Overview
This paper by Samy Bengio, Oriol Vinyals, and Manjunath Kudlur challenges a core assumption in sequence modeling: that the order of input and output data is merely a preprocessing detail. While probability theory suggests ordering is irrelevant (a joint distribution is the same regardless of factorization order), the practical reality is that neural network training is highly sensitive to the ordering imposed on data. The authors provide empirical evidence across multiple tasks that reordering inputs and outputs meaningfully changes final performance.
The paper addresses two distinct problems. First, when the input is naturally a set (unordered collection), feeding it to an RNN encoder introduces artificial position dependence -- the paper shows that the choice of input ordering can change translation BLEU by 5 points or convex hull accuracy by up to 10%. To handle this, the authors propose the Read-Process-Write (RPW) architecture: a permutation-invariant encoder that uses iterative attention over the input set without imposing a sequence order.
Second, when the output is a set (no canonical ordering), the model must pick one of many equivalent linearizations to train on. The paper introduces a training objective that samples orderings in proportion to their current probability, allowing the model to discover good output orderings dynamically rather than committing to a fixed arbitrary linearization.
This work is foundational for understanding how to apply sequence models to inherently unordered data, a problem that recurs in point clouds, graph neural networks, and set-based reasoning.
Key Contributions
- Order matters empirically: Demonstrates that input/output ordering significantly affects performance across translation, parsing, language modeling, and sorting tasks -- the model cannot easily learn to be invariant to ordering on its own
- Read-Process-Write architecture: A modular three-phase framework for encoding input sets in a permutation-invariant way: (1) Read -- embed each set element into memory, (2) Process -- apply iterative attention over memory without ordering assumptions, (3) Write -- generate output sequence via a pointer network
- Dynamic output ordering: For tasks with unstructured outputs, introduces a training loss that samples from possible orderings proportionally to their model probability, allowing the model to discover a good output linearization
- Input ordering ablations: Systematic comparison of random, fixed-random, sorted, and learned input orderings, showing sorted/learned orderings consistently outperform random across tasks
- Convex hull and joint probability estimation: Demonstrates the RPW framework on geometric (convex hull) and probabilistic (joint distribution estimation) tasks, not just sorting
Architecture / Method
Read-Process-Write Architecture
───────────────────────────────
Input Set: {x₁, x₂, ..., xₙ} (unordered)
│
┌──────── ▼ ────────┐
│ READ Phase │
│ ┌────┐ ┌────┐ │
│ │Emb │ │Emb │... │ Embed each element
│ └─┬──┘ └─┬──┘ │ into memory vectors
│ ▼ ▼ │
│ {m₁, m₂, ..., mₙ} Memory (unordered)
└────────┬──────────┘
│
┌────────▼──────────┐
│ PROCESS Phase │
│ │
│ for t = 1..P: │ P rounds of attention
│ rₜ = Σ αᵢ·mᵢ │ (no ordering assumption)
│ qₜ = LSTM( │
│ qₜ₋₁, rₜ) │
│ │
└────────┬──────────┘
│ processed state q_P
┌────────▼──────────┐
│ WRITE Phase │
│ │
│ Pointer network │ Generate output sequence
│ attends over │ by selecting from inputs
│ memory {mᵢ} │ (for sorting/selection)
│ │
└────────┬──────────┘
▼
Output: (y₁, y₂, ..., yₘ)
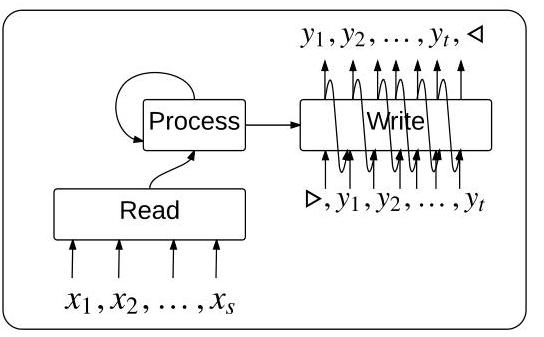
The Read phase embeds each element of the input set into a memory vector. Crucially, these vectors are stored as an unordered set -- no positional index is attached.
The Process phase runs an LSTM for P steps that iteratively attends over all memory vectors: q_t = LSTM(q_{t-1}, r_t) where r_t = sum_i alpha_i * m_i is an attention-weighted readout. This enables the model to perform P "thinking steps" over the set without any ordering assumption. P is a hyperparameter controlling the amount of computation.
The Write phase uses a pointer network decoder that attends over the memory vectors to generate the output sequence. For sorting and convex hull tasks this involves selecting input elements in the correct order; for other tasks it can generate tokens freely.
For output sets, the training objective samples a permutation pi proportionally to exp(log p(y_pi)) and trains the model to predict that ordering. This is more tractable than summing over all n! permutations and allows the model to reinforce orderings it already finds plausible.
Results
| Task | Model / Ordering | Metric | Value |
|---|---|---|---|
| Sorting (N=5) | RPW | Accuracy | 94% |
| Sorting (N=5) | Pointer Network | Accuracy | 90% |
| Sorting (N=10) | RPW | Accuracy | 57% |
| Sorting (N=10) | Pointer Network | Accuracy | 28% |
| Sorting (N=15) | RPW | Accuracy | 10% |
| Sorting (N=15) | Pointer Network | Accuracy | 4% |
| Language Modeling | Dynamic ordering | Perplexity | 225 |
| Language Modeling | Fixed arbitrary ordering | Perplexity | 280 |
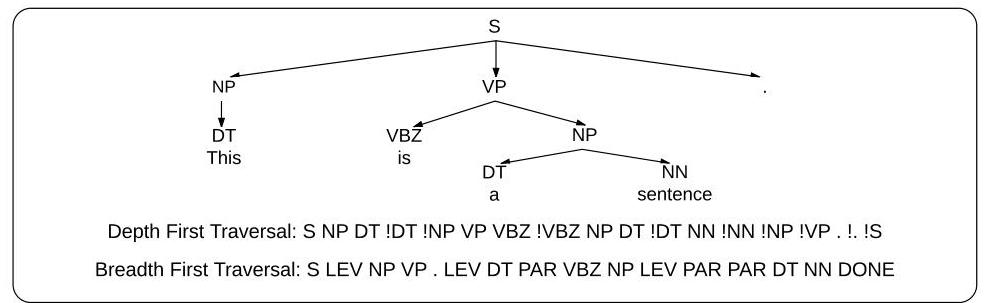
| Parsing | Depth-first traversal | F1 | 89.5% |
| Parsing | Breadth-first traversal | F1 | 81.5% |
| Translation | Reversed input order | BLEU | +5.0 pts vs. natural order |
| Convex hull | Optimal input order | Accuracy | Up to +10% absolute |
- The RPW architecture consistently outperforms Pointer Networks on sorting tasks, with larger gains at larger set sizes (N=10: 57% vs. 28%)
- On language modeling, the dynamic ordering strategy matches the best possible fixed ordering (perplexity 225) without needing to know which ordering is best in advance
- Depth-first vs. breadth-first traversal order for parsing outputs makes a large difference (89.5% vs. 81.5% F1), confirming that output ordering is a significant modeling choice
- Machine translation BLEU improved 5 points simply by reversing the input sentence order, showing that ordering effects are real even in production-scale seq2seq
Limitations & Open Questions
- The RPW architecture still requires choosing P (number of processing steps) as a hyperparameter; too few steps under-processes complex sets, too many adds unnecessary compute
- The dynamic output ordering strategy does not guarantee finding the globally optimal ordering -- it samples proportionally to current model probability, so a poor initialization may not recover
- The approach does not directly generalize to cases where inputs or outputs are graphs rather than sets -- later work (GNNs, Set Transformer) addresses more structured inputs
Connections
- Machine Learning -- set processing with sequence models
- Pointer Networks -- pointer mechanism used in the write phase
- Attention Is All You Need -- transformers address set processing through self-attention
- Neural Message Passing For Quantum Chemistry -- GNNs as an alternative approach to unordered inputs