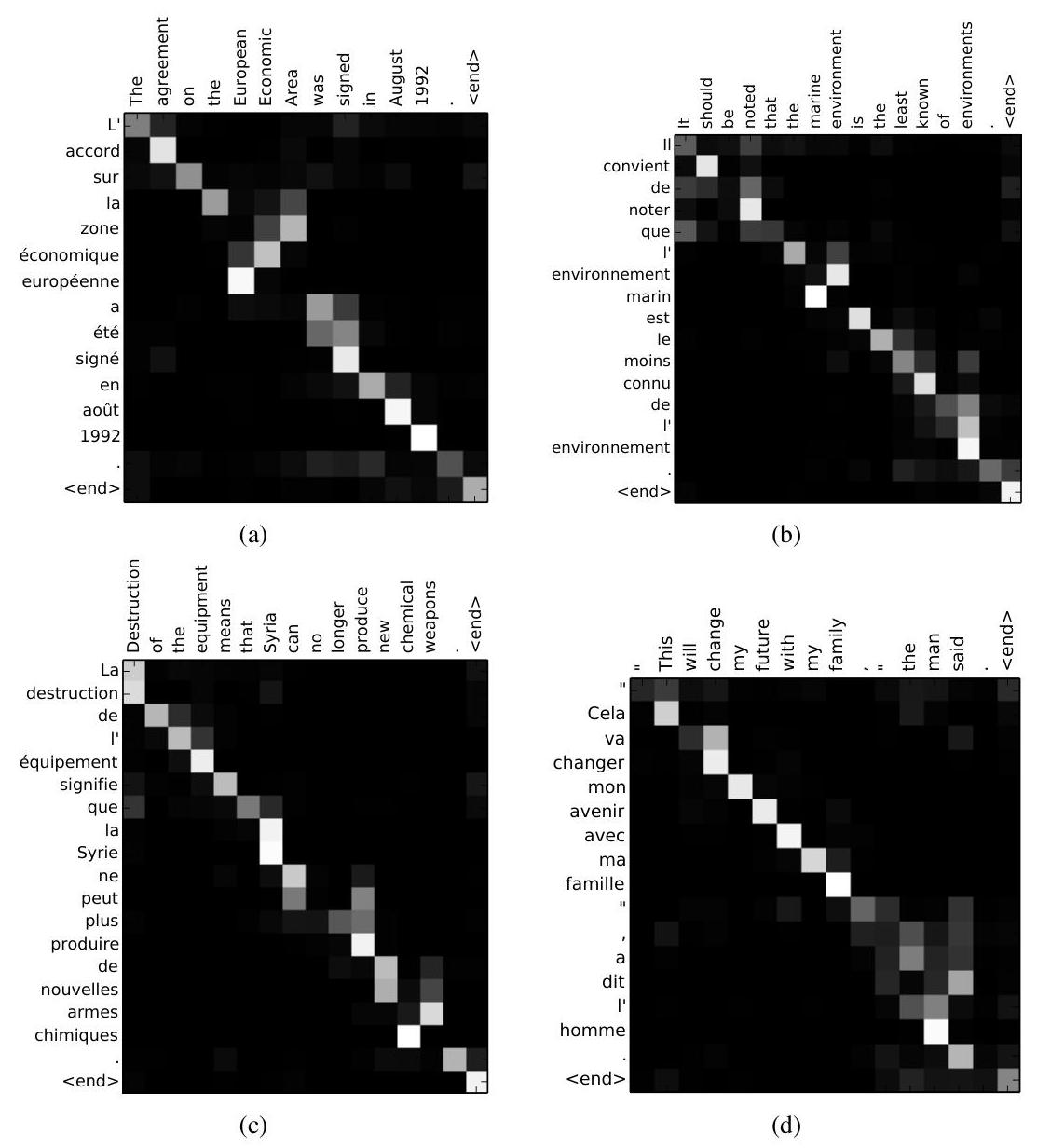
- Learned alignments are linguistically plausible: Visualization of attention weight heatmaps shows strong diagonal patterns for largely monotonic alignments, with off-diagonal patterns revealing non-monotonic reordering when necessary (e.g., translating "European Economic Area" to "zone economique europeenne" demonstrates correct French word reordering). The soft approach handles phrases of different lengths without forcing one-to-one mappings
- Architecture details: 1000 hidden units in encoder and decoder, 620-dimensional word embeddings, minibatch SGD with Adadelta adaptive learning rates, gradient clipping for exploding gradient handling, trained on a 348M word subset of the WMT'14 corpora with 30,000 word vocabulary per language
- The model handles rare words better than the fixed-vocabulary baseline because attention can "copy" information from specific source positions rather than relying on the fixed-length bottleneck
Limitations & Open Questions
- The additive attention score a(s, h) = v^T * tanh(W_s * s + W_h * h) is O(n) per decoder step, creating a quadratic bottleneck for long sequences (later replaced by more efficient dot-product attention in transformers)
- The sequential nature of the GRU encoder/decoder prevents parallelization, limiting training speed on long sequences -- a limitation that motivated the fully attention-based Transformer
- Attention is computed over all source positions uniformly with no mechanism for hard attention or sparse selection, which wastes computation when only a few source positions are relevant
Connections
- Machine Learning -- foundational attention mechanism
- Attention Is All You Need -- Transformer architecture built on this attention concept
- Neural Turing Machines -- concurrent work using attention for memory access
- Pointer Networks -- repurposes attention as output mechanism